A presentation at Apache Kafka NYC Meetup in in New York, NY, USA by Viktor Gamov

Crossing the Streams: Rethinking Stream Processing with Kafka Streams and KSQL @gamussa #NYCKafka @confluentinc
https://twitter.com/gAmUssA/status/1048258981595111424
Streaming is the toolset for dealing with events as they move! @gamussa #NYCKafka @confluentinc
@gamussa #NYCKafka @ @confluentinc
@gamussa #NYCKafka @ @confluentinc
High Throughput Streaming platform @gamussa #NYCKafka @ @confluentinc
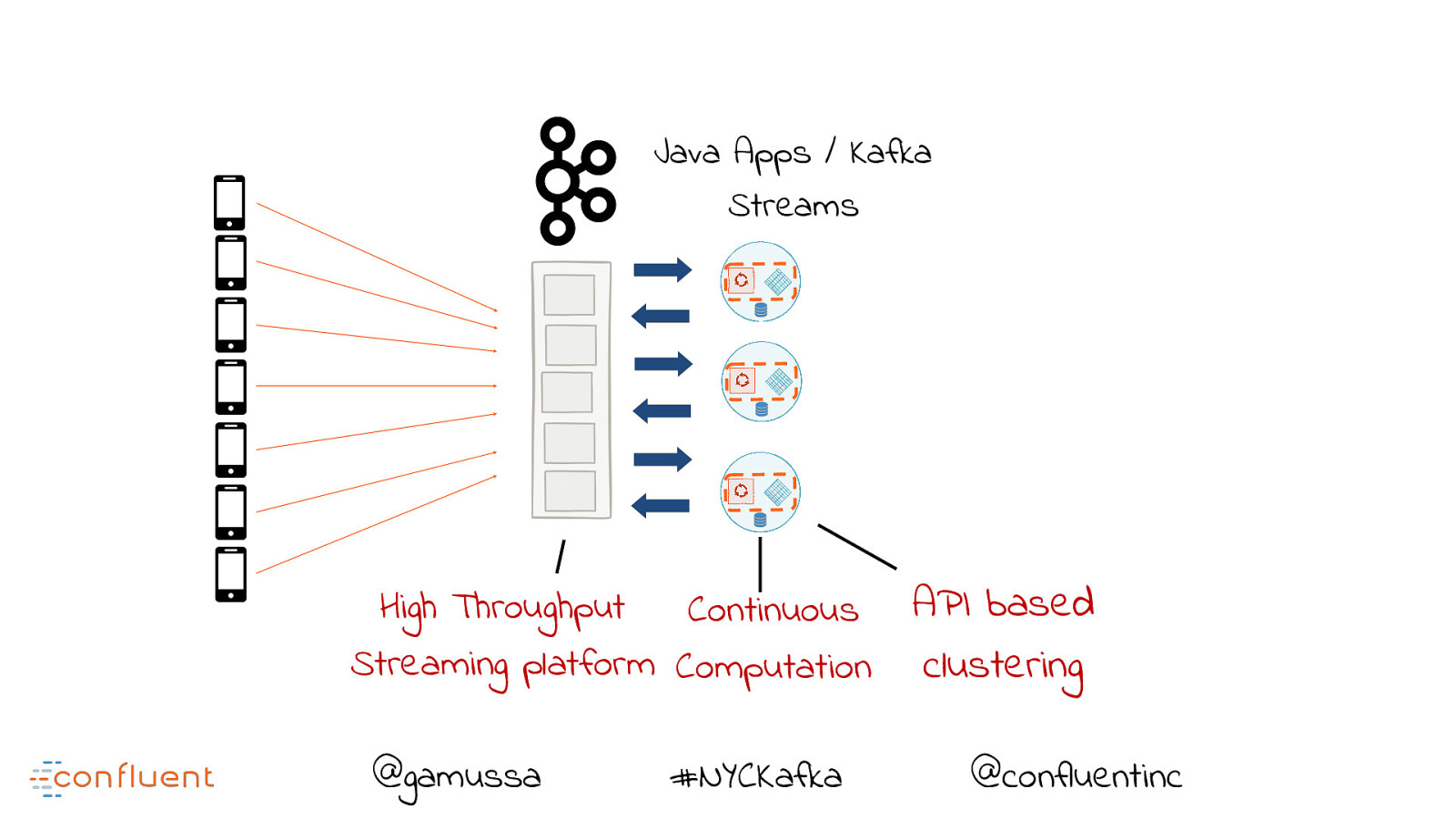
Java Apps / Kafka Streams High Throughput Continuous Streaming platform Computation @gamussa #NYCKafka @ API based clustering @confluentinc
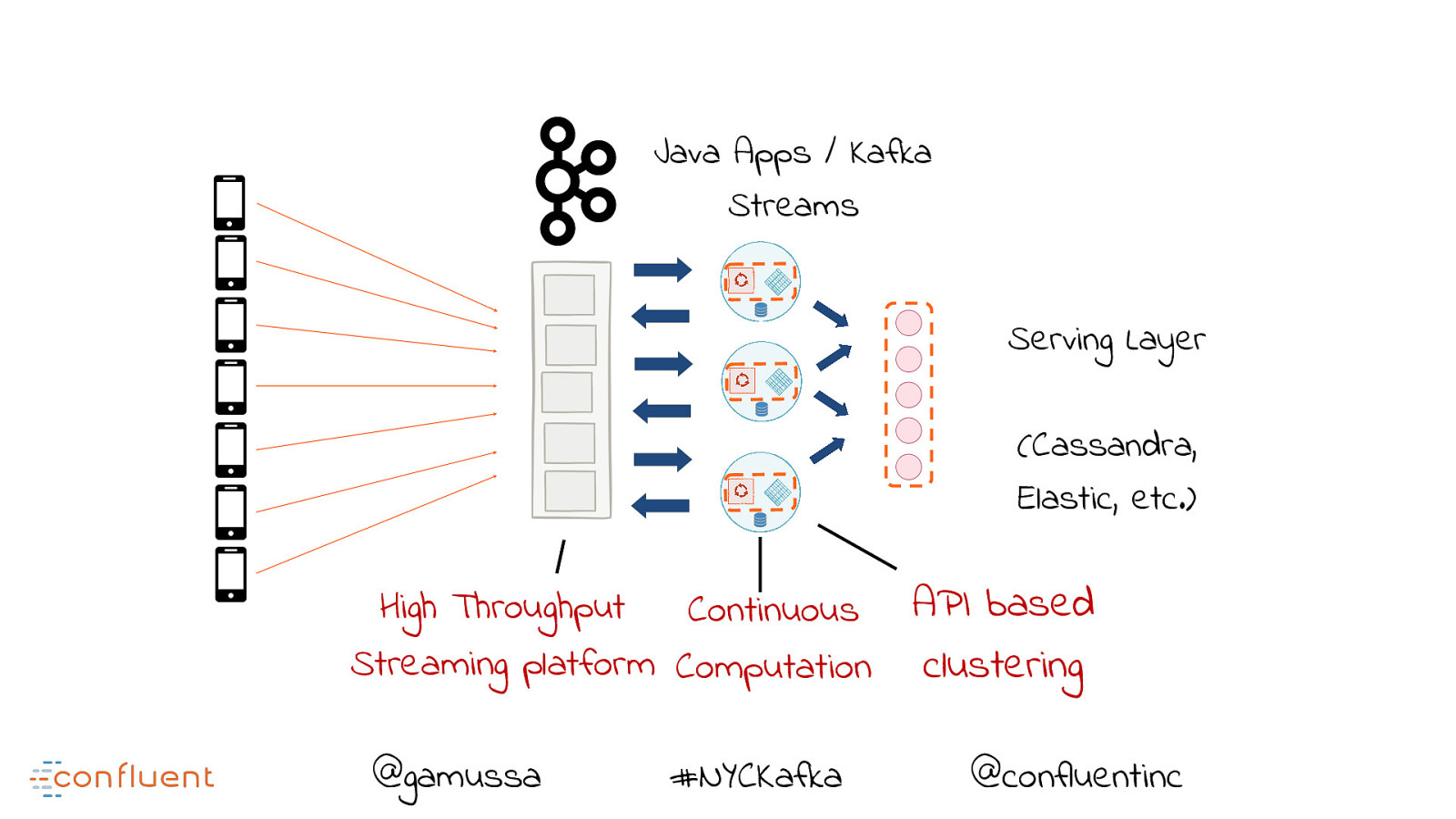
Java Apps / Kafka Streams Serving Layer (Cassandra, Elastic, etc.) High Throughput Continuous Streaming platform Computation @gamussa #NYCKafka @ API based clustering @confluentinc
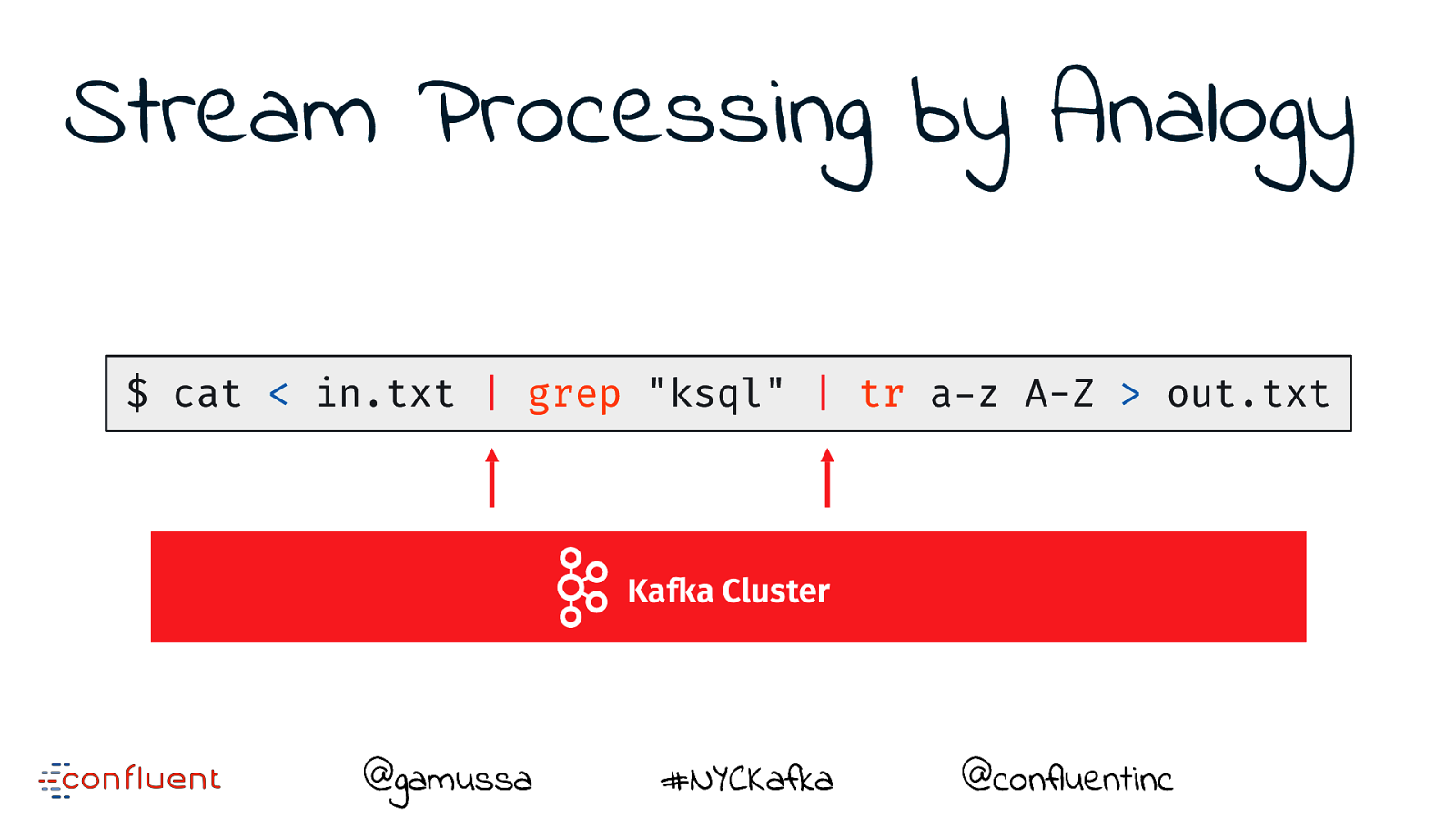
Stream Processing by Analogy $ cat < in.txt | grep "ksql" | tr a-z A-Z > out.txt @gamussa #NYCKafka @confluentinc
Stream Processing by Analogy $ cat < in.txt | grep "ksql" | tr a-z A-Z > out.txt Kafka Cluster @gamussa #NYCKafka @confluentinc
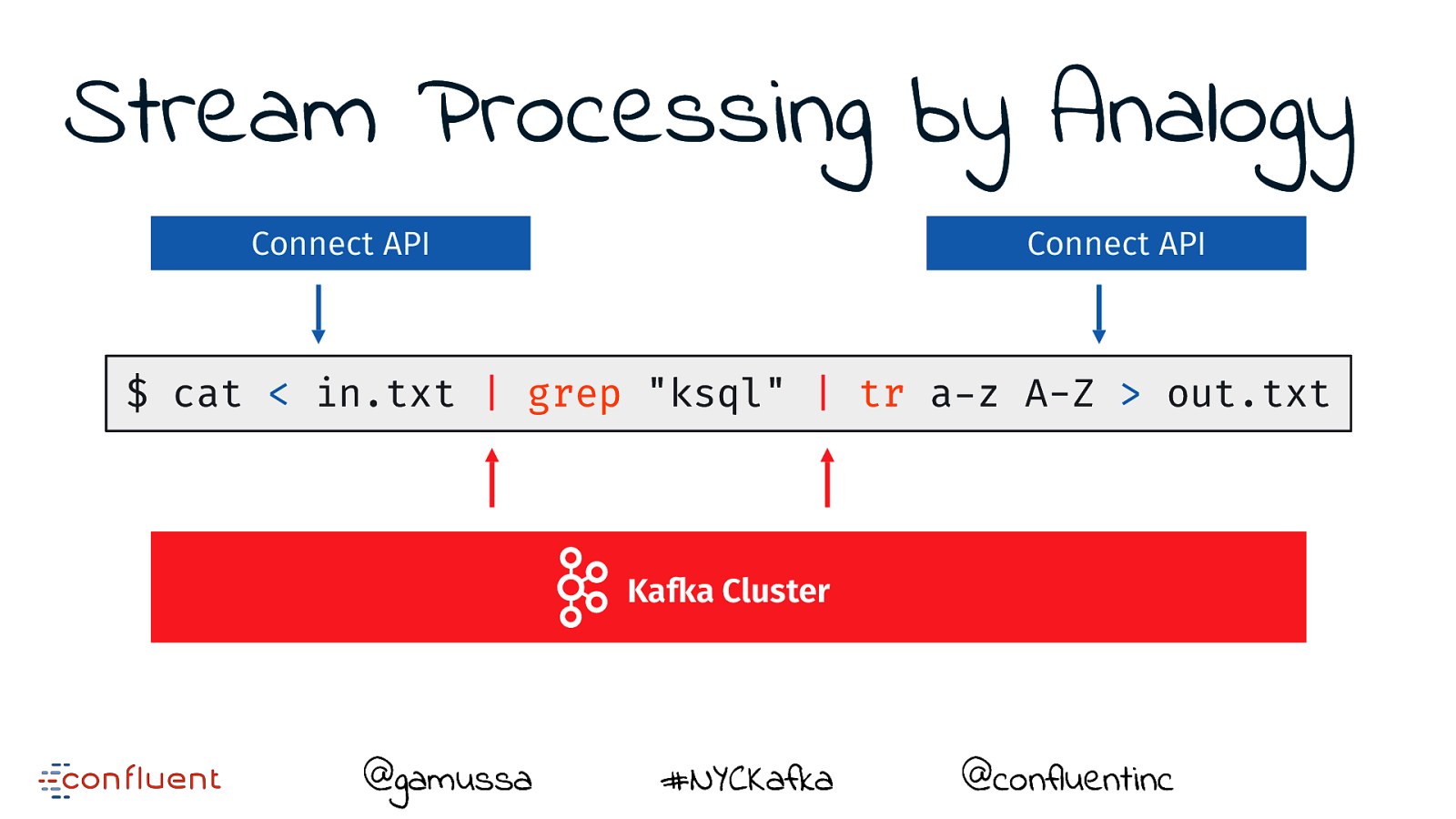
Stream Processing by Analogy Connect API Connect API $ cat < in.txt | grep "ksql" | tr a-z A-Z > out.txt Kafka Cluster @gamussa #NYCKafka @confluentinc
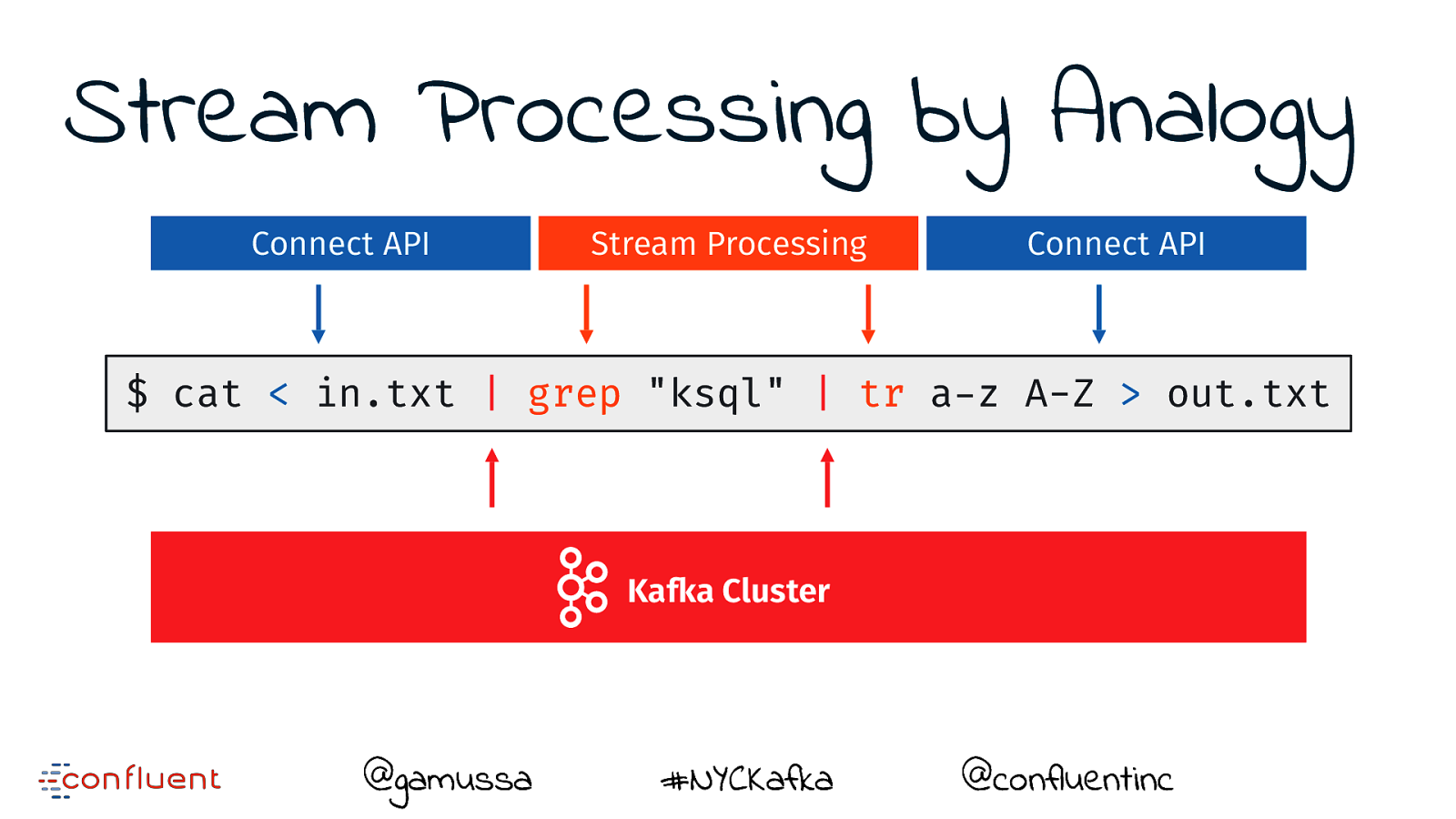
Stream Processing by Analogy Connect API Stream Processing Connect API $ cat < in.txt | grep "ksql" | tr a-z A-Z > out.txt Kafka Cluster @gamussa #NYCKafka @confluentinc
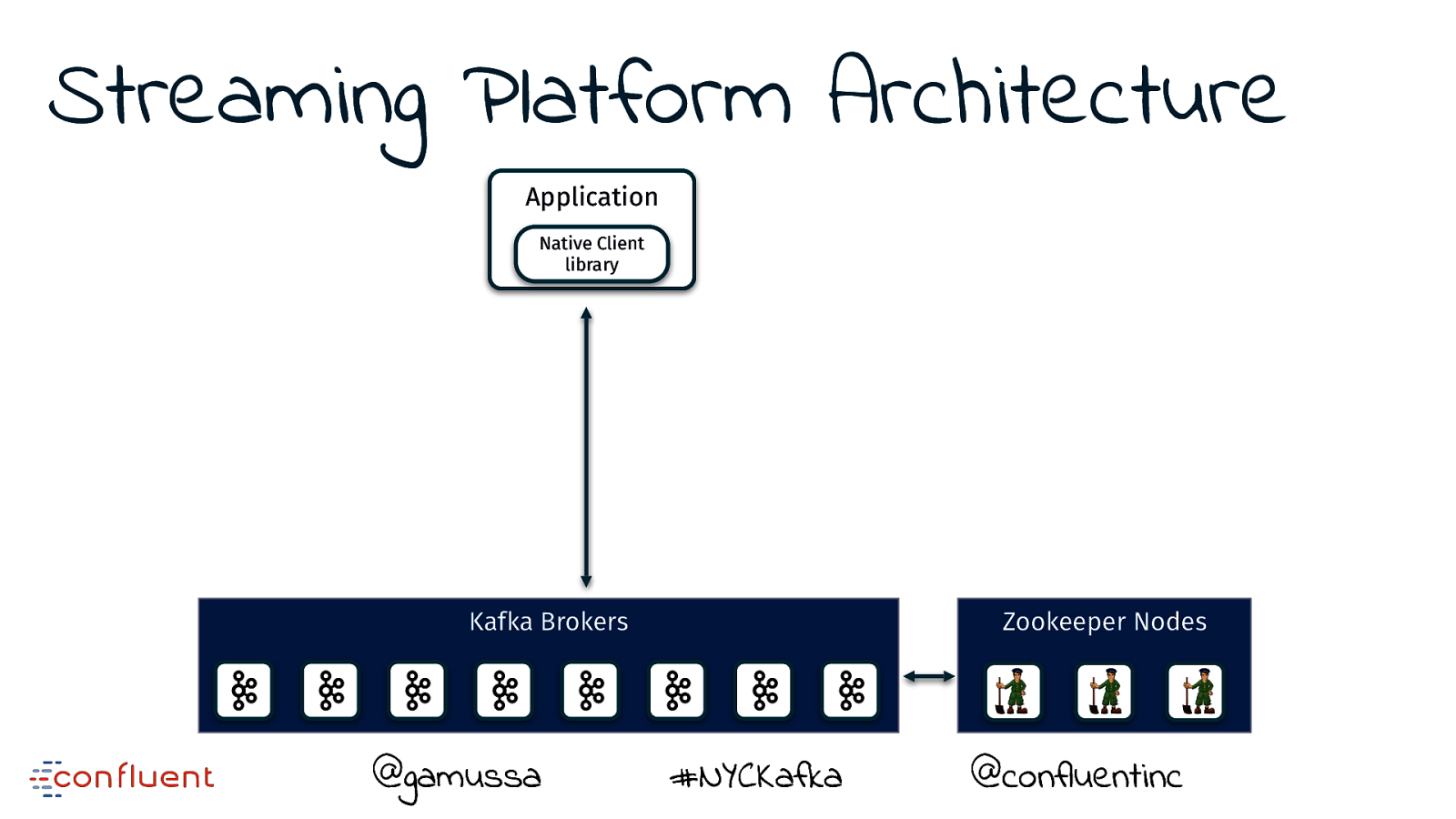
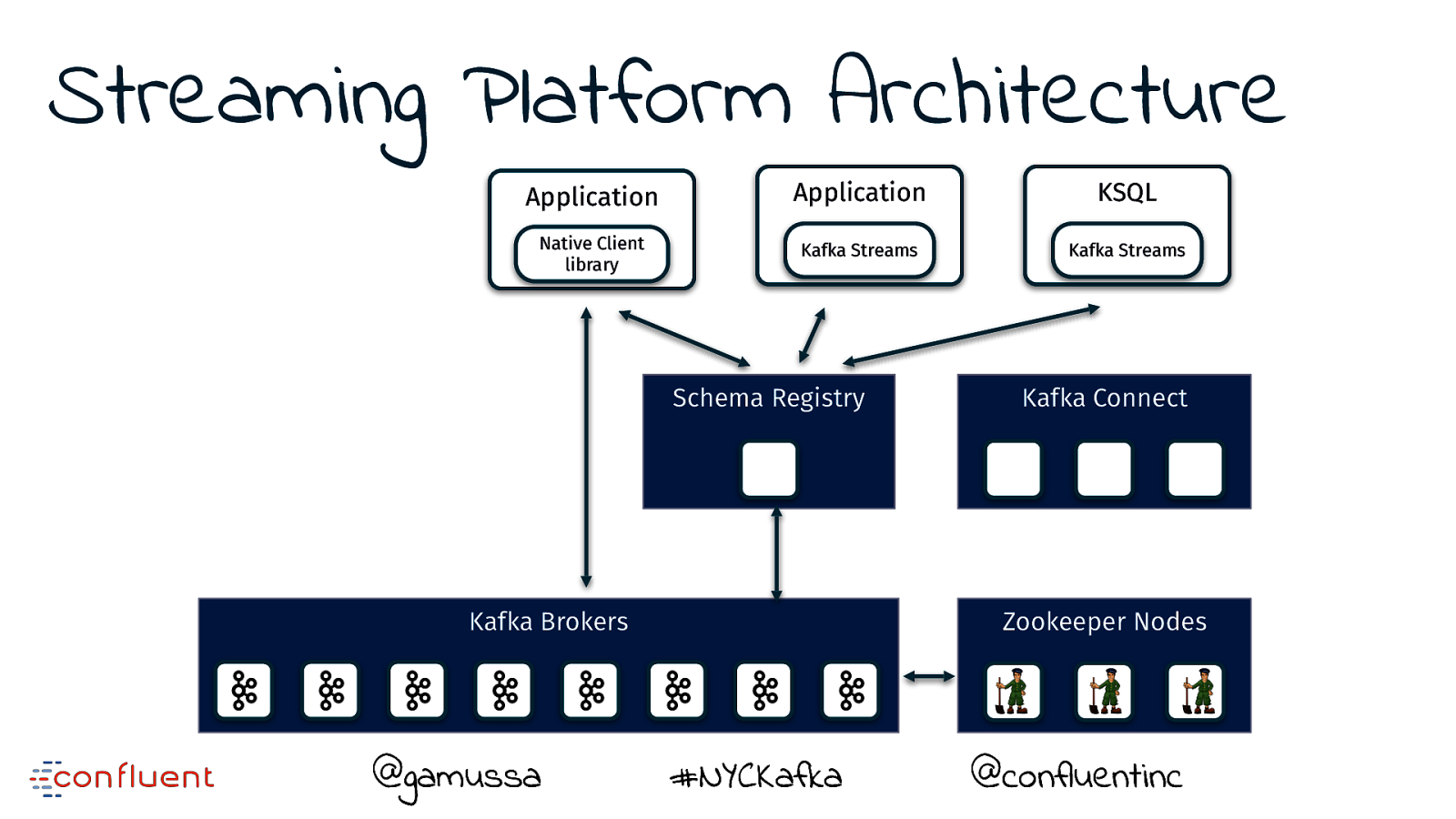
Streaming Platform Architecture @gamussa #NYCKafka @ @confluentinc
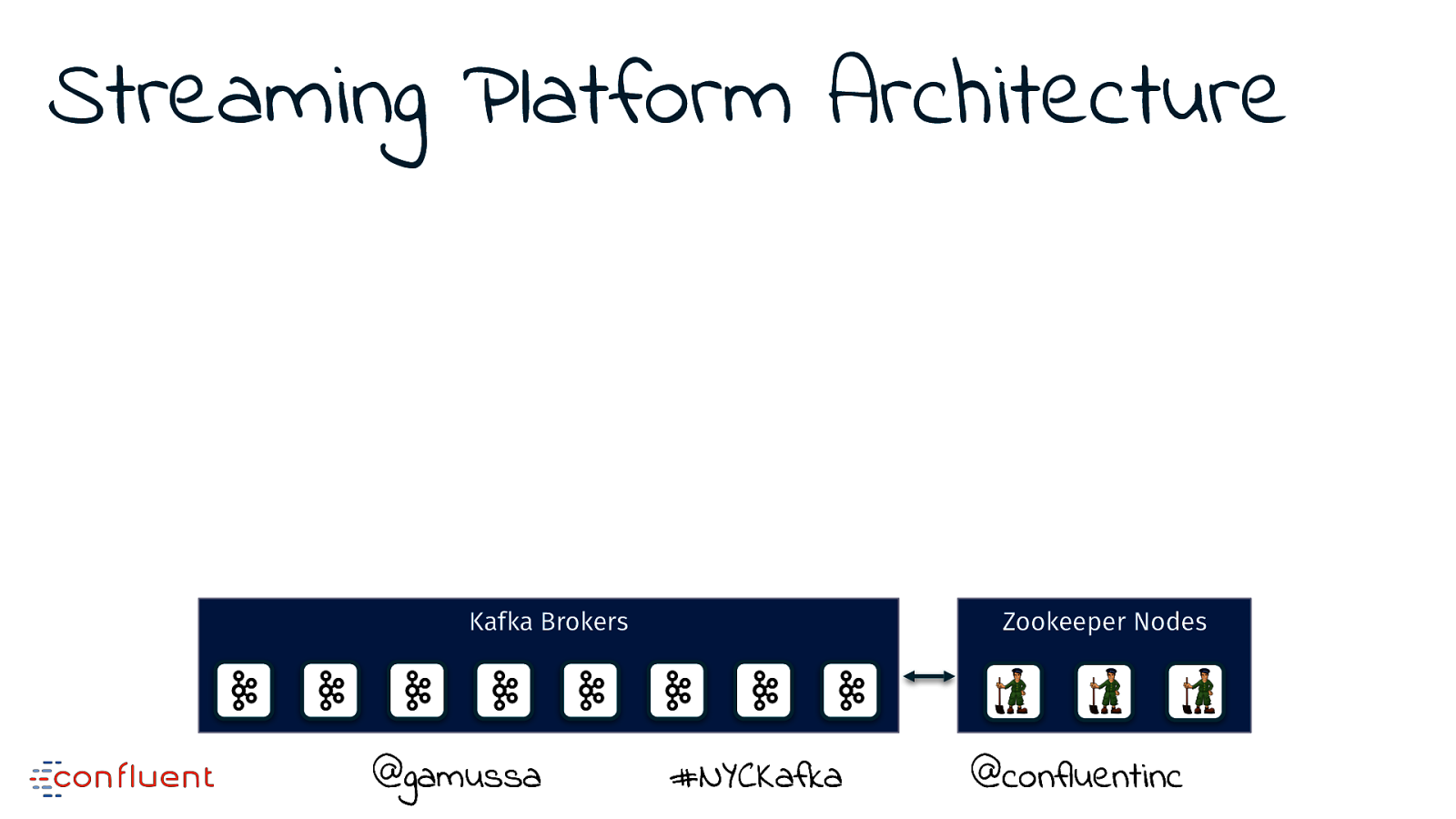
Streaming Platform Architecture Kafka Brokers @gamussa #NYCKafka @ @confluentinc
Streaming Platform Architecture Kafka Brokers @gamussa Zookeeper Nodes #NYCKafka @ @confluentinc
Streaming Platform Architecture Application Native Client library Kafka Brokers @gamussa Zookeeper Nodes #NYCKafka @ @confluentinc
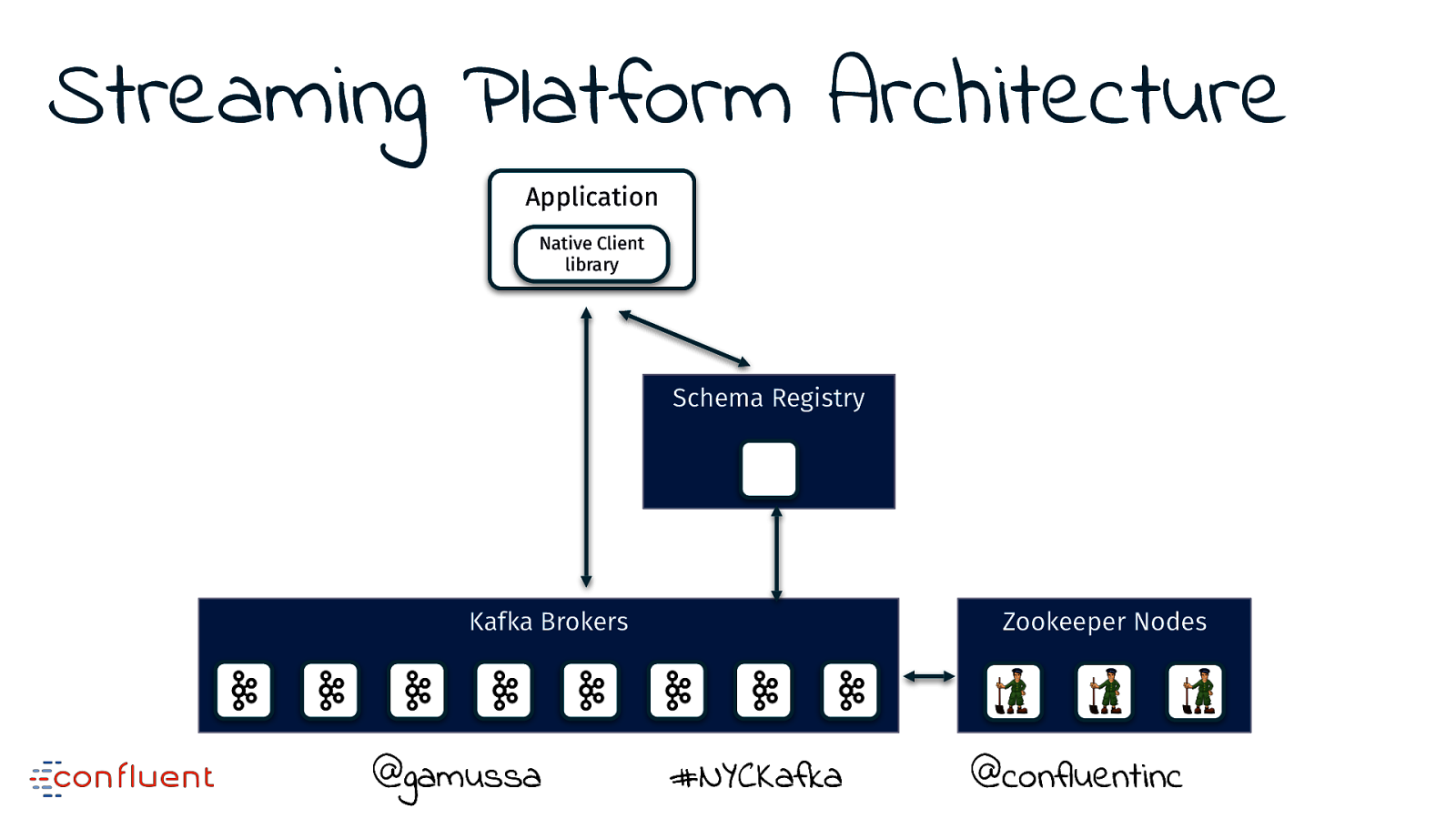
Streaming Platform Architecture Application Native Client library Schema Registry Kafka Brokers @gamussa Zookeeper Nodes #NYCKafka @ @confluentinc
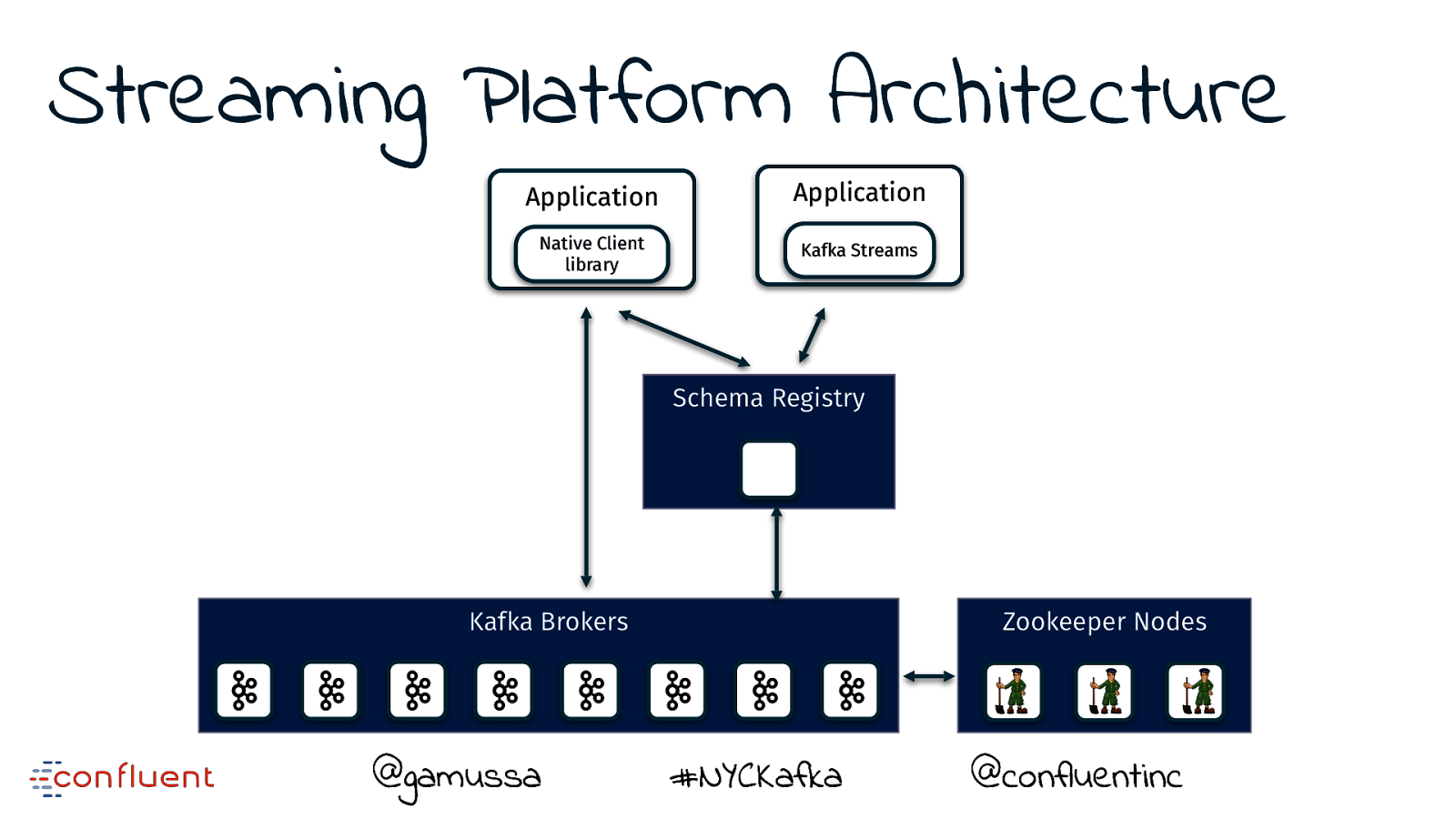
Streaming Platform Architecture Application Application Native Client library Kafka Streams Schema Registry Kafka Brokers @gamussa Zookeeper Nodes #NYCKafka @ @confluentinc
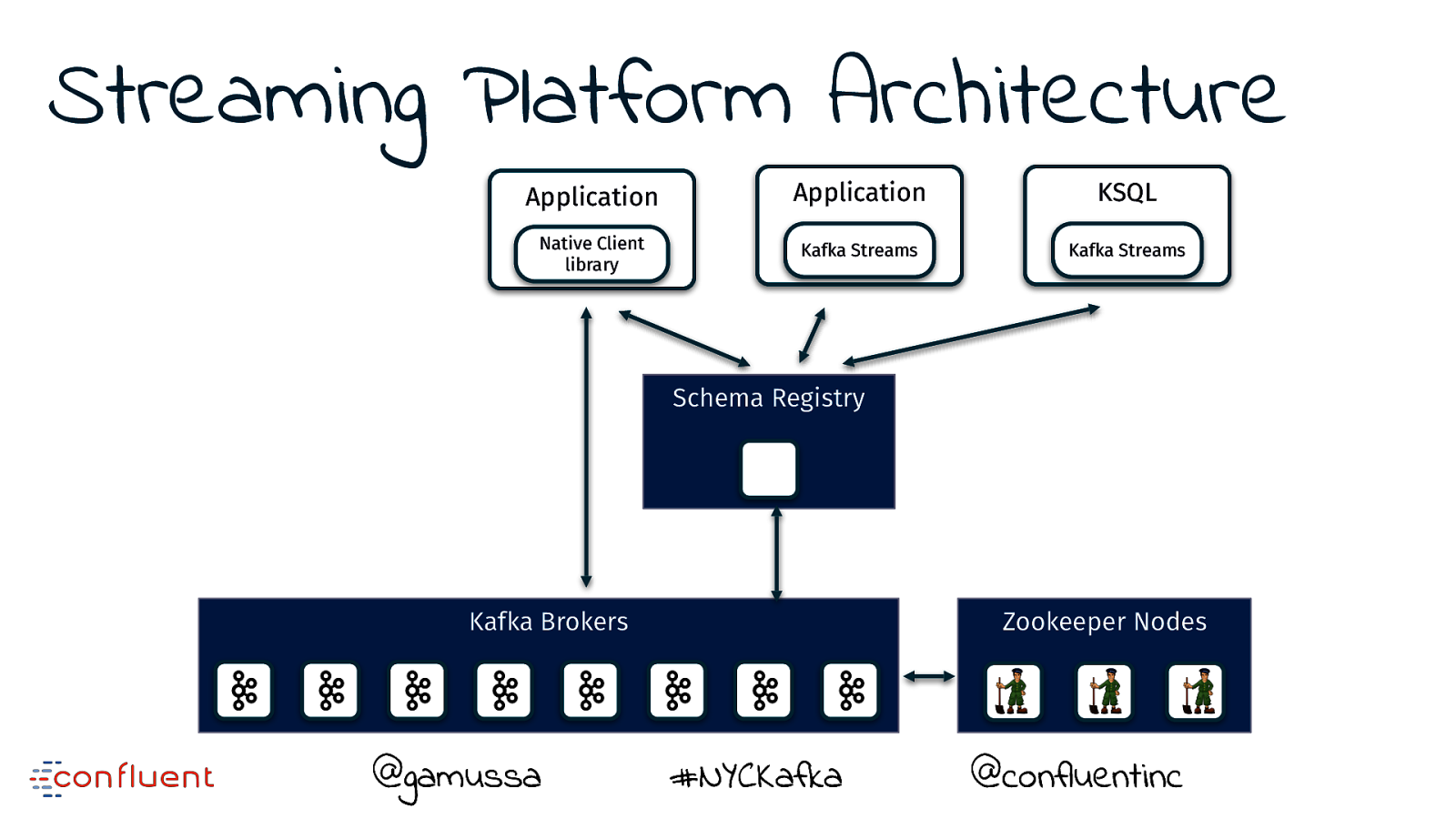
Streaming Platform Architecture Application Application KSQL Native Client library Kafka Streams Kafka Streams Schema Registry Kafka Brokers @gamussa Zookeeper Nodes #NYCKafka @ @confluentinc
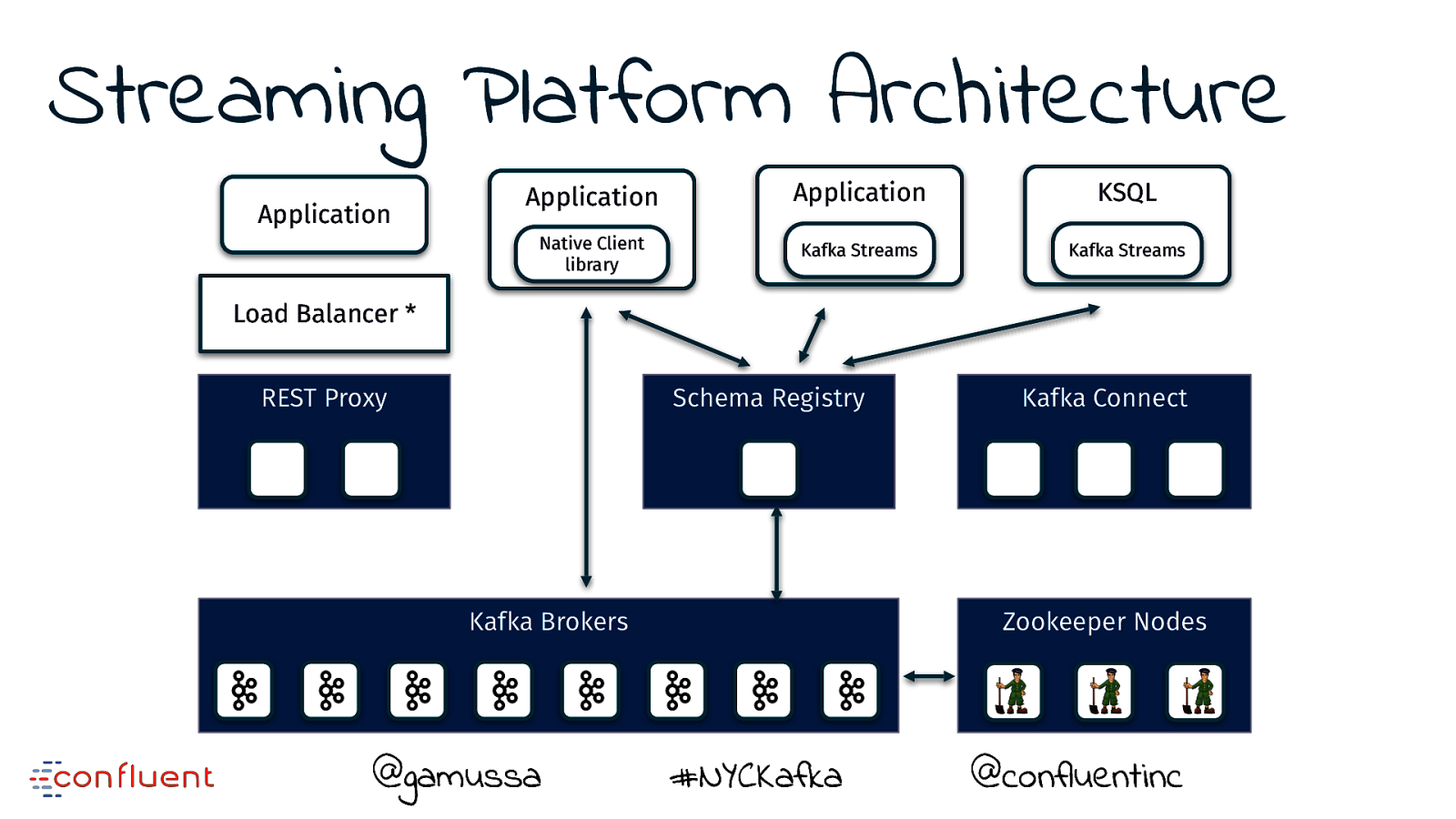
Streaming Platform Architecture Application Application KSQL Native Client library Kafka Streams Kafka Streams Schema Registry Kafka Brokers @gamussa Kafka Connect Zookeeper Nodes #NYCKafka @ @confluentinc
Streaming Platform Architecture Application Application Application KSQL Native Client library Kafka Streams Kafka Streams Load Balancer * REST Proxy Schema Registry Kafka Brokers @gamussa Kafka Connect Zookeeper Nodes #NYCKafka @ @confluentinc
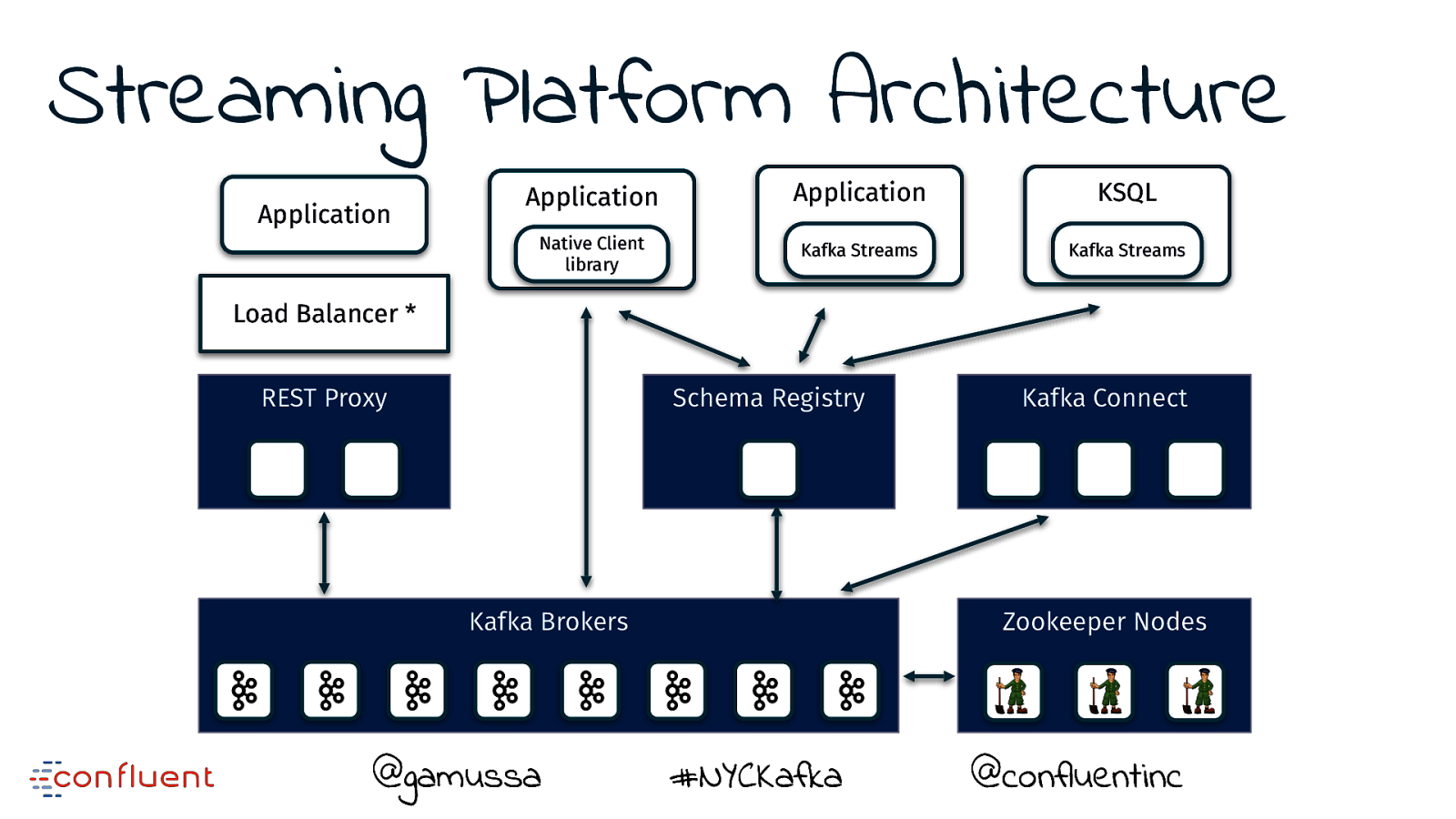
Streaming Platform Architecture Application Application Application KSQL Native Client library Kafka Streams Kafka Streams Load Balancer * REST Proxy Schema Registry Kafka Brokers @gamussa Kafka Connect Zookeeper Nodes #NYCKafka @ @confluentinc
https://twitter.com/monitoring_king/status/1048264580743479296
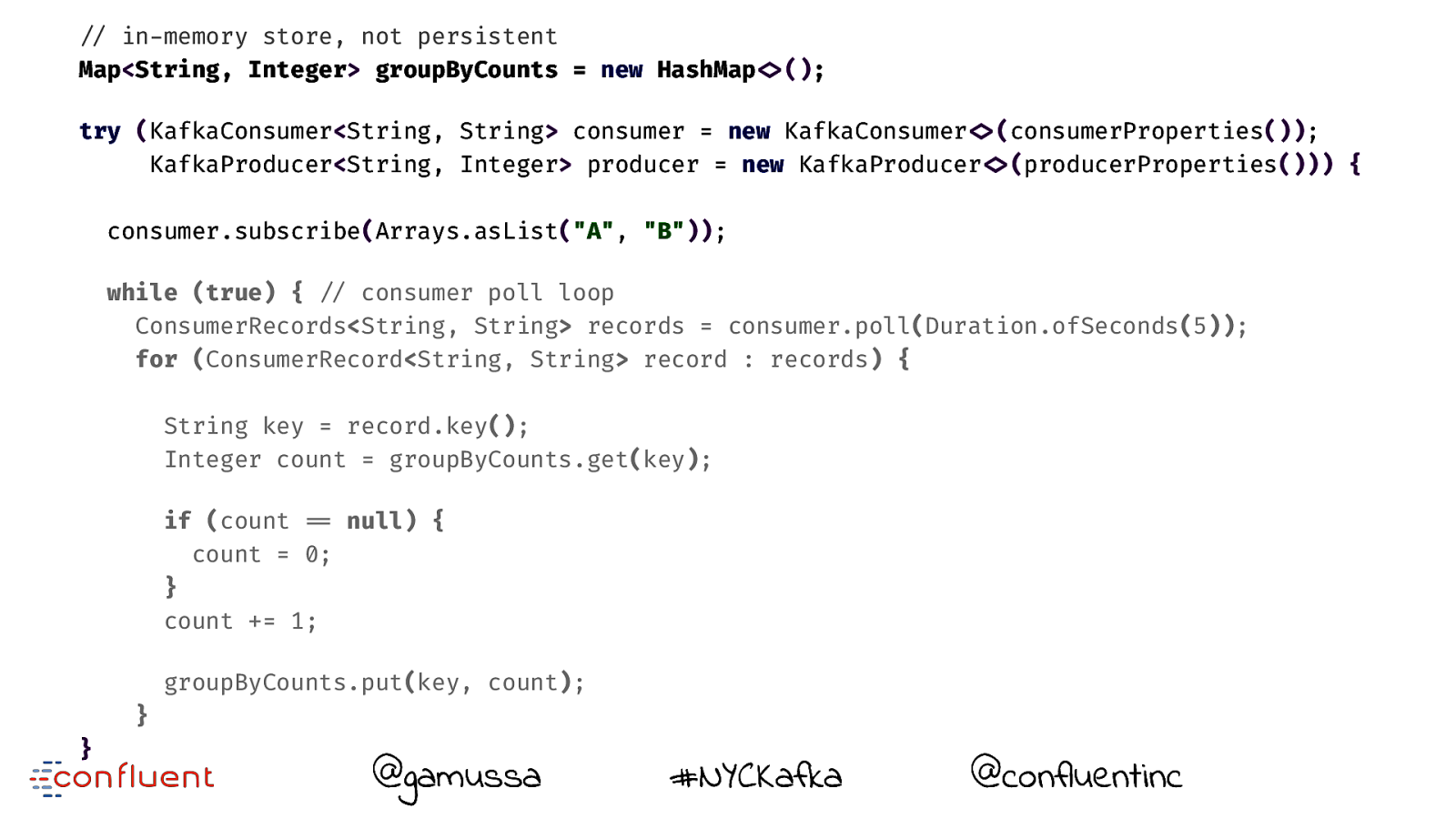
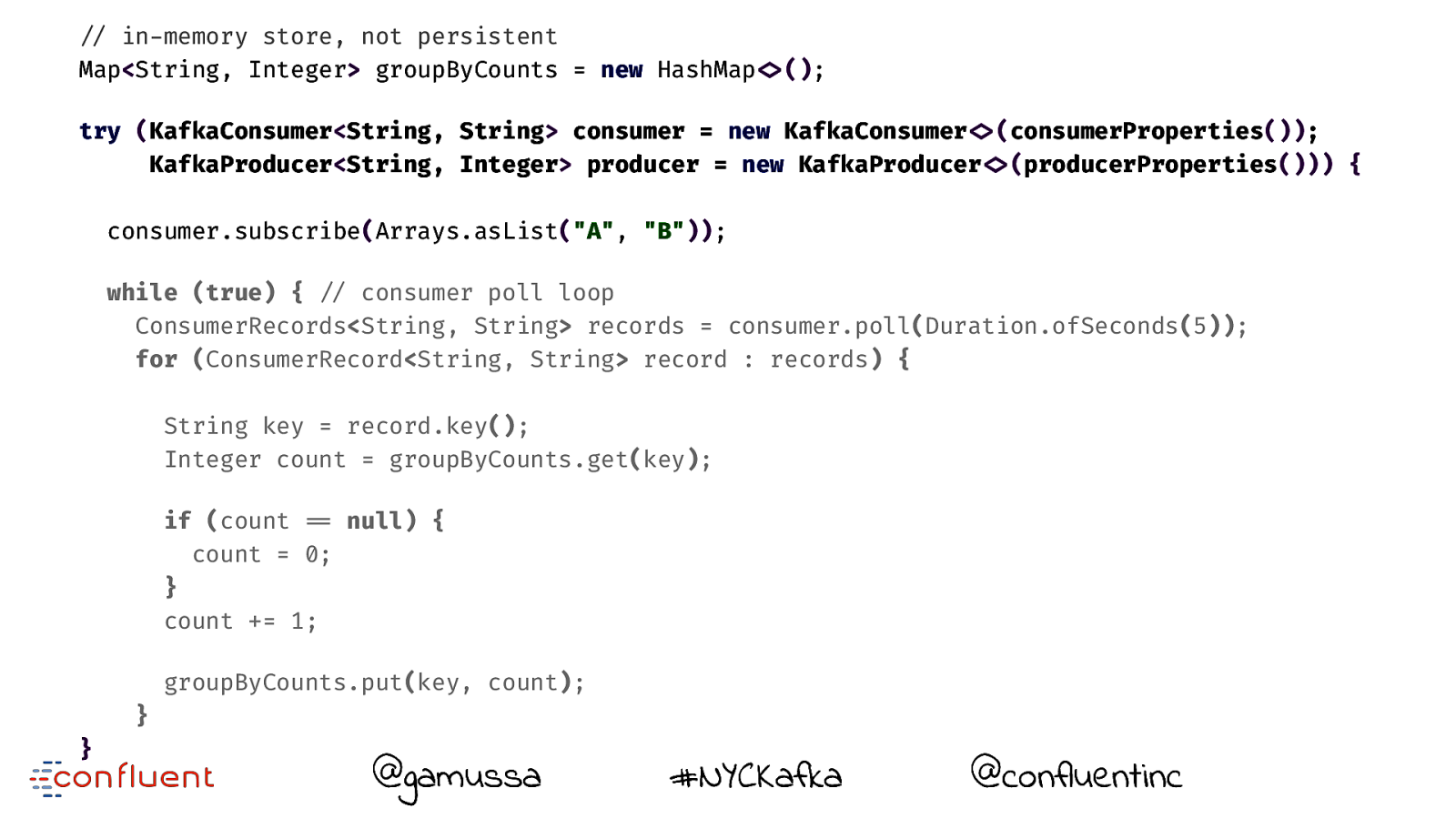
"// in-memory store, not persistent Map<String, Integer> groupByCounts = new HashMap!<>(); try (KafkaConsumer<String, String> consumer = new KafkaConsumer!<>(consumerProperties()); KafkaProducer<String, Integer> producer = new KafkaProducer!<>(producerProperties())) { consumer.subscribe(Arrays.asList("A", "B")); while (true) { "// consumer poll loop ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5)); for (ConsumerRecord<String, String> record : records) { String key = record.key(); Integer count = groupByCounts.get(key); if (count "== null) { count = 0; } count += 1; "// actually doing something useful groupByCounts.put(key, count); } if (counter"++ % sendInterval "== 0) { for (Map.Entry<String, Integer> groupedEntry : groupByCounts.entrySet()) { ProducerRecord<String, Integer> producerRecord = new ProducerRecord!<>("group-by-counts", groupedEntry.getKey(), groupedEntry.getValue()); producer.send(producerRecord); } consumer.commitSync(); } } } @gamussa #NYCKafka @ @confluentinc
"// in-memory store, not persistent Map<String, Integer> groupByCounts = new HashMap!<>(); try (KafkaConsumer<String, String> consumer = new KafkaConsumer!<>(consumerProperties()); KafkaProducer<String, Integer> producer = new KafkaProducer!<>(producerProperties())) { consumer.subscribe(Arrays.asList("A", "B")); while (true) { "// consumer poll loop ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5)); for (ConsumerRecord<String, String> record : records) { String key = record.key(); Integer count = groupByCounts.get(key); if (count "== null) { count = 0; } count += 1; groupByCounts.put(key, count); } } @gamussa #NYCKafka @ @confluentinc
"// in-memory store, not persistent Map<String, Integer> groupByCounts = new HashMap!<>(); try (KafkaConsumer<String, String> consumer = new KafkaConsumer!<>(consumerProperties()); KafkaProducer<String, Integer> producer = new KafkaProducer!<>(producerProperties())) { consumer.subscribe(Arrays.asList("A", "B")); while (true) { "// consumer poll loop ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5)); for (ConsumerRecord<String, String> record : records) { String key = record.key(); Integer count = groupByCounts.get(key); if (count "== null) { count = 0; } count += 1; groupByCounts.put(key, count); } } @gamussa #NYCKafka @ @confluentinc
"// in-memory store, not persistent Map<String, Integer> groupByCounts = new HashMap!<>(); try (KafkaConsumer<String, String> consumer = new KafkaConsumer!<>(consumerProperties()); KafkaProducer<String, Integer> producer = new KafkaProducer!<>(producerProperties())) { consumer.subscribe(Arrays.asList("A", "B")); while (true) { "// consumer poll loop ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5)); for (ConsumerRecord<String, String> record : records) { String key = record.key(); Integer count = groupByCounts.get(key); if (count "== null) { count = 0; } count += 1; groupByCounts.put(key, count); } } @gamussa #NYCKafka @ @confluentinc
"// in-memory store, not persistent Map<String, Integer> groupByCounts = new HashMap!<>(); try (KafkaConsumer<String, String> consumer = new KafkaConsumer!<>(consumerProperties()); KafkaProducer<String, Integer> producer = new KafkaProducer!<>(producerProperties())) { consumer.subscribe(Arrays.asList("A", "B")); while (true) { "// consumer poll loop ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5)); for (ConsumerRecord<String, String> record : records) { String key = record.key(); Integer count = groupByCounts.get(key); if (count "== null) { count = 0; } count += 1; groupByCounts.put(key, count); } } @gamussa #NYCKafka @ @confluentinc
while (true) { "// consumer poll loop ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5)); for (ConsumerRecord<String, String> record : records) { String key = record.key(); Integer count = groupByCounts.get(key); if (count "== null) { count = 0; } count += 1; groupByCounts.put(key, count); } } @gamussa #NYCKafka @ @confluentinc
while (true) { "// consumer poll loop ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5)); for (ConsumerRecord<String, String> record : records) { String key = record.key(); Integer count = groupByCounts.get(key); if (count "== null) { count = 0; } count += 1; !// actually doing something useful groupByCounts.put(key, count); } } @gamussa #NYCKafka @ @confluentinc
if (counter"++ % sendInterval "== 0) { for (Map.Entry<String, Integer> groupedEntry : groupByCounts.entrySet()) { ProducerRecord<String, Integer> producerRecord = new ProducerRecord!<>("group-by-counts", groupedEntry.getKey(), groupedEntry.getValue()); producer.send(producerRecord); } consumer.commitSync(); } } } @gamussa #NYCKafka @ @confluentinc
if (counter"++ % sendInterval "== 0) { for (Map.Entry<String, Integer> groupedEntry : groupByCounts.entrySet()) { ProducerRecord<String, Integer> producerRecord = new ProducerRecord!<>("group-by-counts", groupedEntry.getKey(), groupedEntry.getValue()); producer.send(producerRecord); } consumer.commitSync(); } } } @gamussa #NYCKafka @ @confluentinc
if (counter"++ % sendInterval "== 0) { for (Map.Entry<String, Integer> groupedEntry : groupByCounts.entrySet()) { ProducerRecord<String, Integer> producerRecord = new ProducerRecord!<>("group-by-counts", groupedEntry.getKey(), groupedEntry.getValue()); producer.send(producerRecord); } consumer.commitSync(); } } } @gamussa #NYCKafka @ @confluentinc
LET’S TALK ABOUT THIS FRAMEWORK OF YOURS. I THINK ITS GOOD, EXCEPT IT SUCKS @gamussa #NYCKafka @ @confluentinc
SO LET ME WRITE THE FRAMEWORK THAT’S WHY IT MIGHT BE REALLY GOOD @gamussa #NYCKafka @ @confluentinc
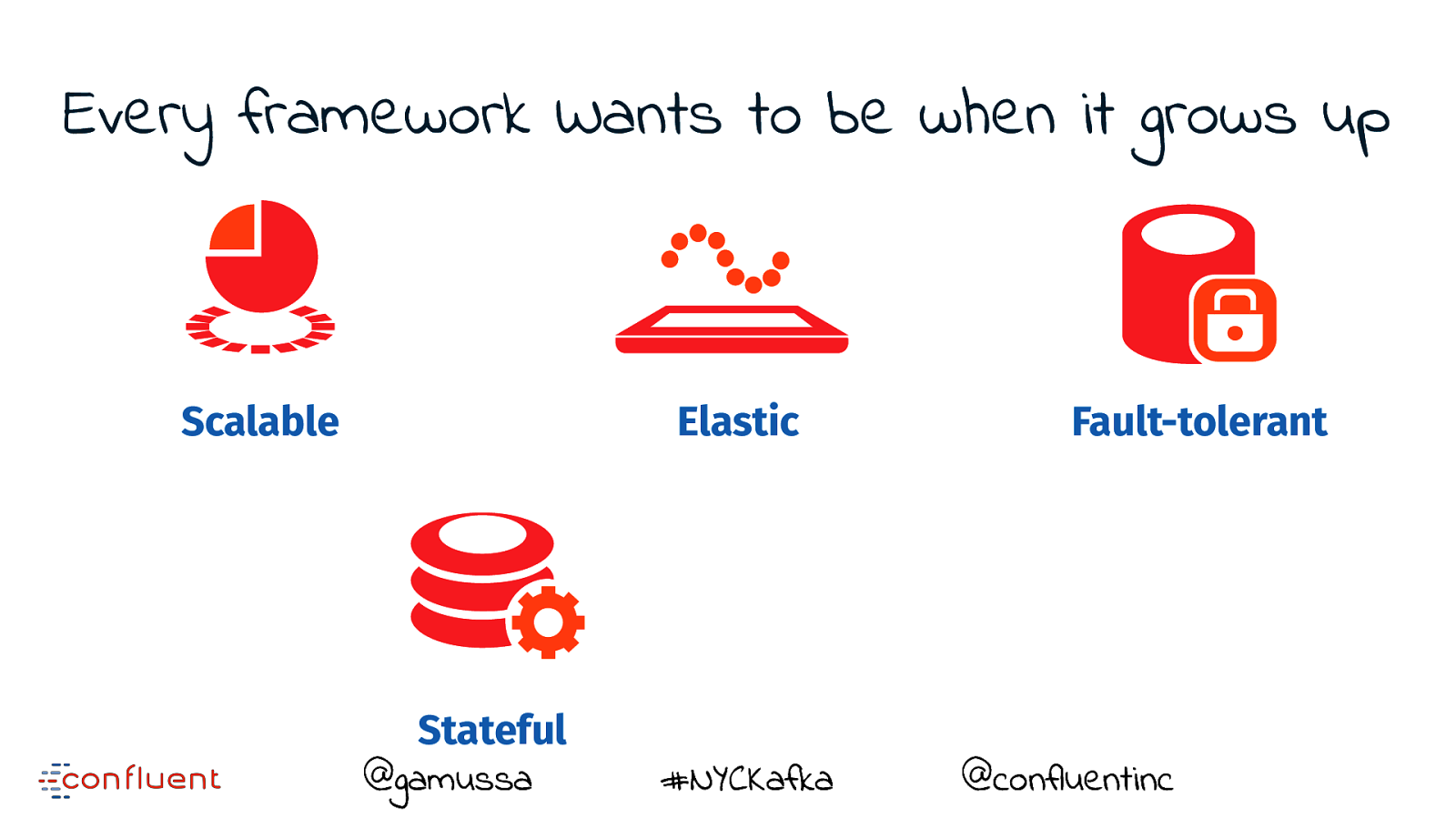
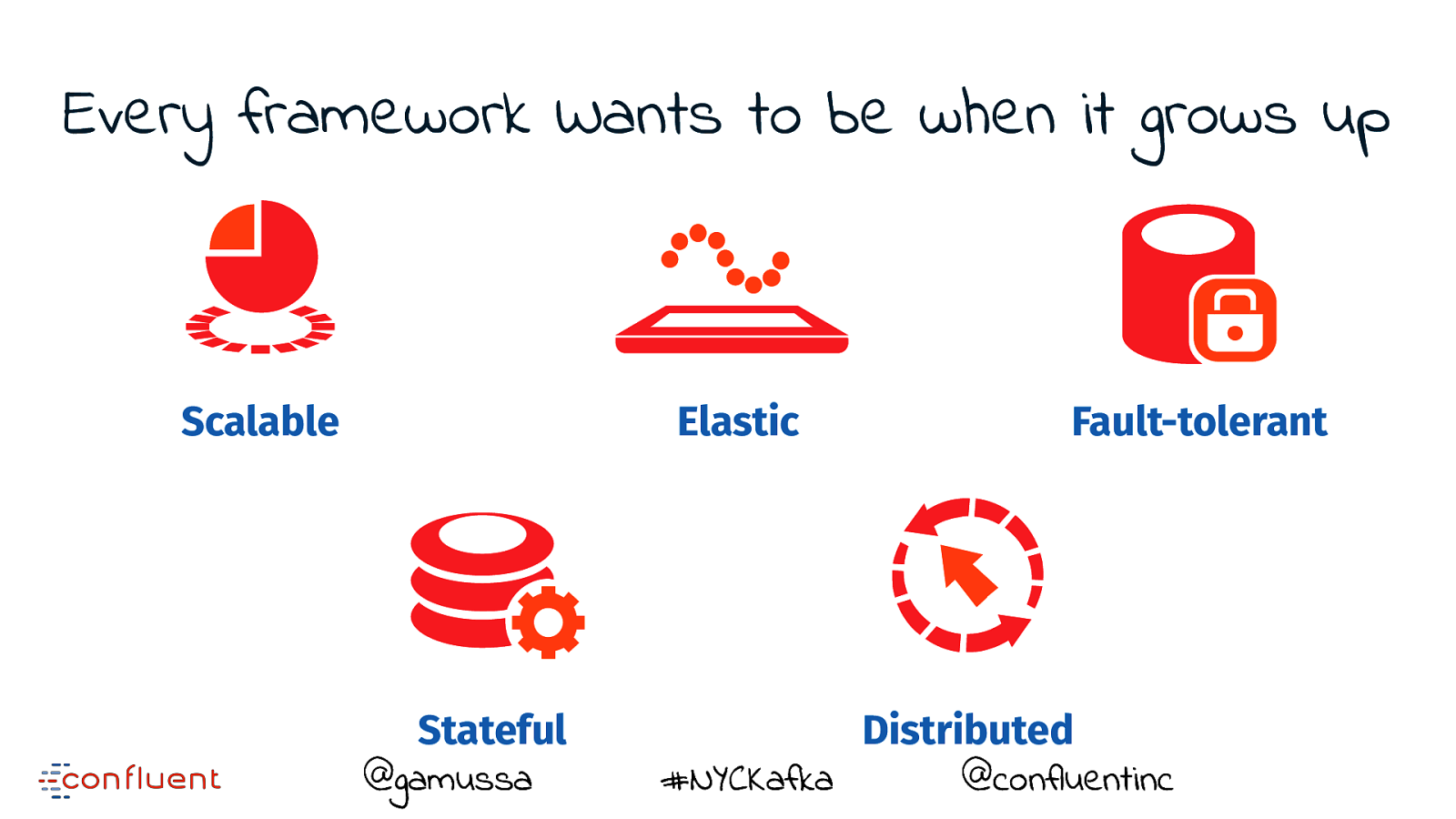
Every framework Wants to be when it grows up @gamussa #NYCKafka @confluentinc
Every framework Wants to be when it grows up Scalable @gamussa #NYCKafka @confluentinc
Every framework Wants to be when it grows up Scalable Elastic @gamussa #NYCKafka @confluentinc
Every framework Wants to be when it grows up Scalable Elastic @gamussa #NYCKafka Fault-tolerant @confluentinc
Every framework Wants to be when it grows up Scalable Elastic Stateful @gamussa #NYCKafka Fault-tolerant @confluentinc
Every framework Wants to be when it grows up Scalable Elastic Stateful @gamussa #NYCKafka Fault-tolerant Distributed @confluentinc
final StreamsBuilder streamsBuilder = new StreamsBuilder(); final KStream<String, Long> stream = streamsBuilder.stream(Arrays.asList("A", "B")); stream.groupByKey() .count() .toStream() .to("group-by-counts", Produced.with(Serdes.String(), Serdes.Long())); final Topology topology = streamsBuilder.build(); final KafkaStreams kafkaStreams = new KafkaStreams(topology, streamsProperties()); kafkaStreams.start(); @gamussa #NYCKafka @ @confluentinc
final StreamsBuilder streamsBuilder = new StreamsBuilder(); final KStream<String, Long> stream = streamsBuilder.stream(Arrays.asList("A", "B")); "// actual work stream.groupByKey() .count() .toStream() .to("group-by-counts", Produced.with(Serdes.String(), Serdes.Long())); final Topology topology = streamsBuilder.build(); final KafkaStreams kafkaStreams = new KafkaStreams(topology, streamsProperties()); kafkaStreams.start(); @gamussa #NYCKafka @ @confluentinc
final StreamsBuilder streamsBuilder = new StreamsBuilder(); final KStream<String, Long> stream = streamsBuilder.stream(Arrays.asList("A", "B")); "// actual work stream.groupByKey() .count() .toStream() .to("group-by-counts", Produced.with(Serdes.String(), Serdes.Long())); final Topology topology = streamsBuilder.build(); final KafkaStreams kafkaStreams = new KafkaStreams(topology, streamsProperties()); kafkaStreams.start(); @gamussa #NYCKafka @ @confluentinc
final StreamsBuilder streamsBuilder = new StreamsBuilder(); final KStream<String, Long> stream = streamsBuilder.stream(Arrays.asList("A", "B")); "// actual work stream.groupByKey() .count() .toStream() .to("group-by-counts", Produced.with(Serdes.String(), Serdes.Long())); final Topology topology = streamsBuilder.build(); final KafkaStreams kafkaStreams = new KafkaStreams(topology, streamsProperties()); kafkaStreams.start(); @gamussa #NYCKafka @ @confluentinc
@gamussa #NYCKafka @ @confluentinc
@gamussa #NYCKafka @ @confluentinc
https://twitter.com/157rahul/status/1050505569746841600
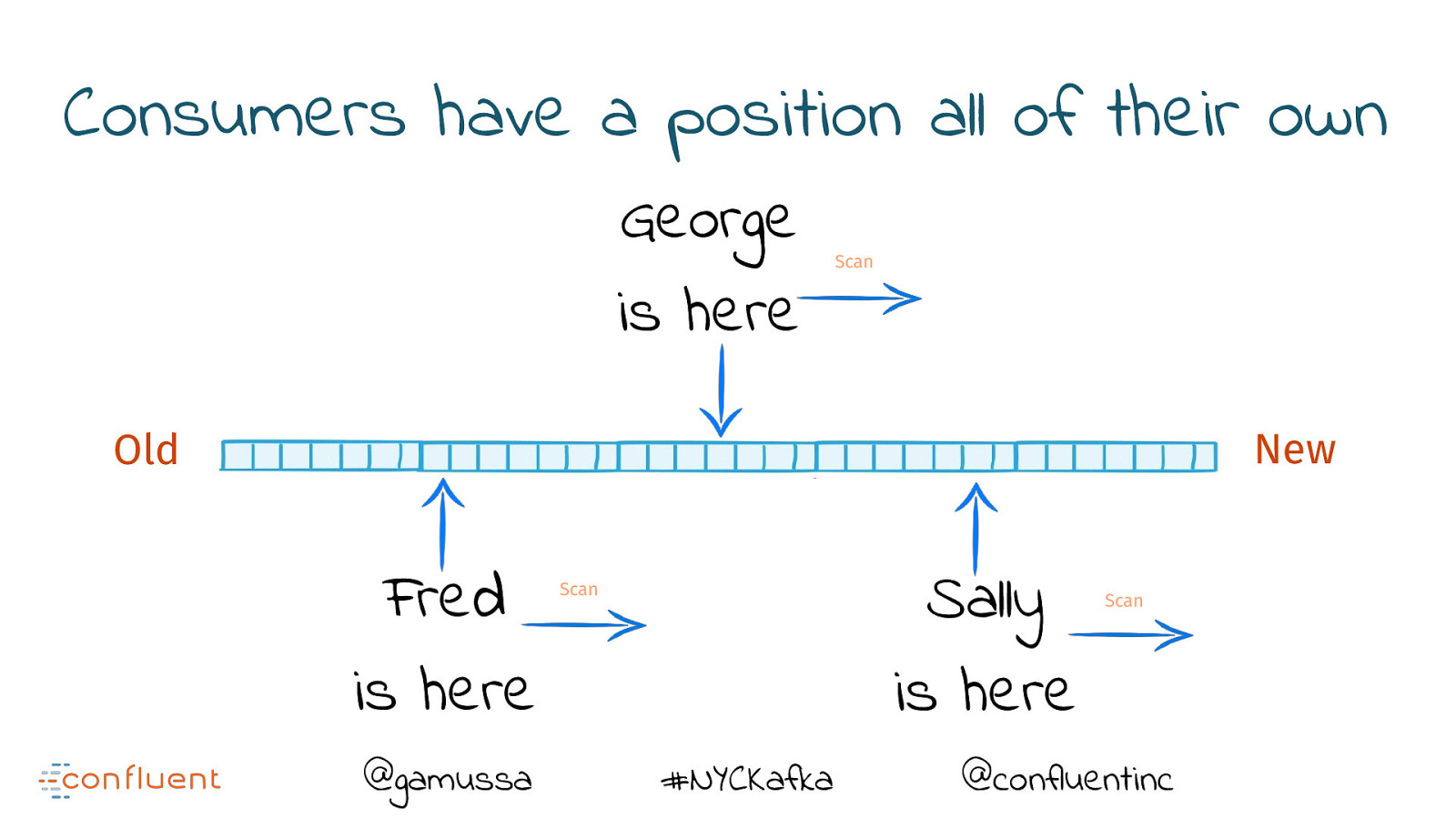
The log is a simple idea New Old Messages are added at the end of the log @gamussa #NYCKafka @confluentinc
Consumers have a position all of their own George is here Scan New Old Fred is here @gamussa Sally is here Scan #NYCKafka Scan @confluentinc
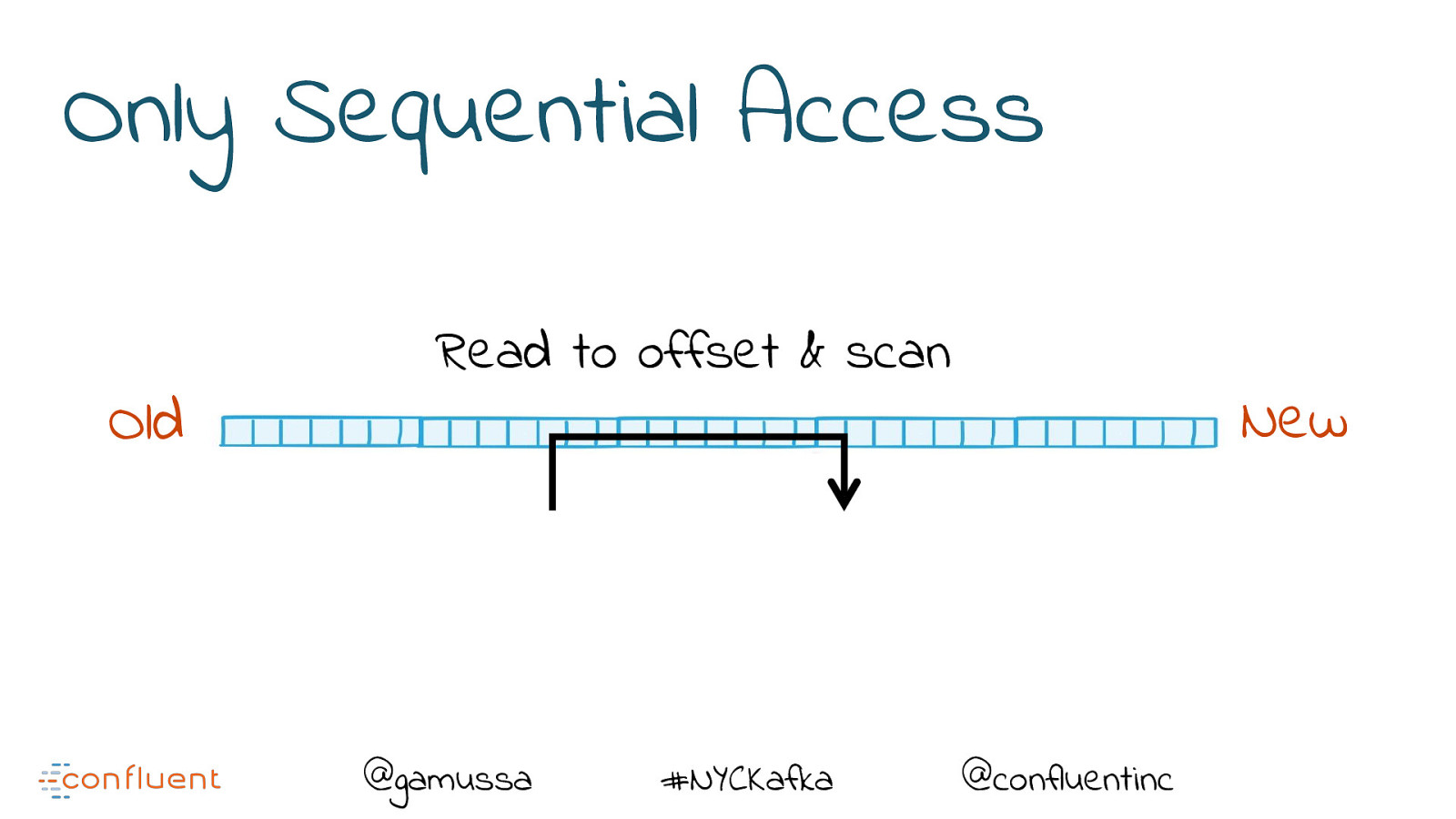
Only Sequential Access Old Read to offset & scan @gamussa #NYCKafka New @confluentinc
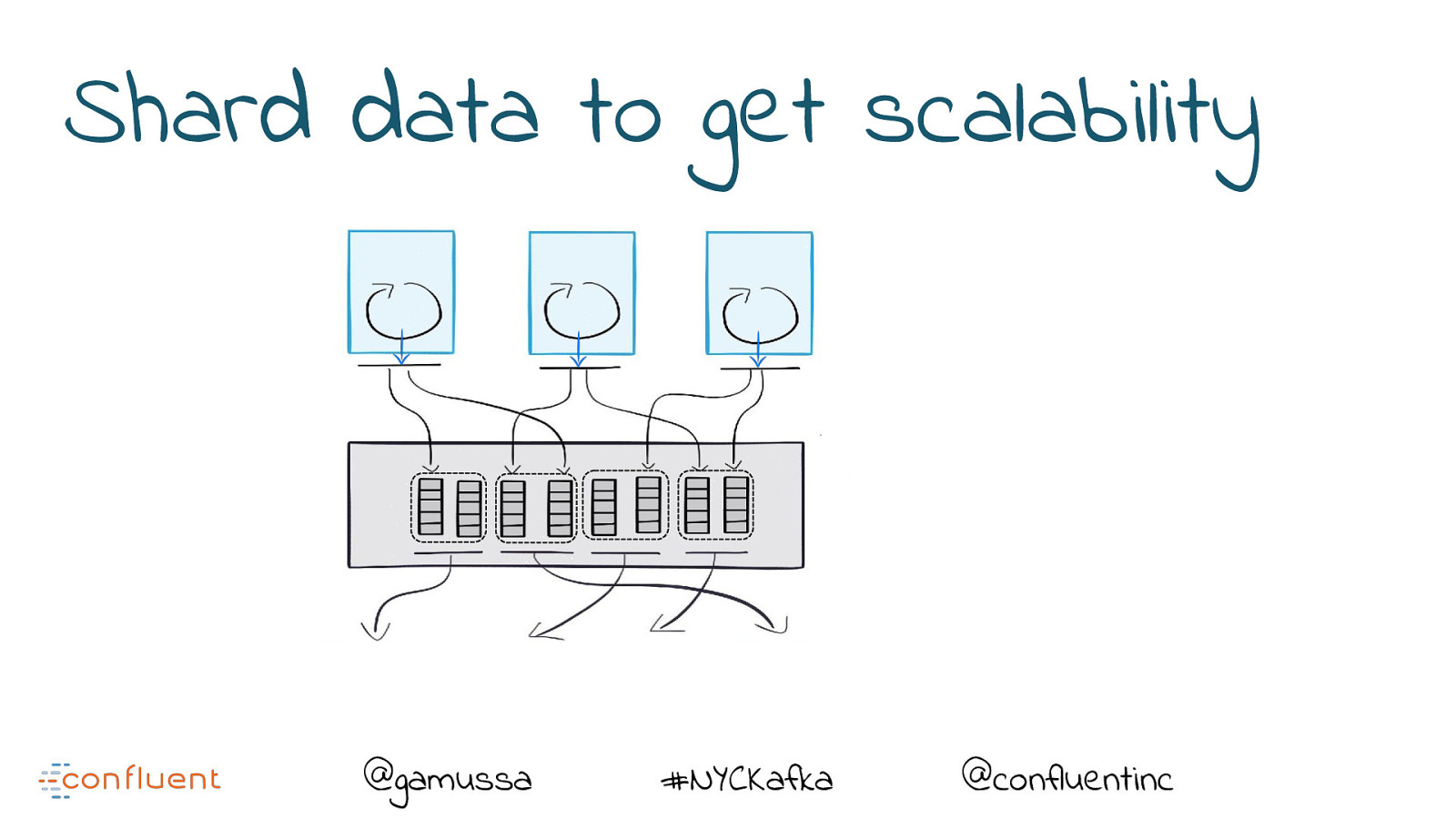
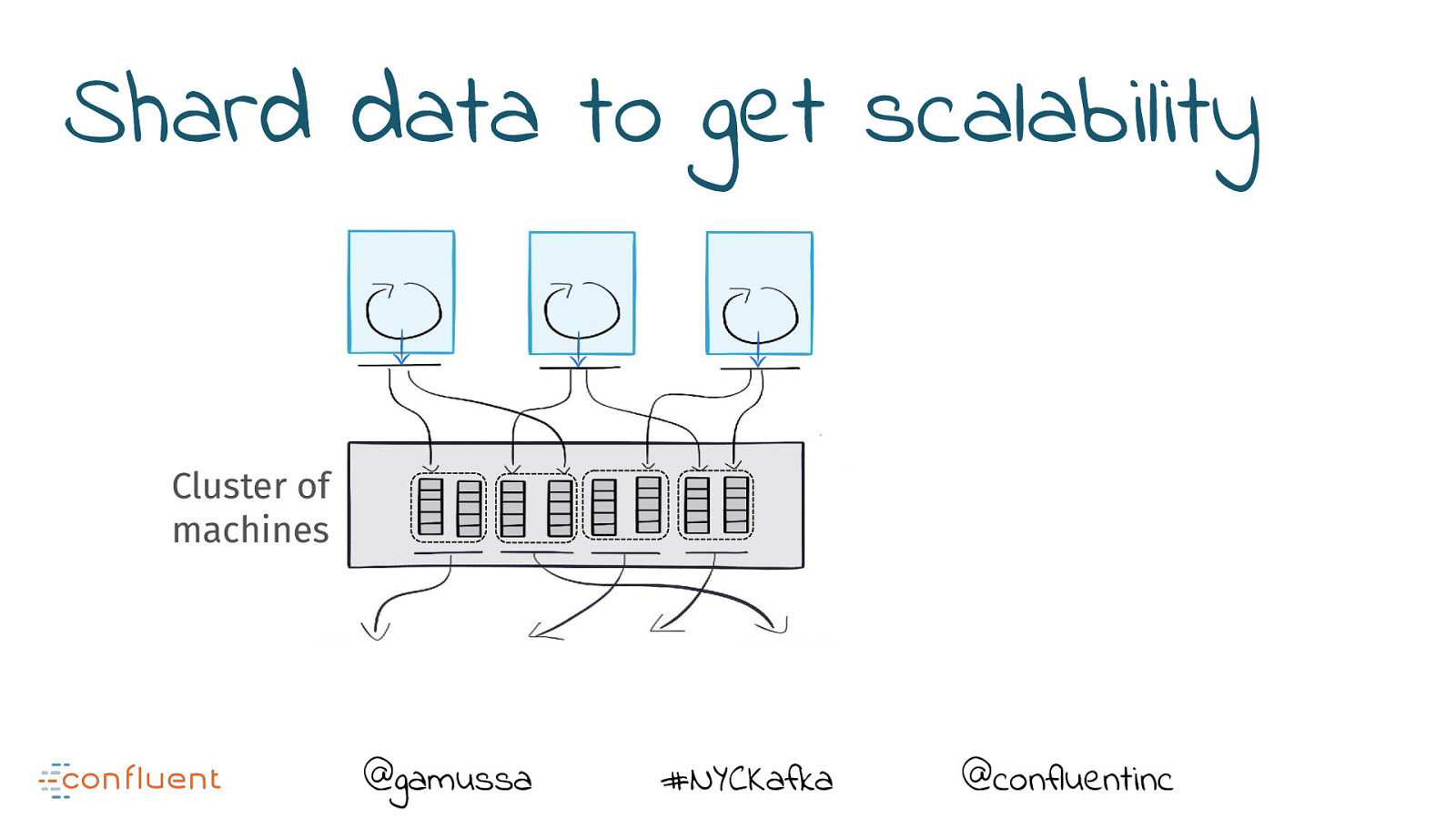
Shard data to get scalability @gamussa #NYCKafka @confluentinc
Shard data to get scalability Cluster of machines @gamussa #NYCKafka @confluentinc
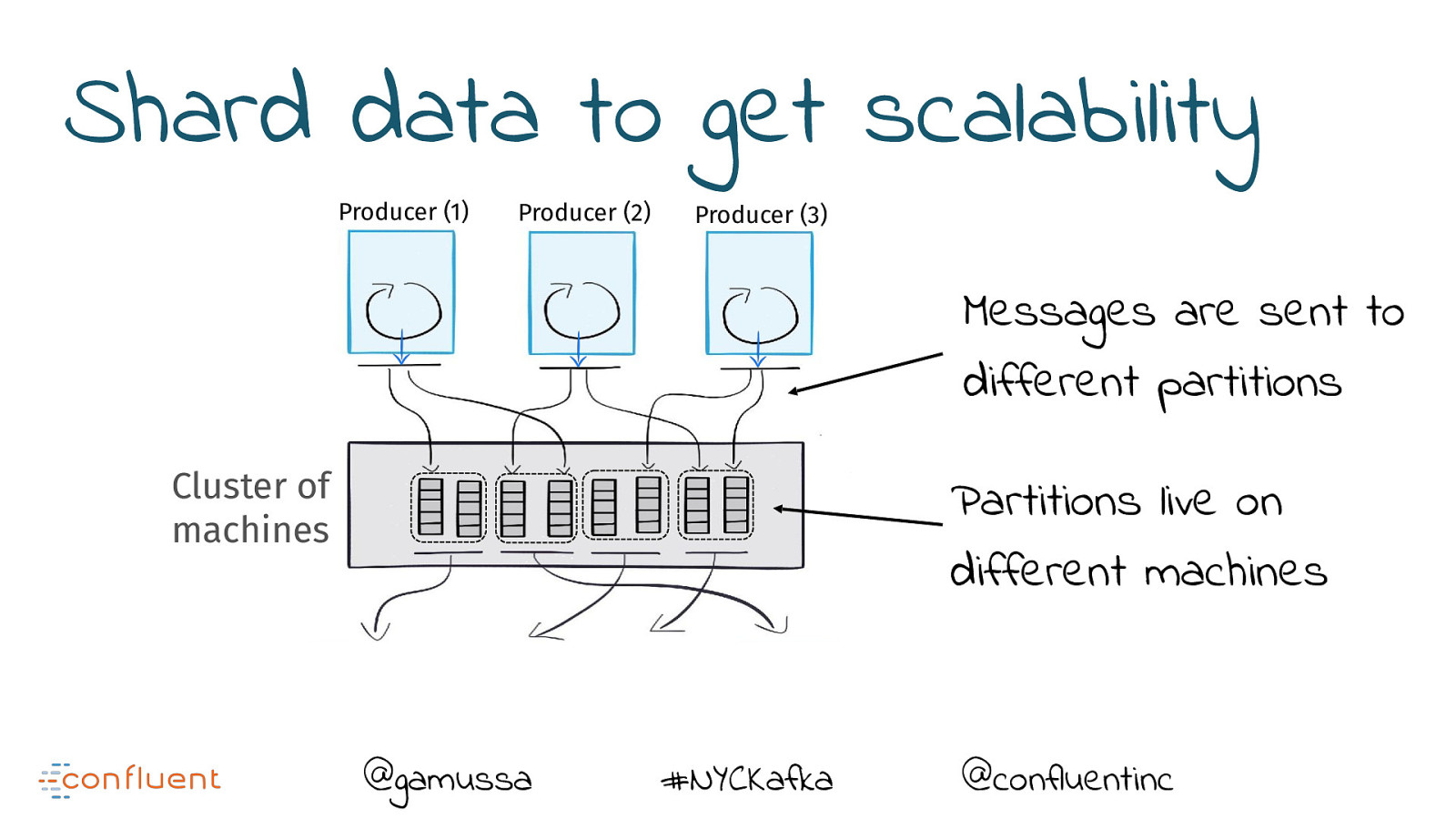
Shard data to get scalability Producer (1) Producer (2) Producer (3) Messages are sent to different partitions Cluster of machines Partitions live on different machines @gamussa #NYCKafka @confluentinc
CONSUMER GROUP COORDINATOR
CONSUMERS CONSUMER GROUP COORDINATOR
CONSUMERS CONSUMER GROUP CONSUMER GROUP COORDINATOR
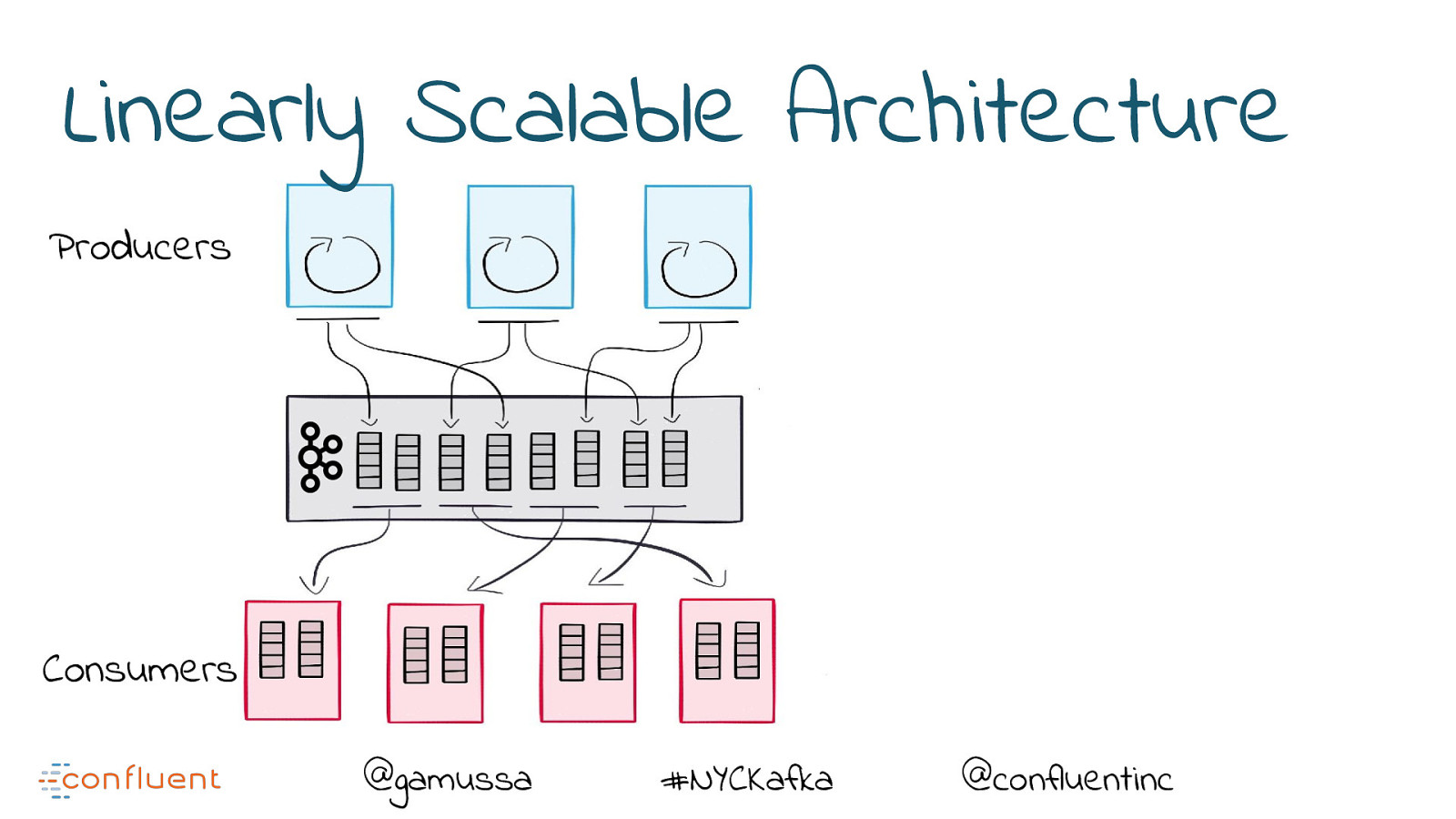
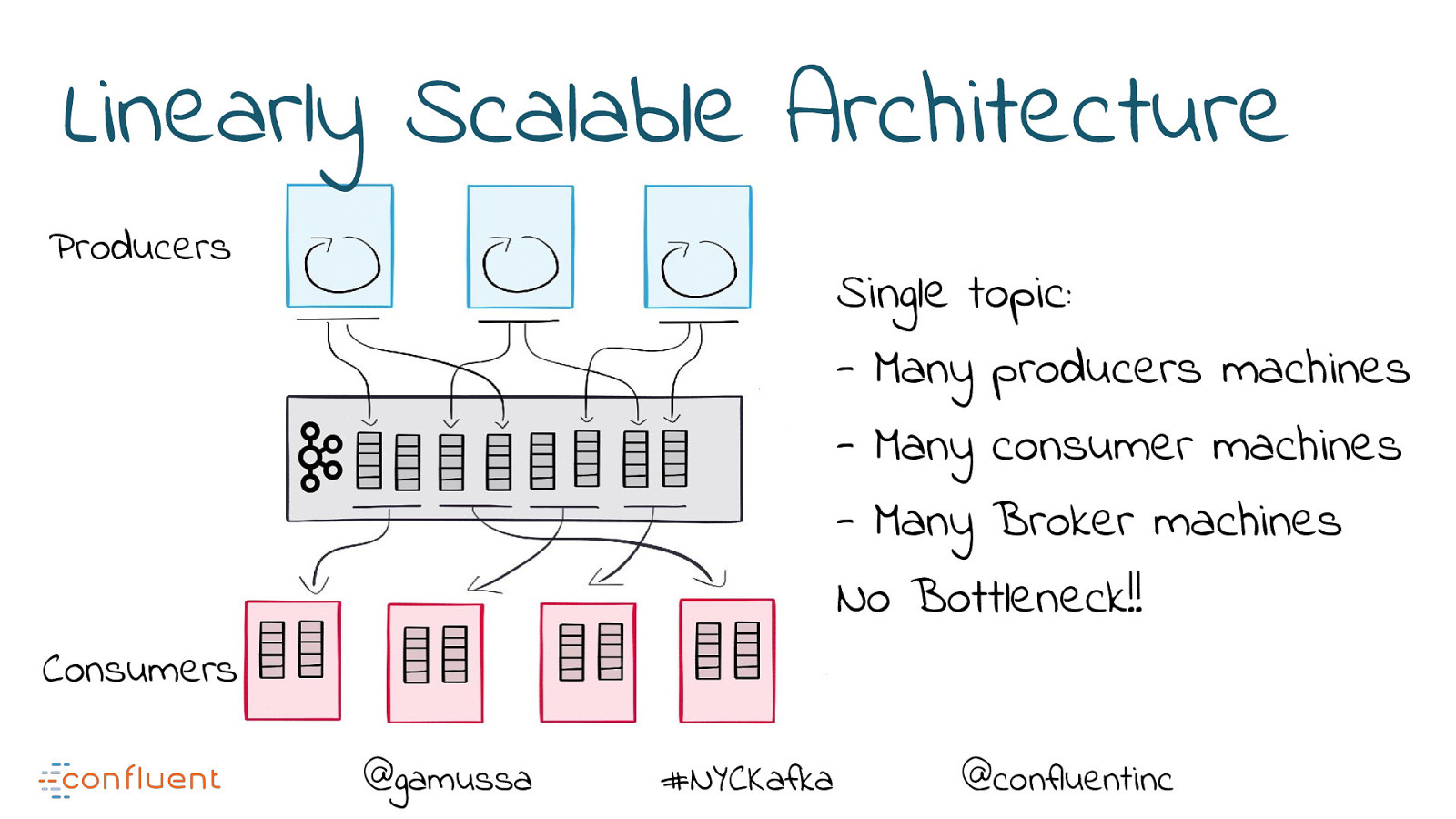
Linearly Scalable Architecture Producers Consumers @gamussa #NYCKafka @confluentinc
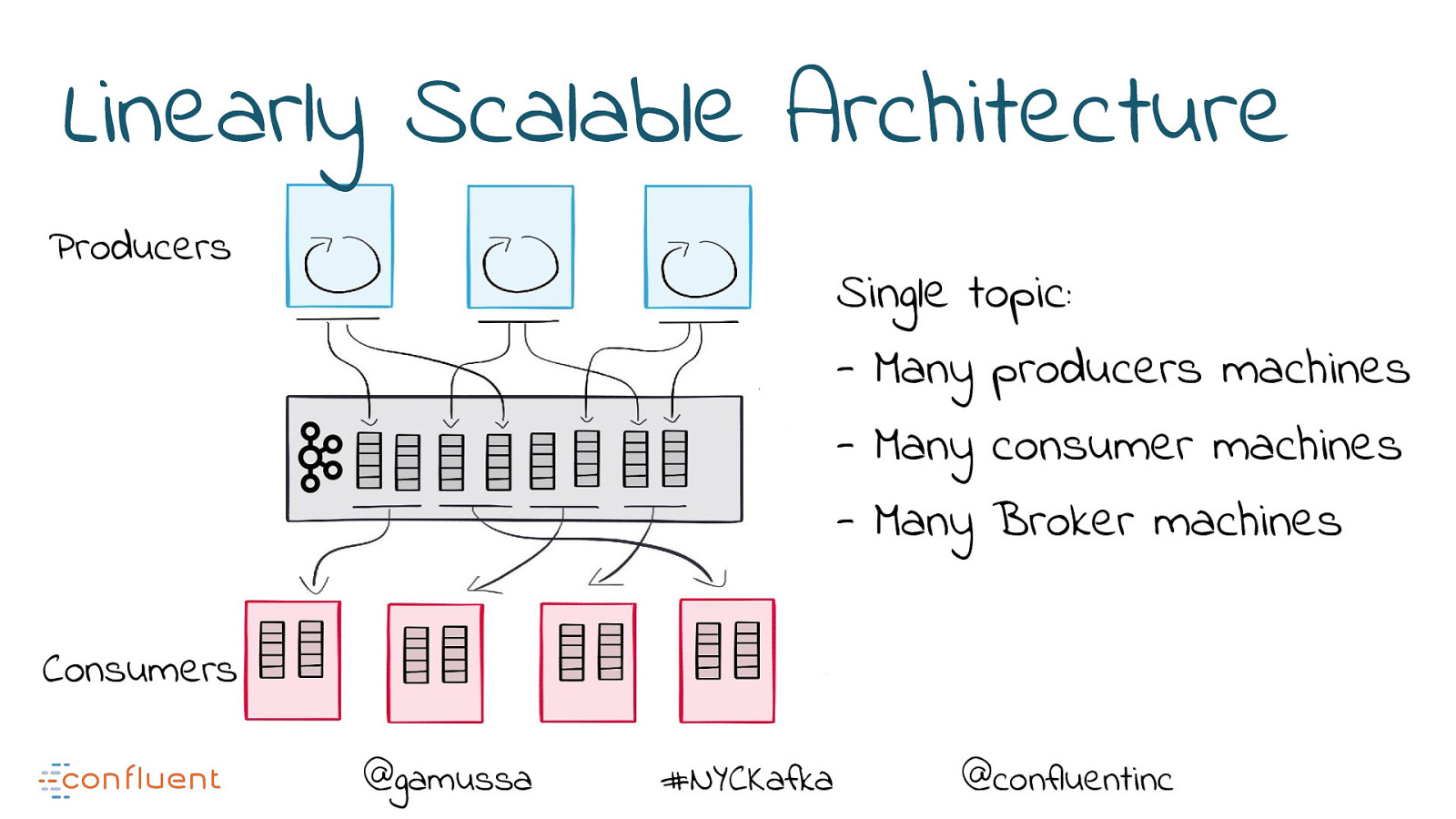
Linearly Scalable Architecture Producers Single topic: - Many producers machines - Many consumer machines - Many Broker machines Consumers @gamussa #NYCKafka @confluentinc
Linearly Scalable Architecture Producers Single topic: - Many producers machines - Many consumer machines - Many Broker machines No Bottleneck!! Consumers @gamussa #NYCKafka @confluentinc
Talk is cheap! Show me code! https://cnfl.io/streams-movie-demo
As developers, we want to build APPS not INFRASTRUCTURE @gamussa #NYCKafka @confluentinc
@
the KAFKA STREAMS API is a JAVA API to BUILD REAL-TIME APPLICATIONS @gamussa #NYCKafka @confluentinc
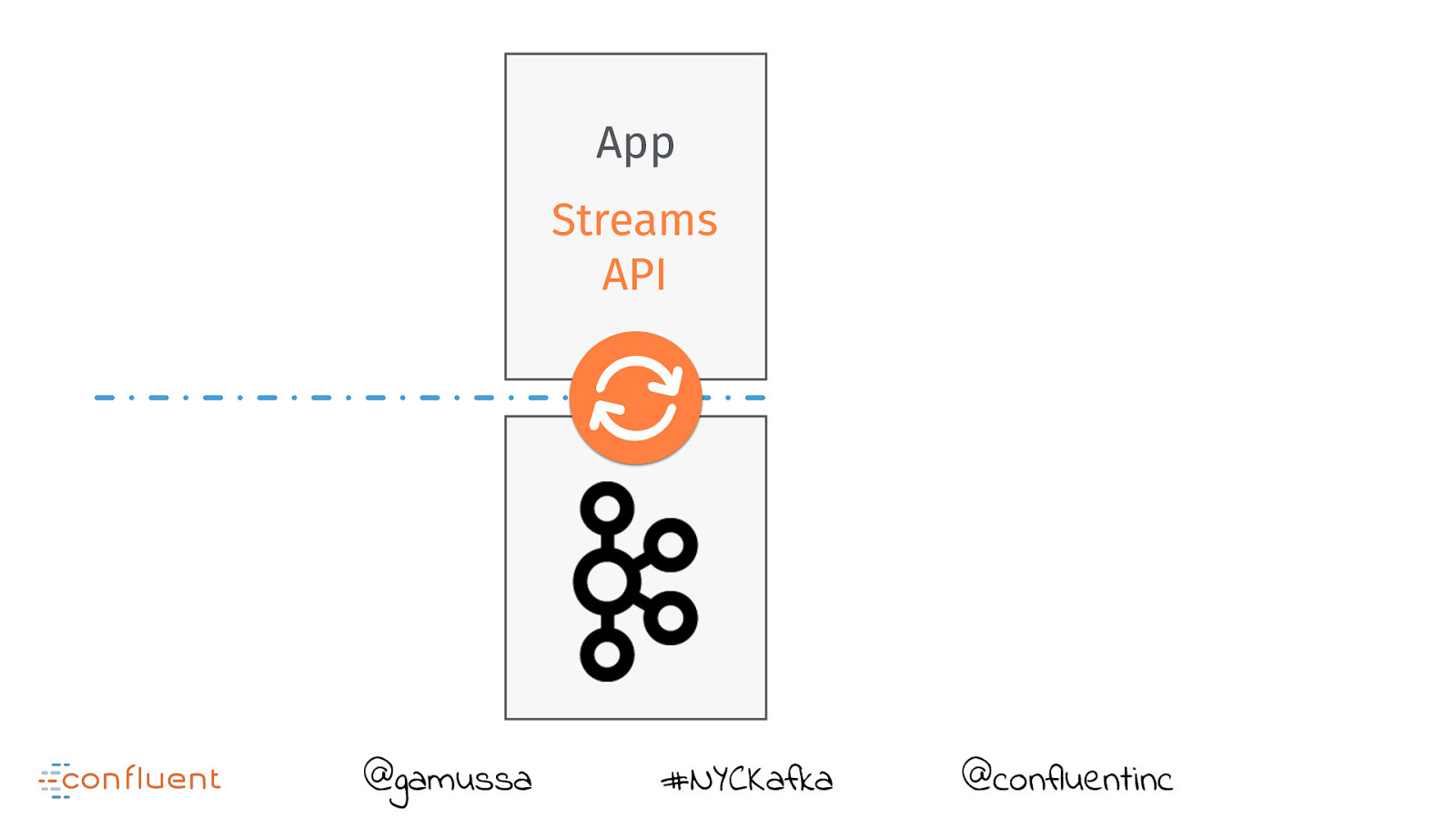
App Streams API @gamussa #NYCKafka @confluentinc
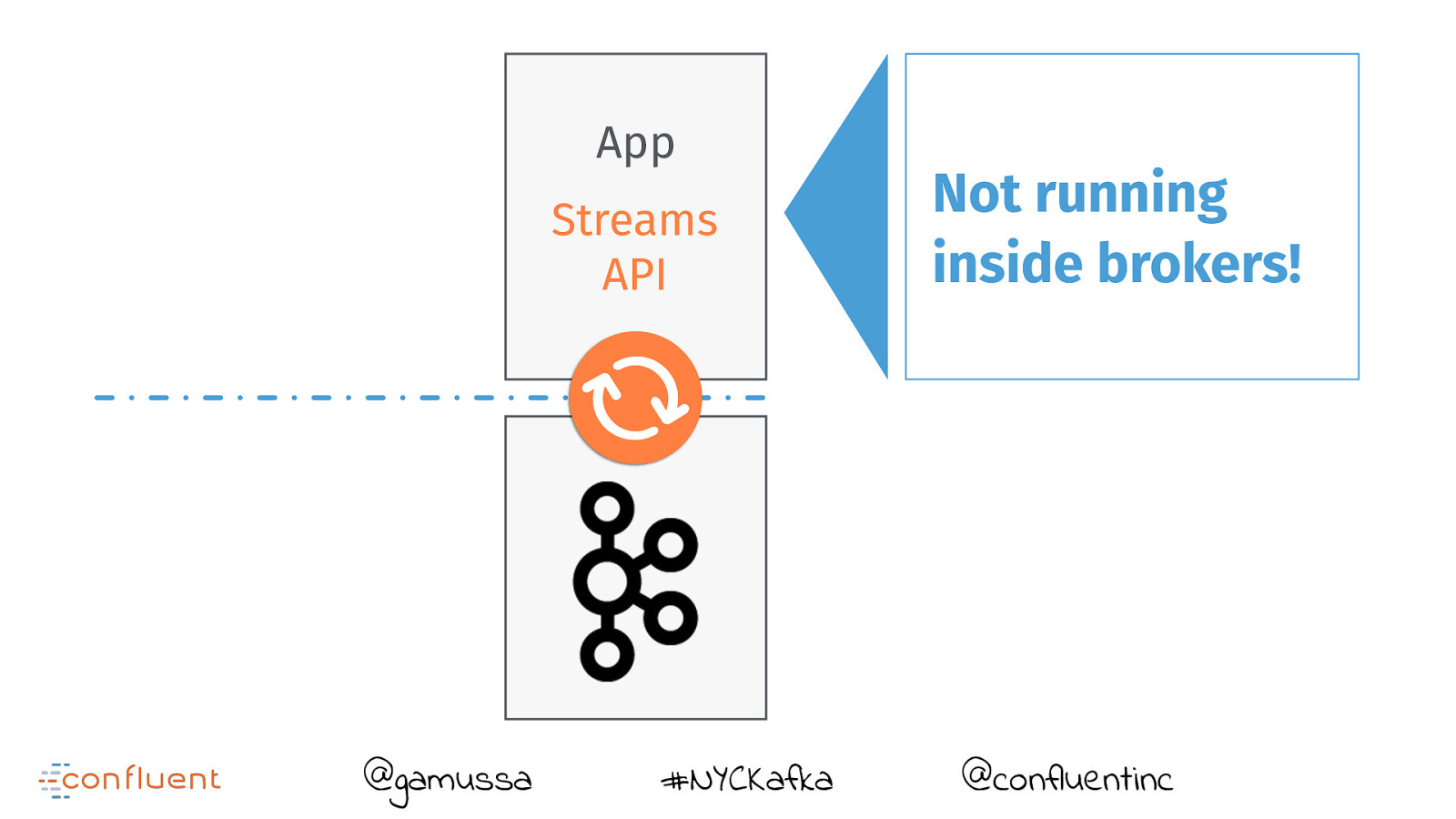
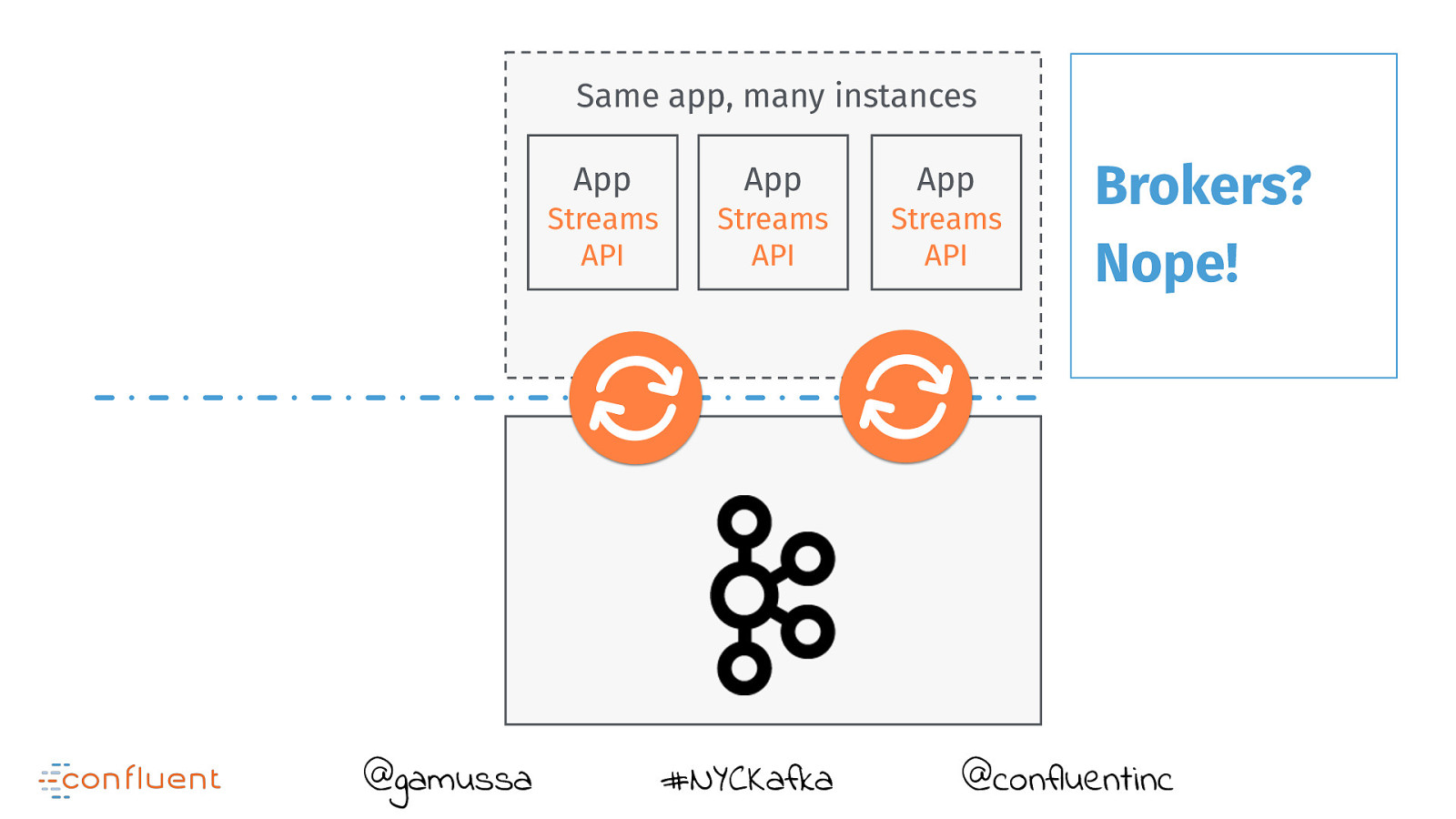
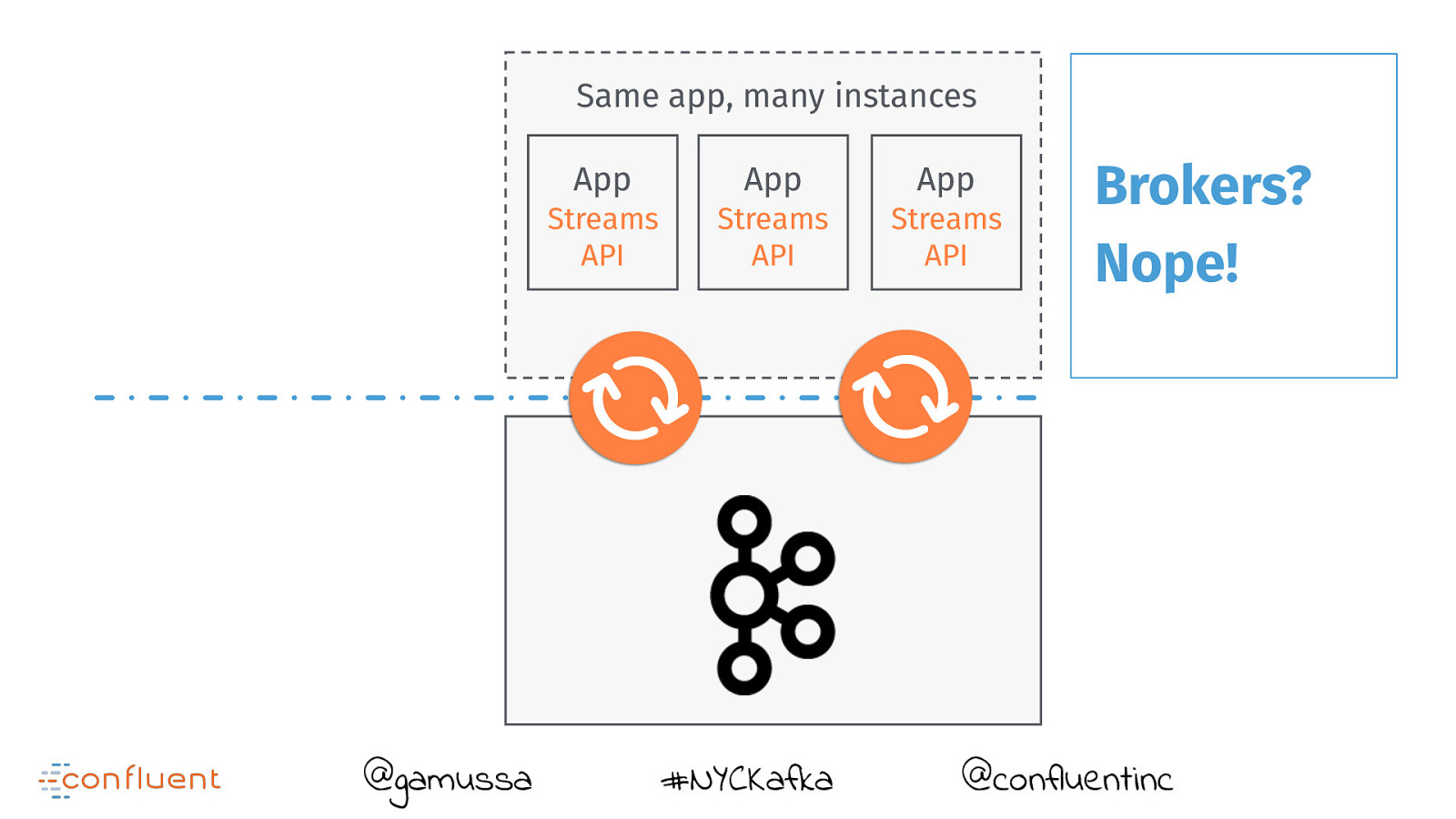
App Streams API @gamussa #NYCKafka Not running inside brokers! @confluentinc
Same app, many instances @gamussa App App App Streams API Streams API Streams API #NYCKafka Brokers? Nope! @confluentinc
Same app, many instances @gamussa App App App Streams API Streams API Streams API #NYCKafka Brokers? Nope! @confluentinc
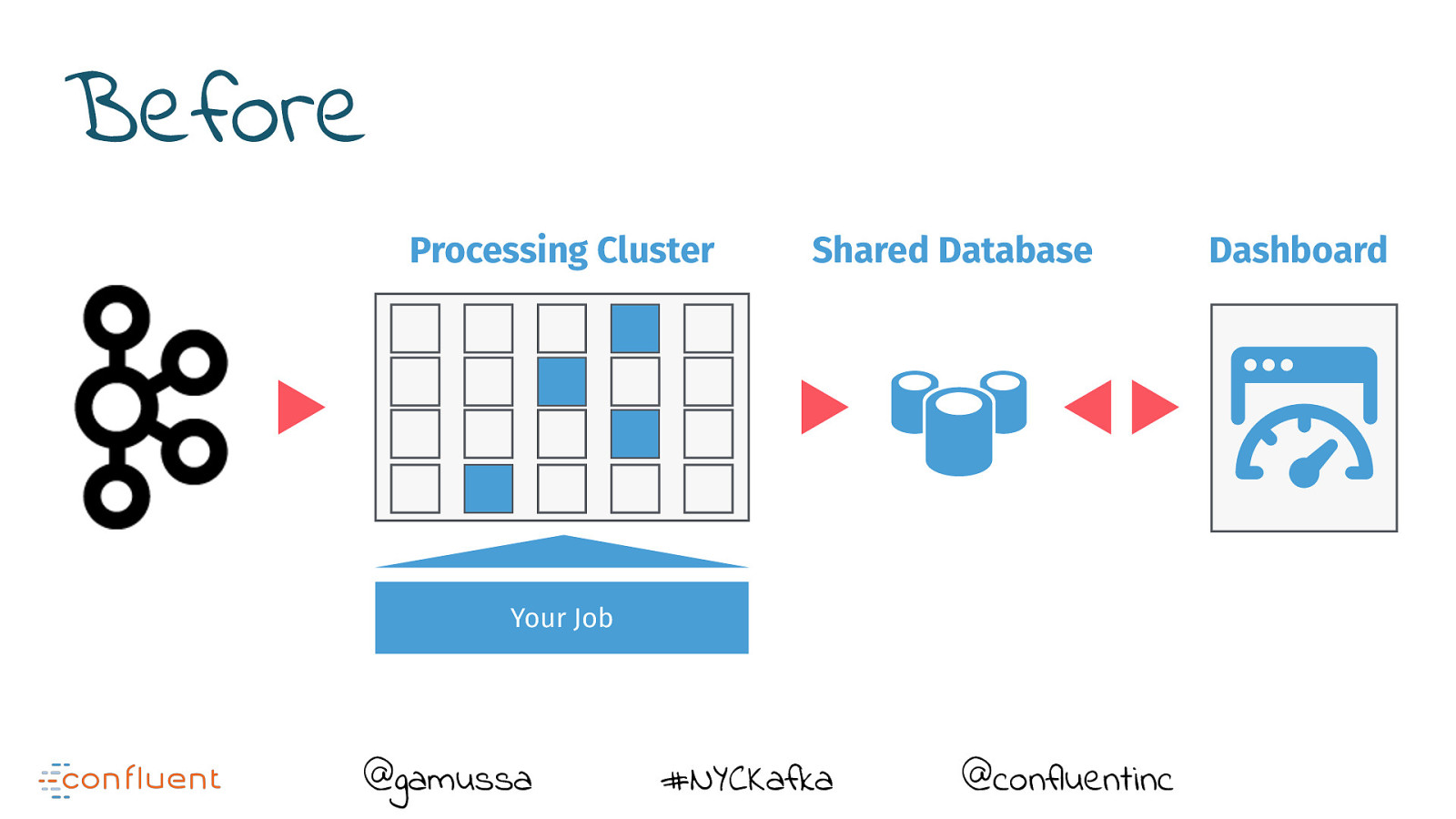
Before Processing Cluster Shared Database Your Job @gamussa #NYCKafka @confluentinc Dashboard
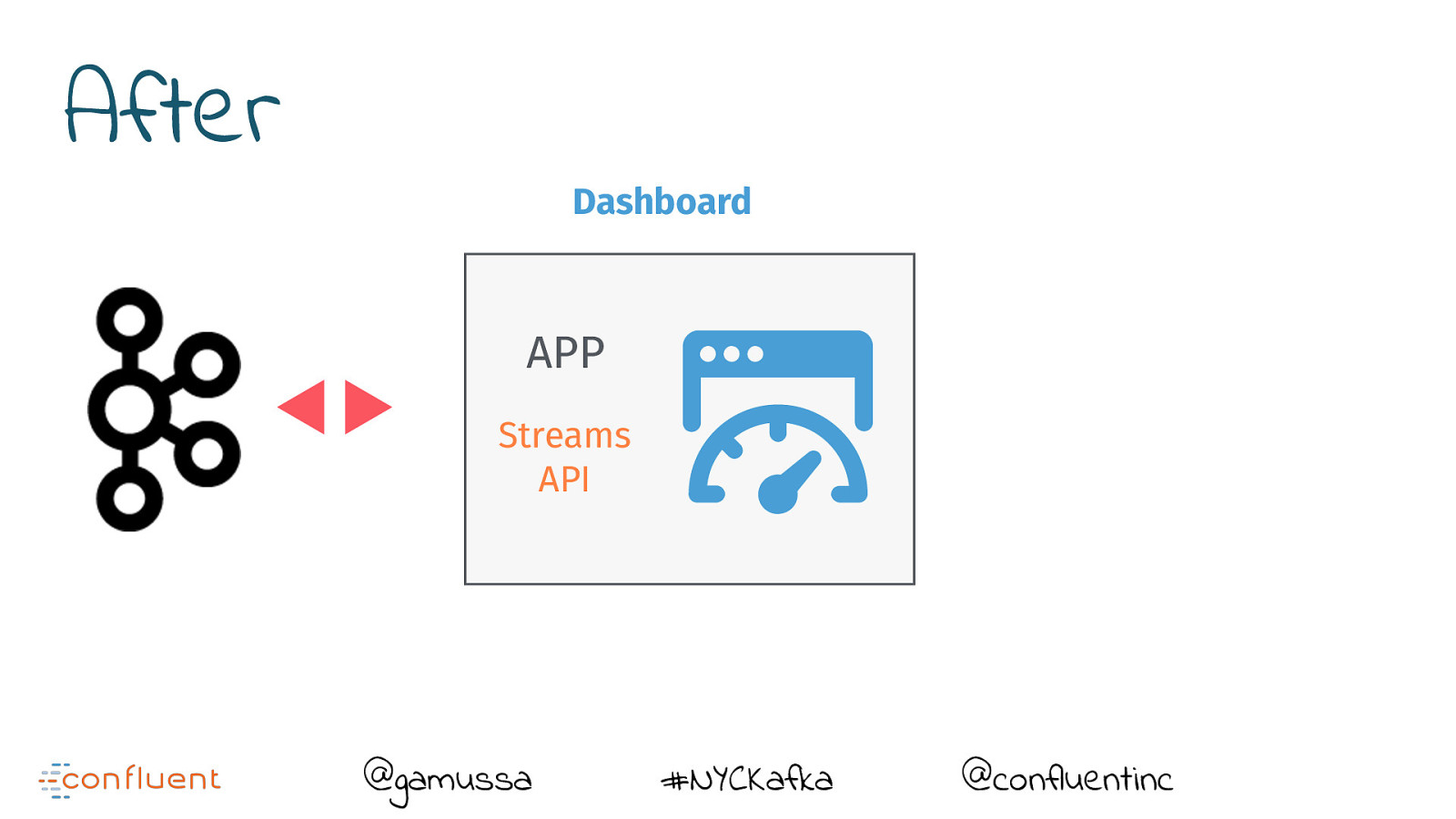
After Dashboard APP Streams API @gamussa #NYCKafka @confluentinc
this means you can DEPLOY your app ANYWHERE using WHATEVER TECHNOLOGY YOU WANT
So many places to run you app! ...and many more... @gamussa #NYCKafka @confluentinc
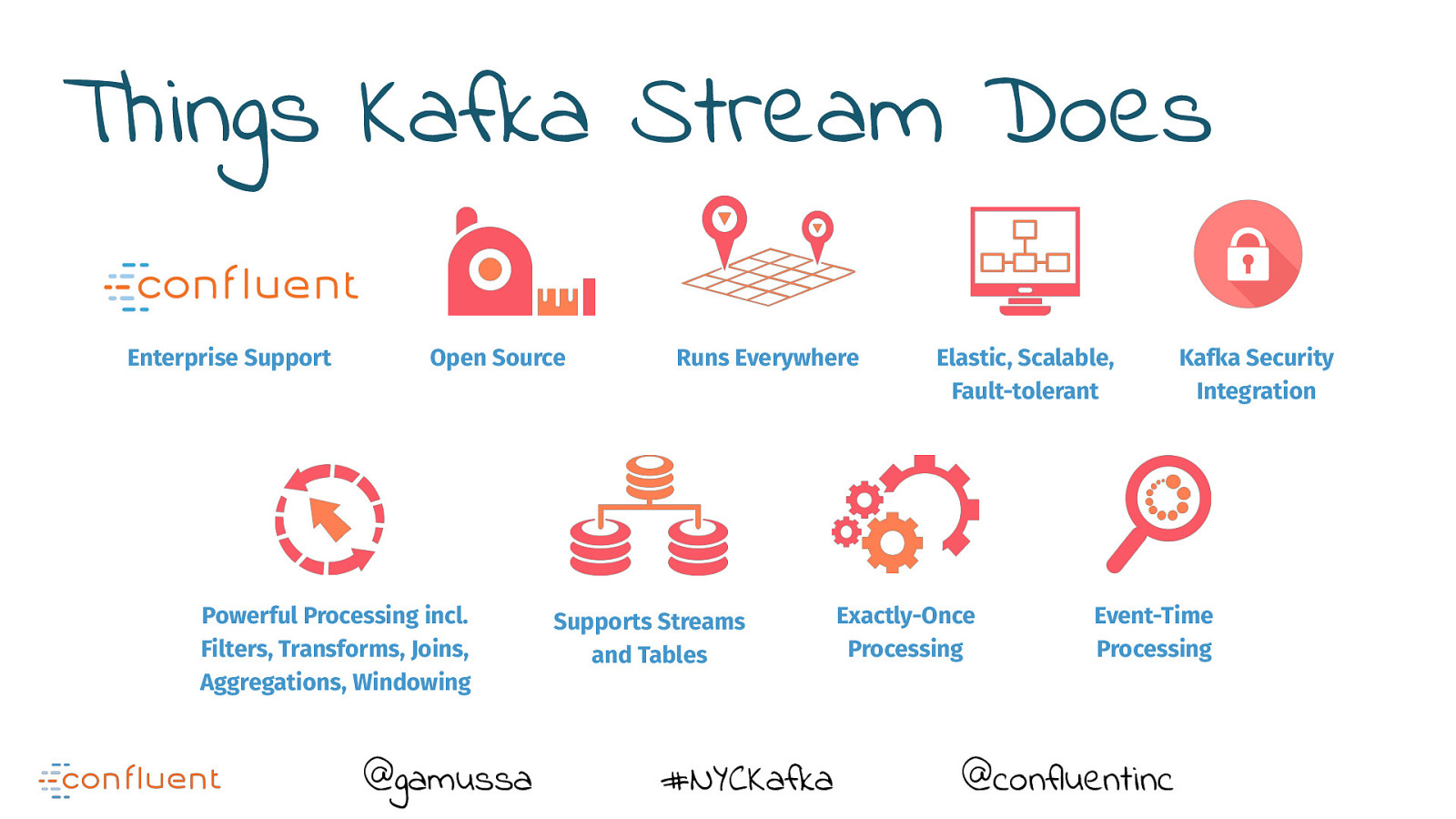
Things Kafka Stream Does Enterprise Support Open Source Powerful Processing incl. Filters, Transforms, Joins, Aggregations, Windowing @gamussa Runs Everywhere Supports Streams and Tables #NYCKafka Elastic, Scalable, Fault-tolerant Exactly-Once Processing Kafka Security Integration Event-Time Processing @confluentinc
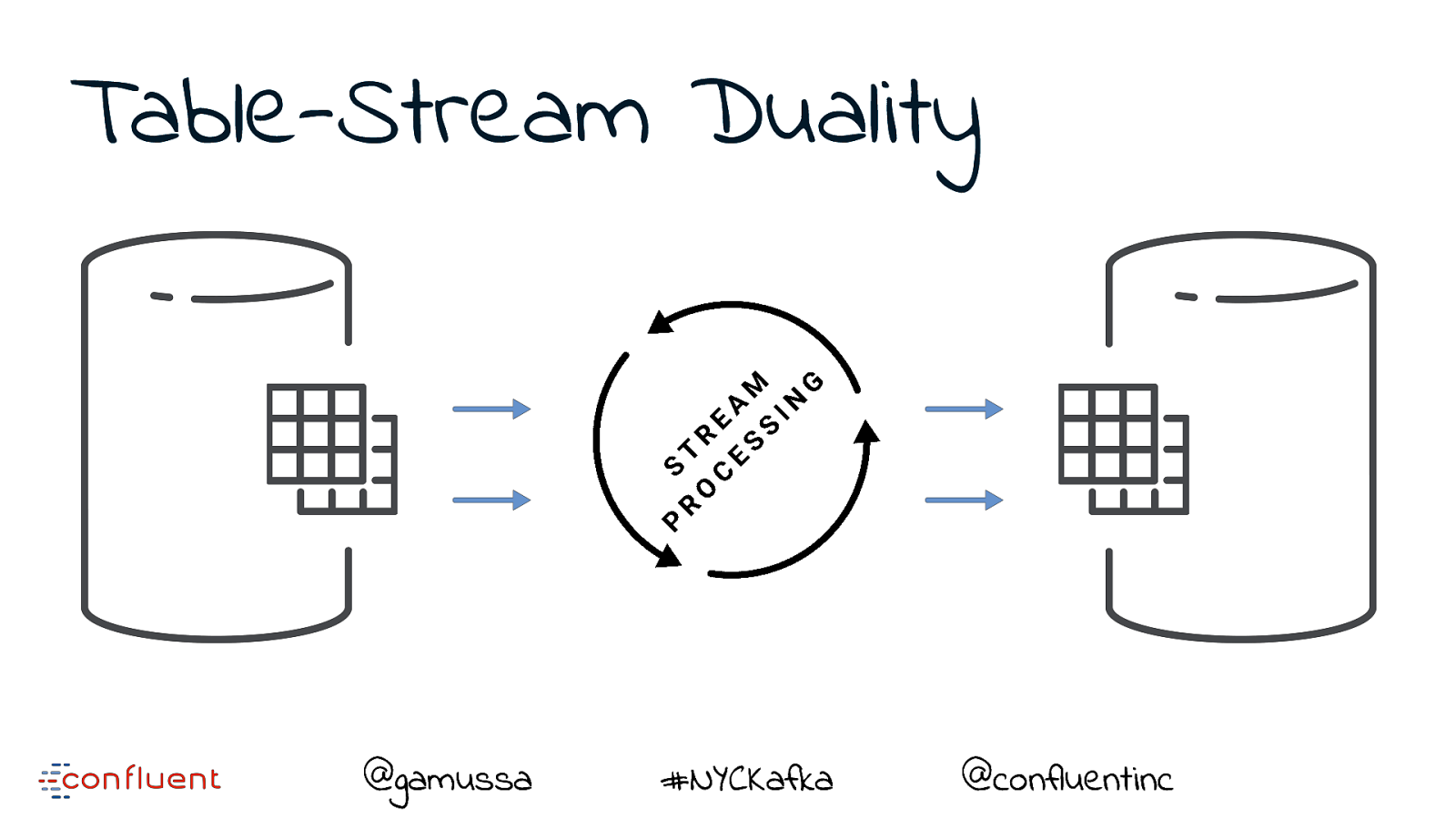
Table-Stream Duality @gamussa #NYCKafka @confluentinc
Table-Stream Duality @gamussa #NYCKafka @confluentinc
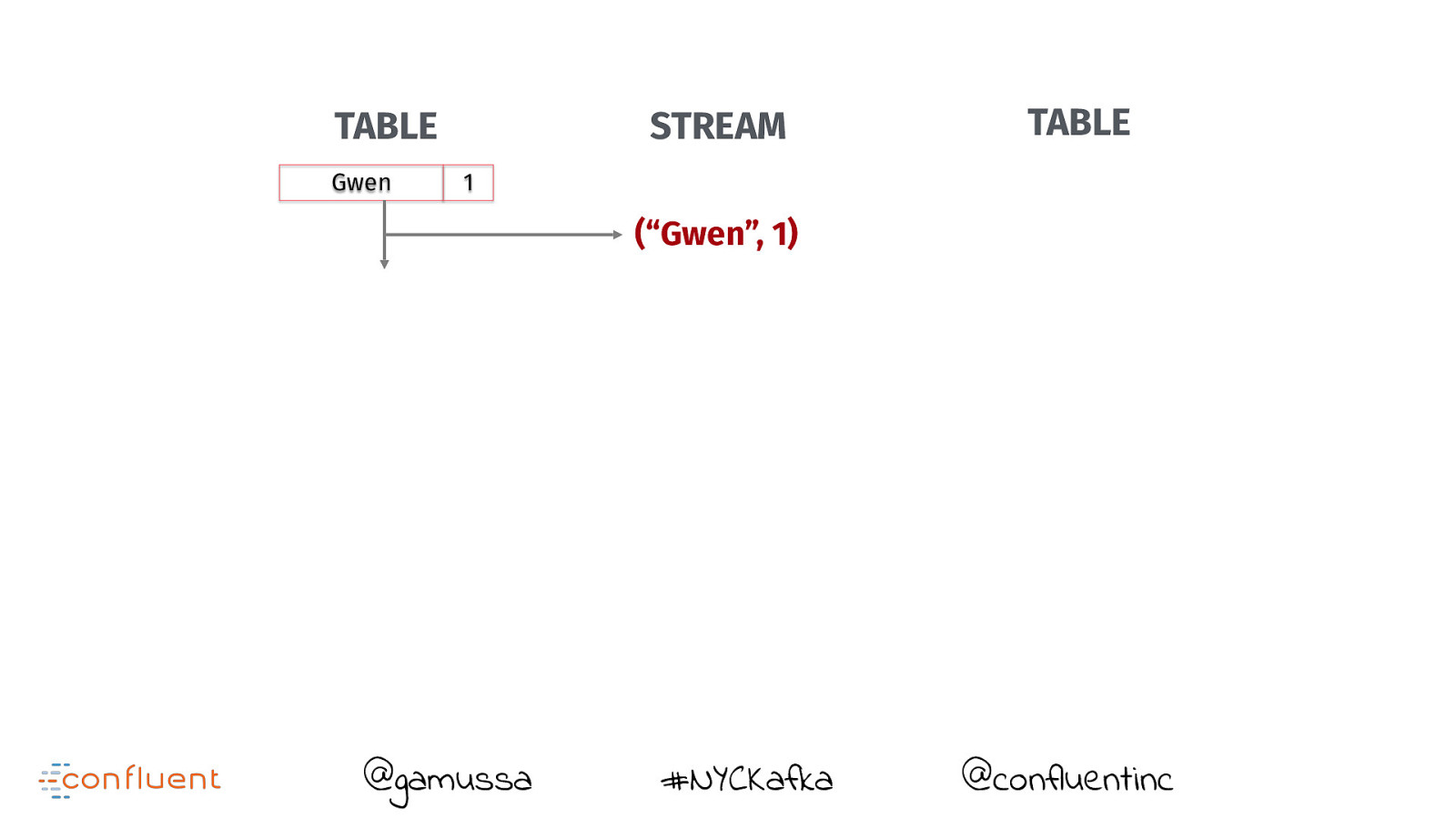
TABLE @gamussa STREAM #NYCKafka TABLE @confluentinc
TABLE Gwen STREAM TABLE 1 @gamussa #NYCKafka @confluentinc
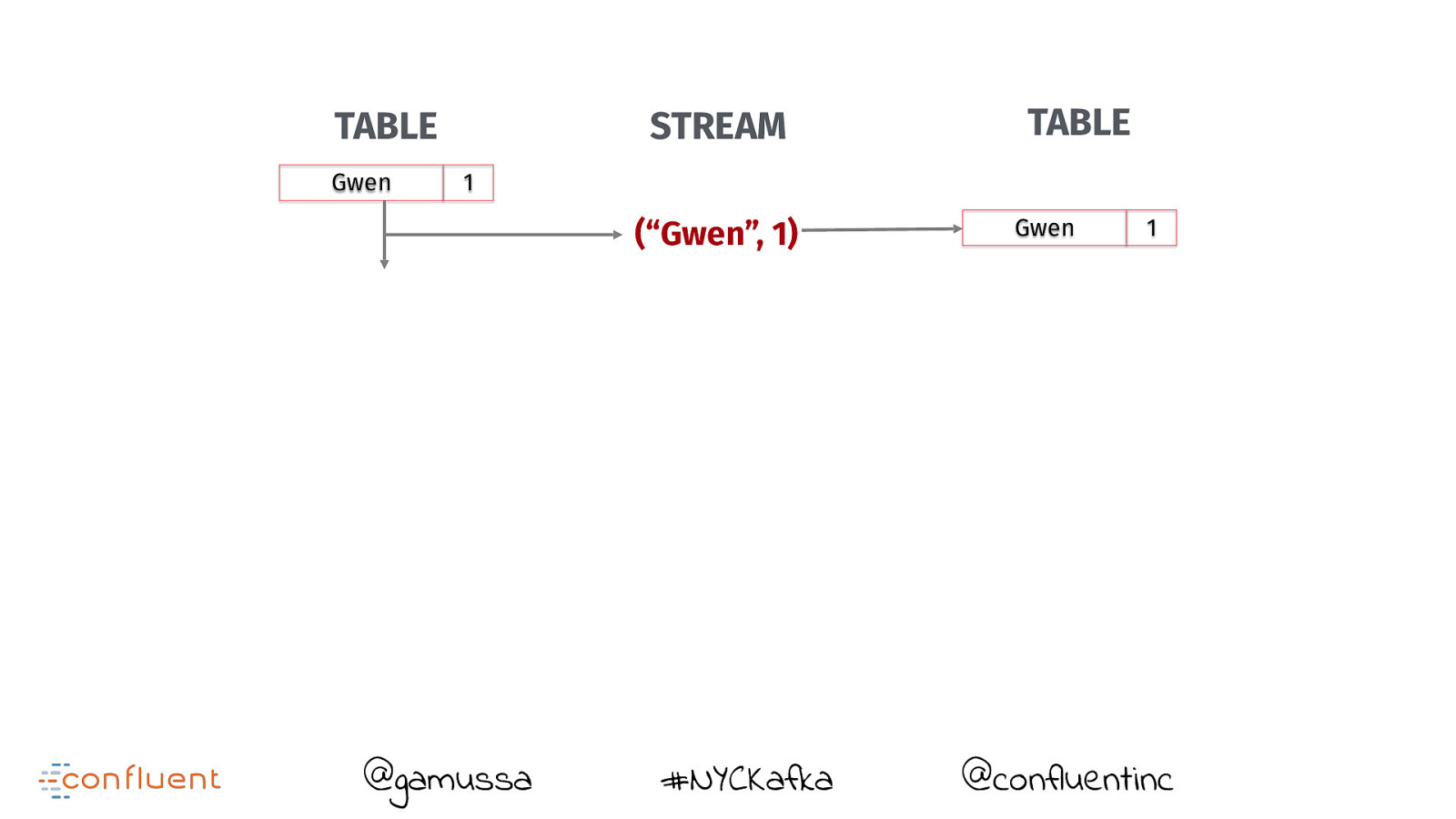
TABLE Gwen STREAM TABLE 1 (“Gwen”, 1) @gamussa #NYCKafka @confluentinc
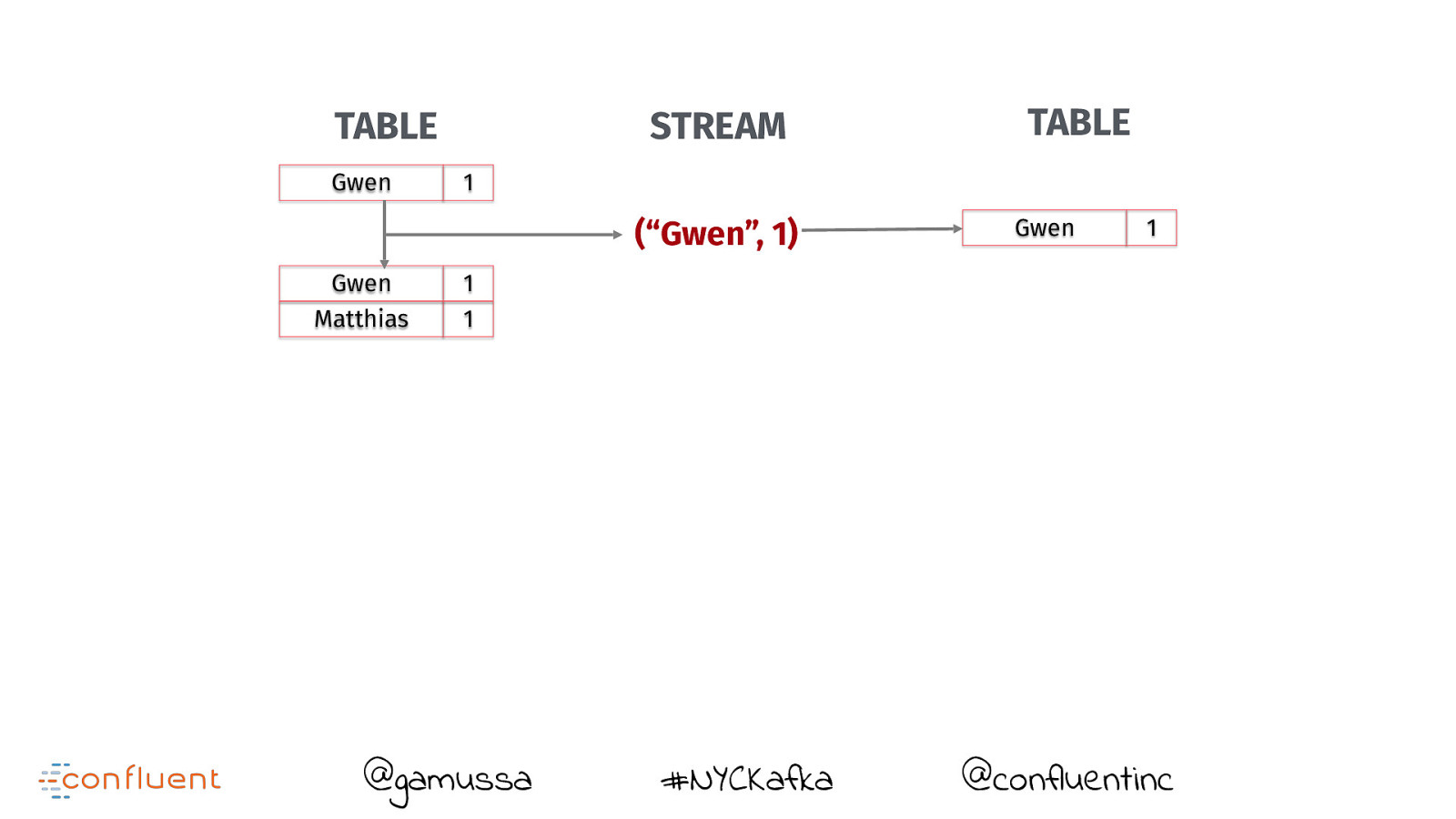
TABLE Gwen STREAM TABLE 1 (“Gwen”, 1) @gamussa #NYCKafka Gwen 1 @confluentinc
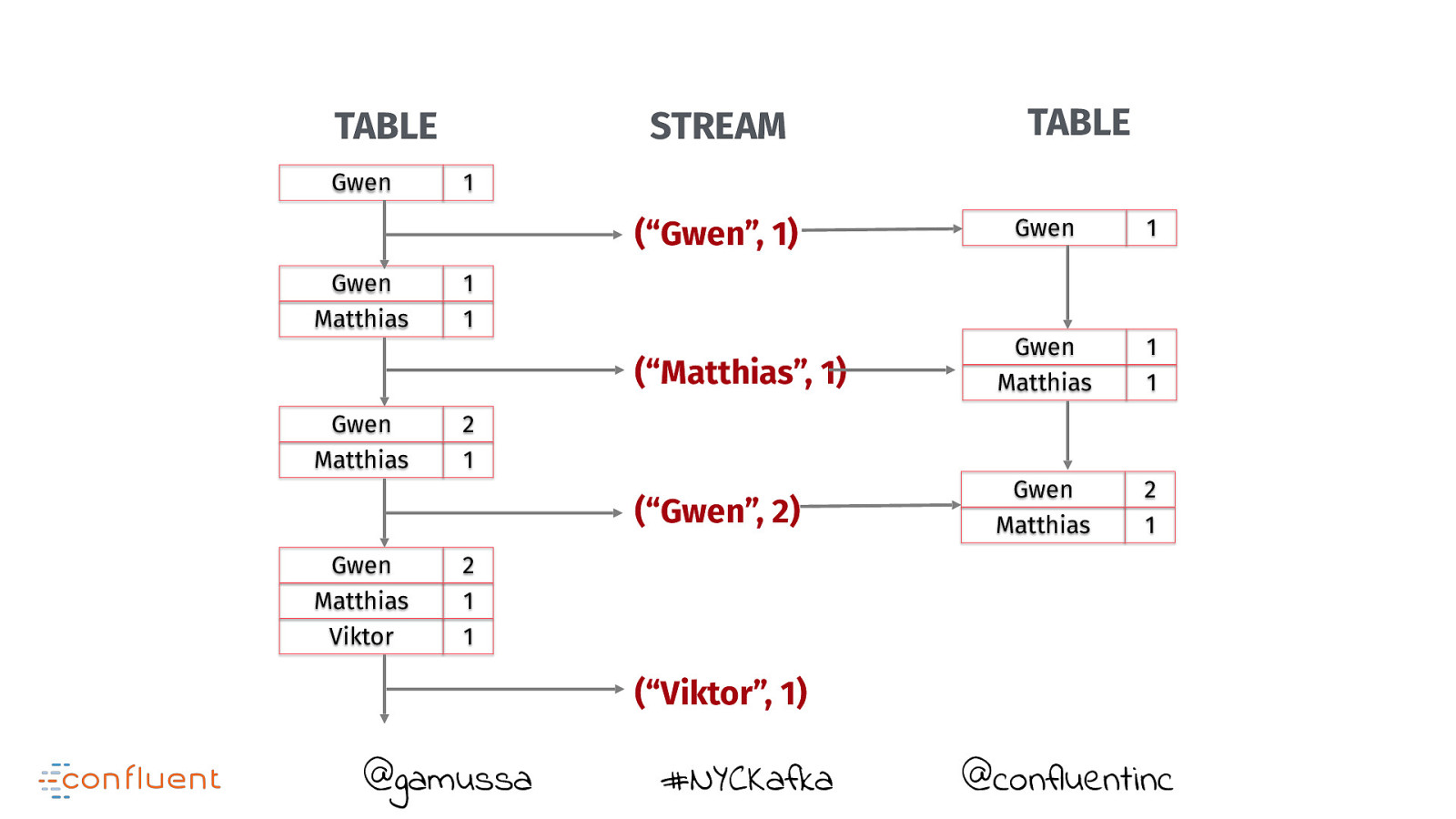
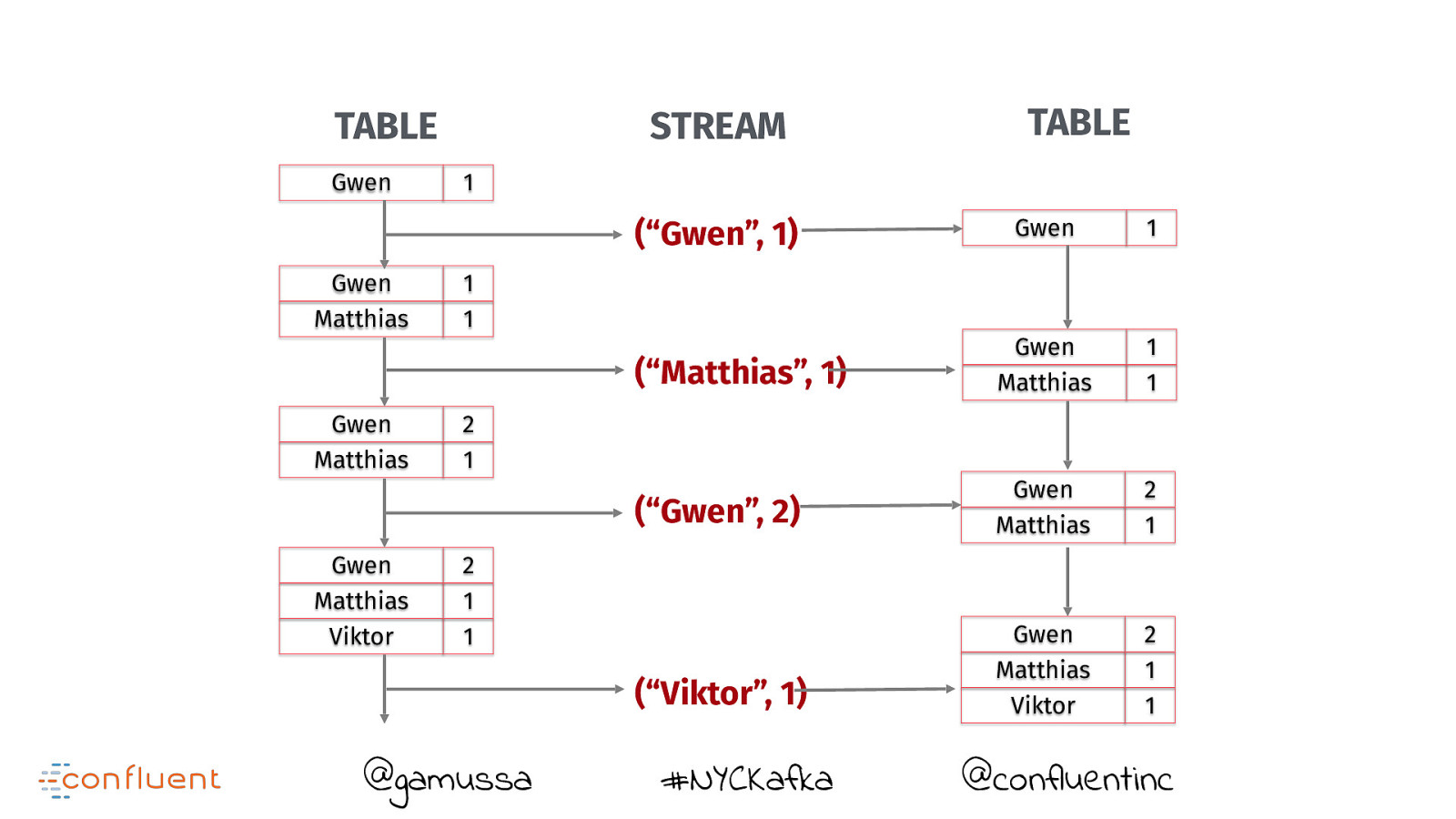
TABLE Gwen STREAM 1 (“Gwen”, 1) Gwen Matthias TABLE Gwen 1 1 1 @gamussa #NYCKafka @confluentinc
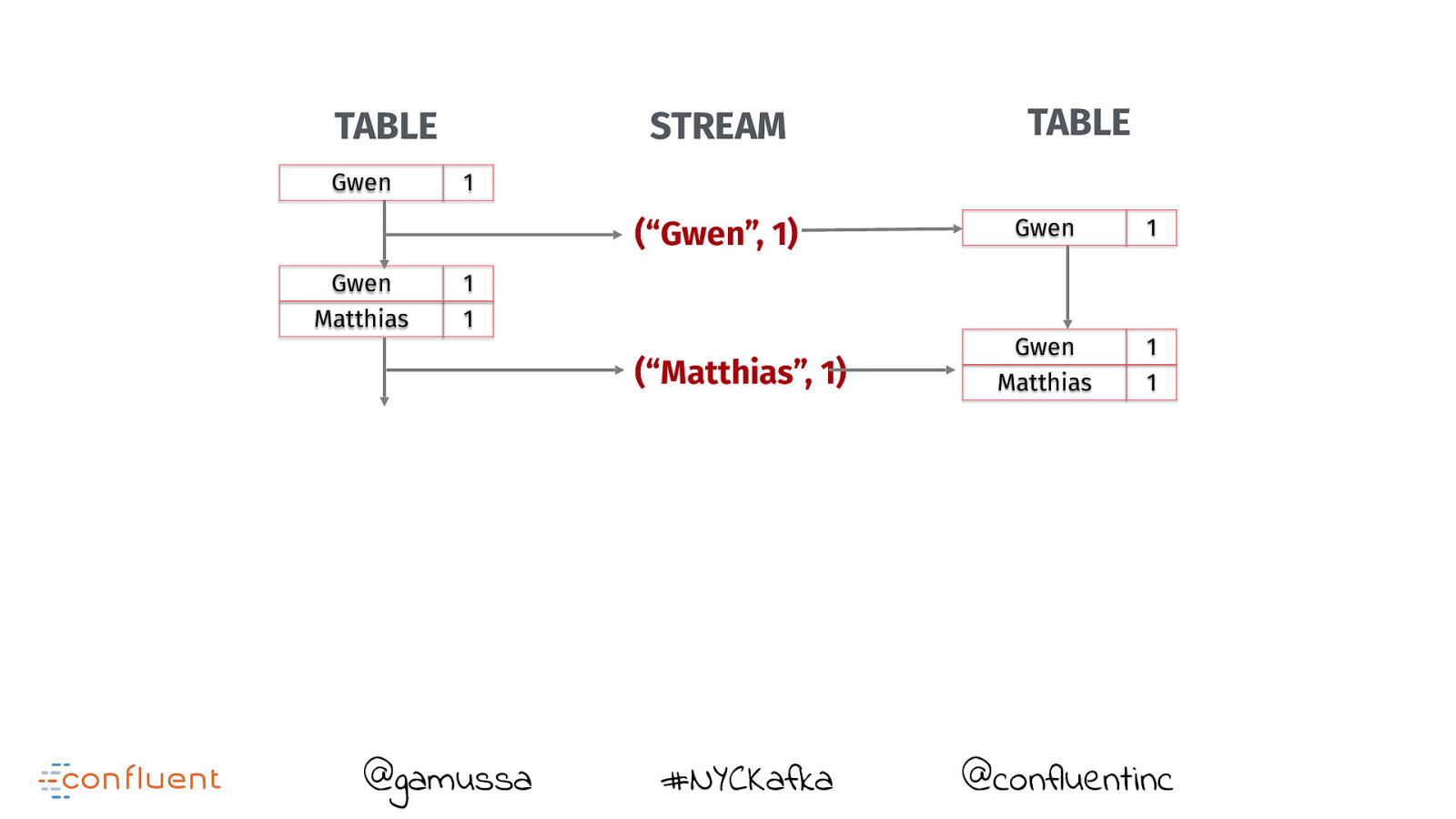
TABLE Gwen STREAM 1 (“Gwen”, 1) Gwen Matthias TABLE 1 1 (“Matthias”, 1) @gamussa #NYCKafka Gwen 1 Gwen Matthias 1 1 @confluentinc
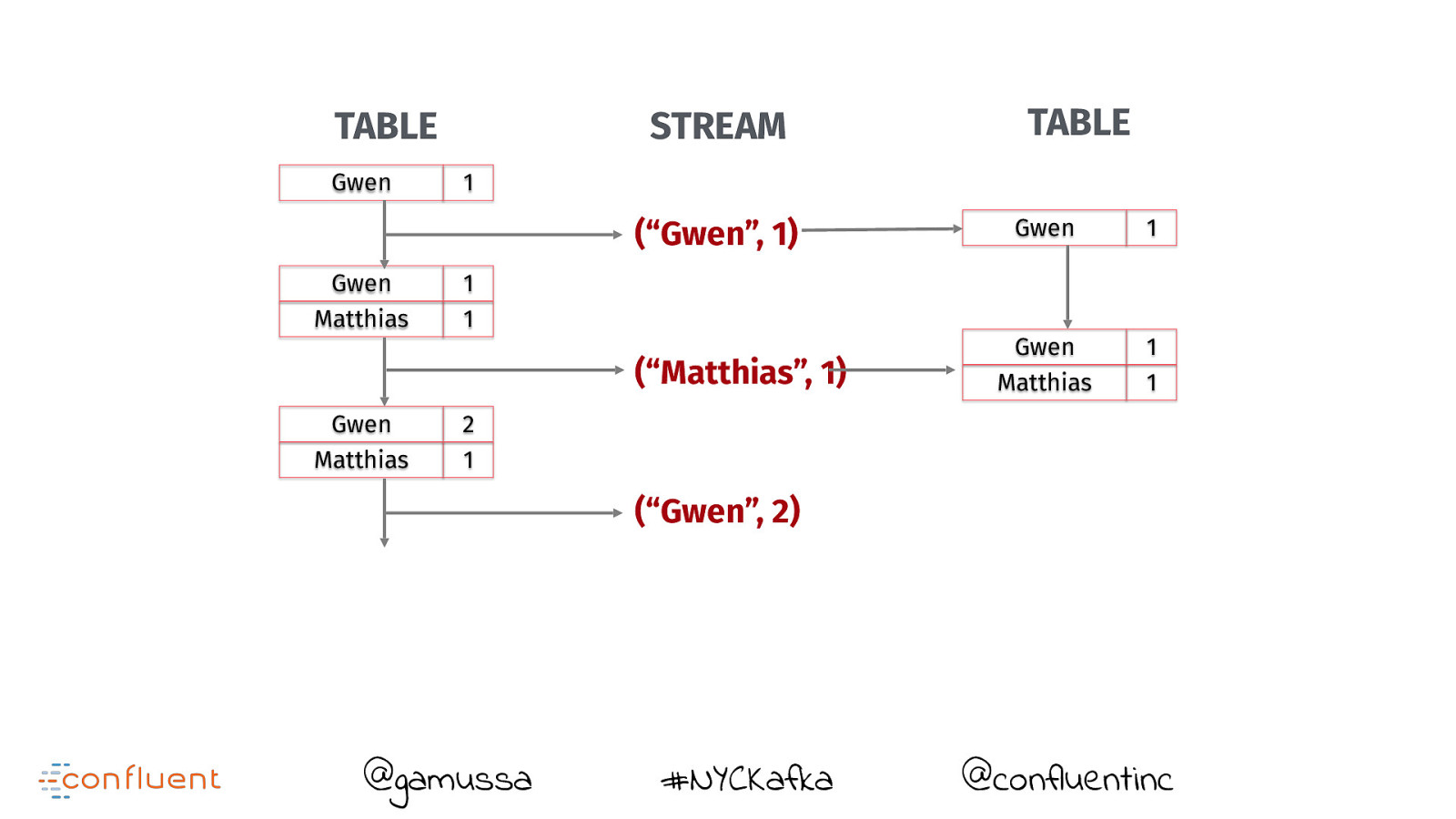
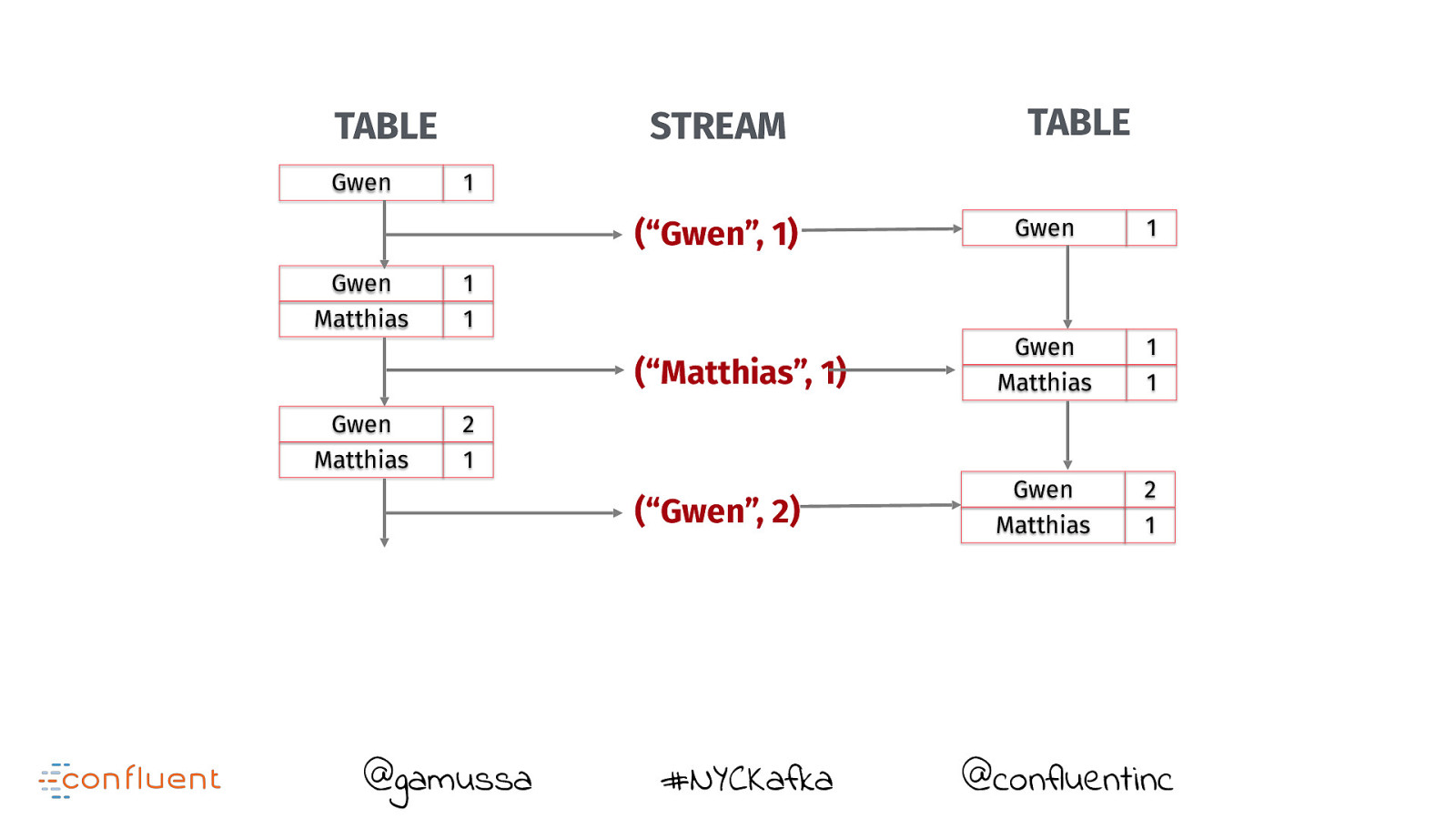
TABLE Gwen STREAM 1 (“Gwen”, 1) Gwen Matthias 1 1 (“Matthias”, 1) Gwen Matthias TABLE Gwen 1 Gwen Matthias 1 1 2 1 (“Gwen”, 2) @gamussa #NYCKafka @confluentinc
TABLE Gwen STREAM 1 Gwen 1 (“Matthias”, 1) Gwen Matthias 1 1 (“Gwen”, 2) Gwen Matthias 2 1 (“Gwen”, 1) Gwen Matthias Gwen Matthias TABLE 1 1 2 1 @gamussa #NYCKafka @confluentinc
TABLE Gwen STREAM 1 Gwen 1 (“Matthias”, 1) Gwen Matthias 1 1 (“Gwen”, 2) Gwen Matthias 2 1 (“Gwen”, 1) Gwen Matthias Gwen Matthias Gwen Matthias Viktor TABLE 1 1 2 1 2 1 1 (“Viktor”, 1) @gamussa #NYCKafka @confluentinc
TABLE Gwen STREAM 1 Gwen 1 (“Matthias”, 1) Gwen Matthias 1 1 (“Gwen”, 2) Gwen Matthias 2 1 (“Viktor”, 1) Gwen Matthias Viktor 2 1 1 (“Gwen”, 1) Gwen Matthias Gwen Matthias Gwen Matthias Viktor TABLE 1 1 2 1 2 1 1 @gamussa #NYCKafka @confluentinc
Do you think that’s a table you are querying ?
Talk is cheap! Show me code!
What’s next?
https://twitter.com/IDispose/status/1048602857191170054
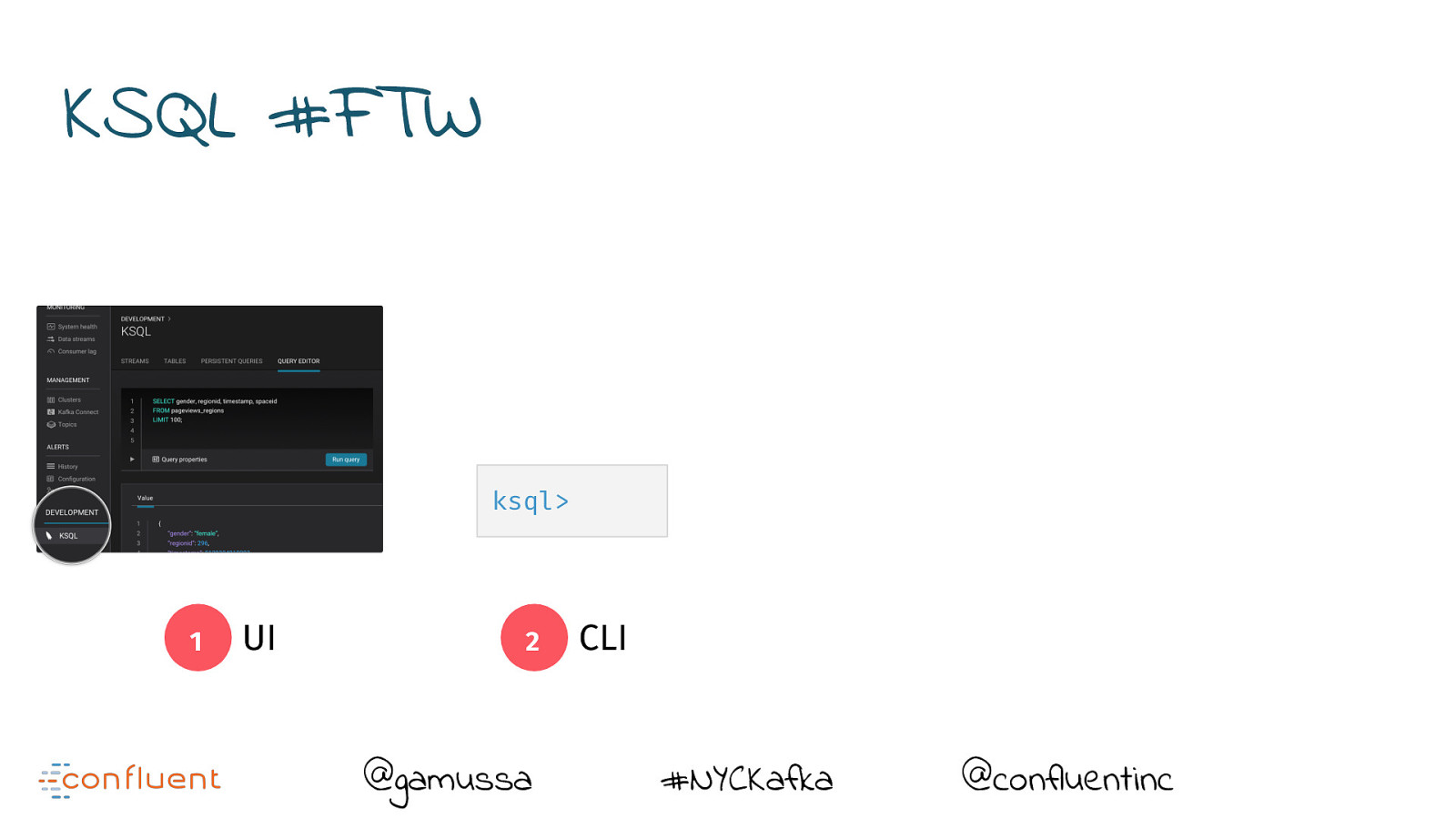
KSQL #FTW @gamussa #NYCKafka @confluentinc
KSQL #FTW 1 UI @gamussa #NYCKafka @confluentinc
KSQL #FTW ksql> 1 UI 2 @gamussa CLI #NYCKafka @confluentinc
KSQL #FTW ksql> 1 UI 2 @gamussa POST /query CLI 3 #NYCKafka REST @confluentinc
KSQL #FTW ksql> 1 UI 2 @gamussa POST /query CLI 3 #NYCKafka REST 4 @confluentinc Headless
Interaction with Kafka Kafka (data) @gamussa #NYCKafka @confluentinc
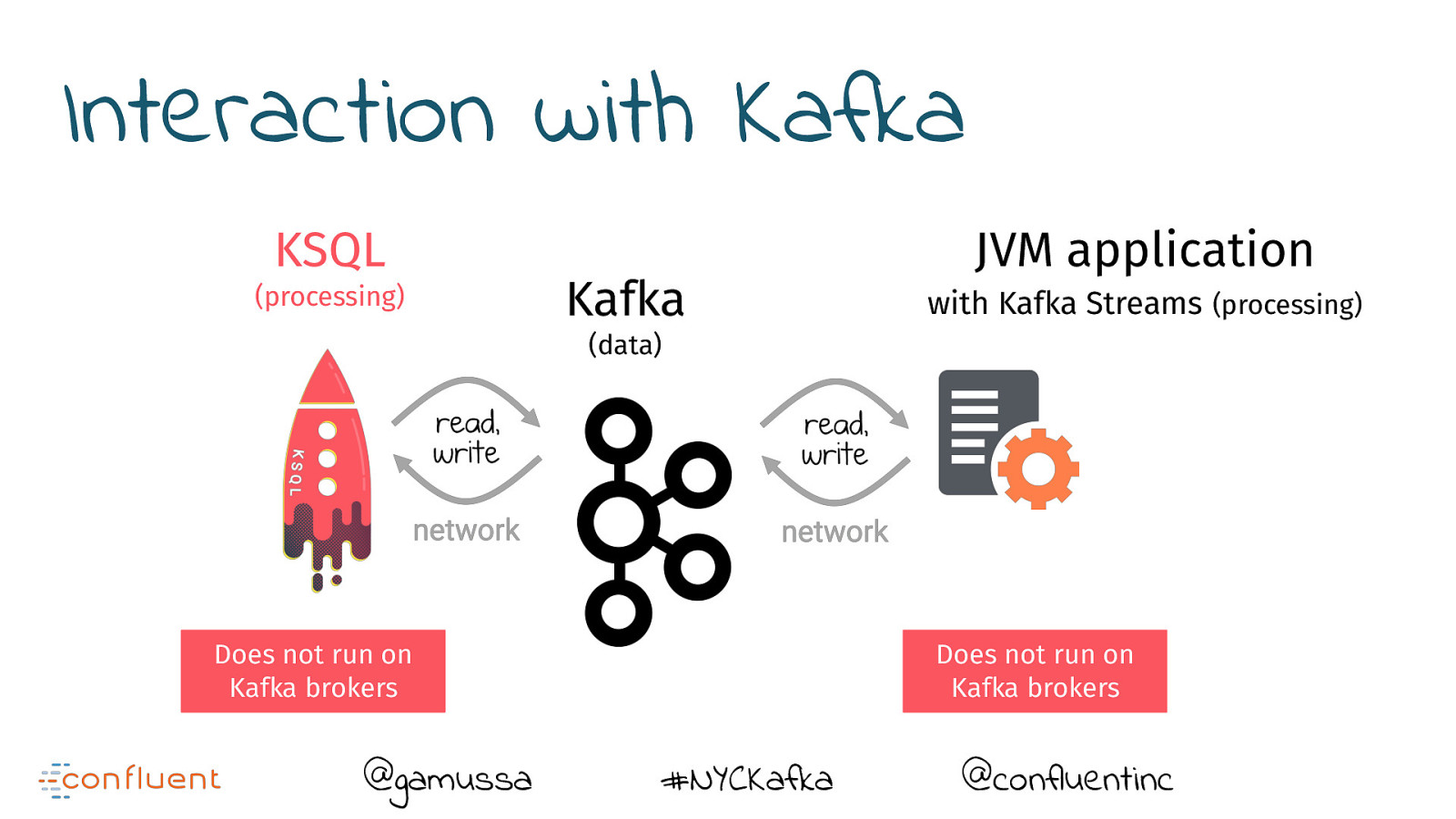
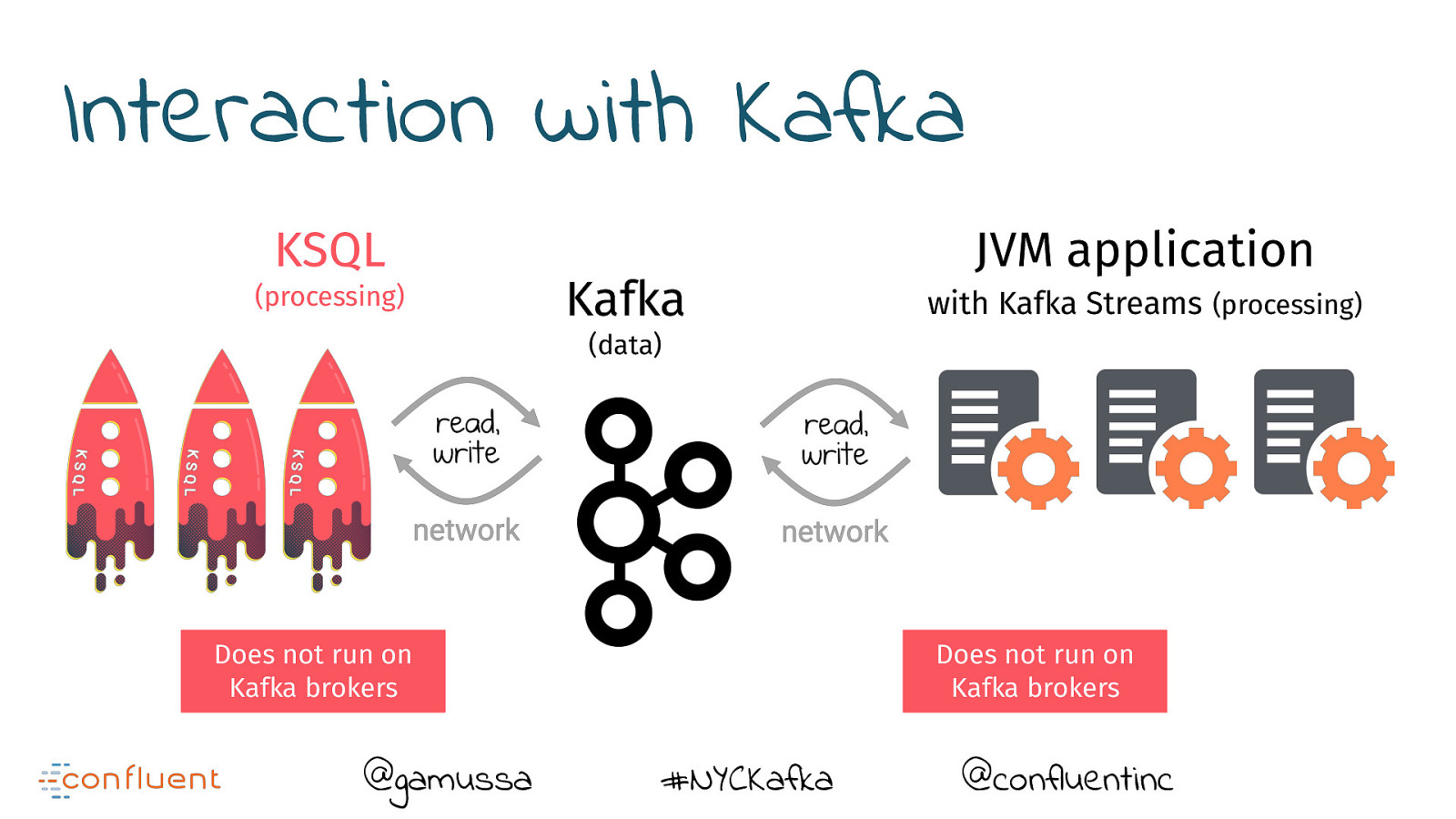
Interaction with Kafka KSQL (processing) Kafka JVM application with Kafka Streams (processing) (data) Does not run on Kafka brokers @gamussa Does not run on Kafka brokers #NYCKafka @confluentinc
Interaction with Kafka KSQL (processing) Kafka JVM application with Kafka Streams (processing) (data) Does not run on Kafka brokers @gamussa Does not run on Kafka brokers #NYCKafka @confluentinc
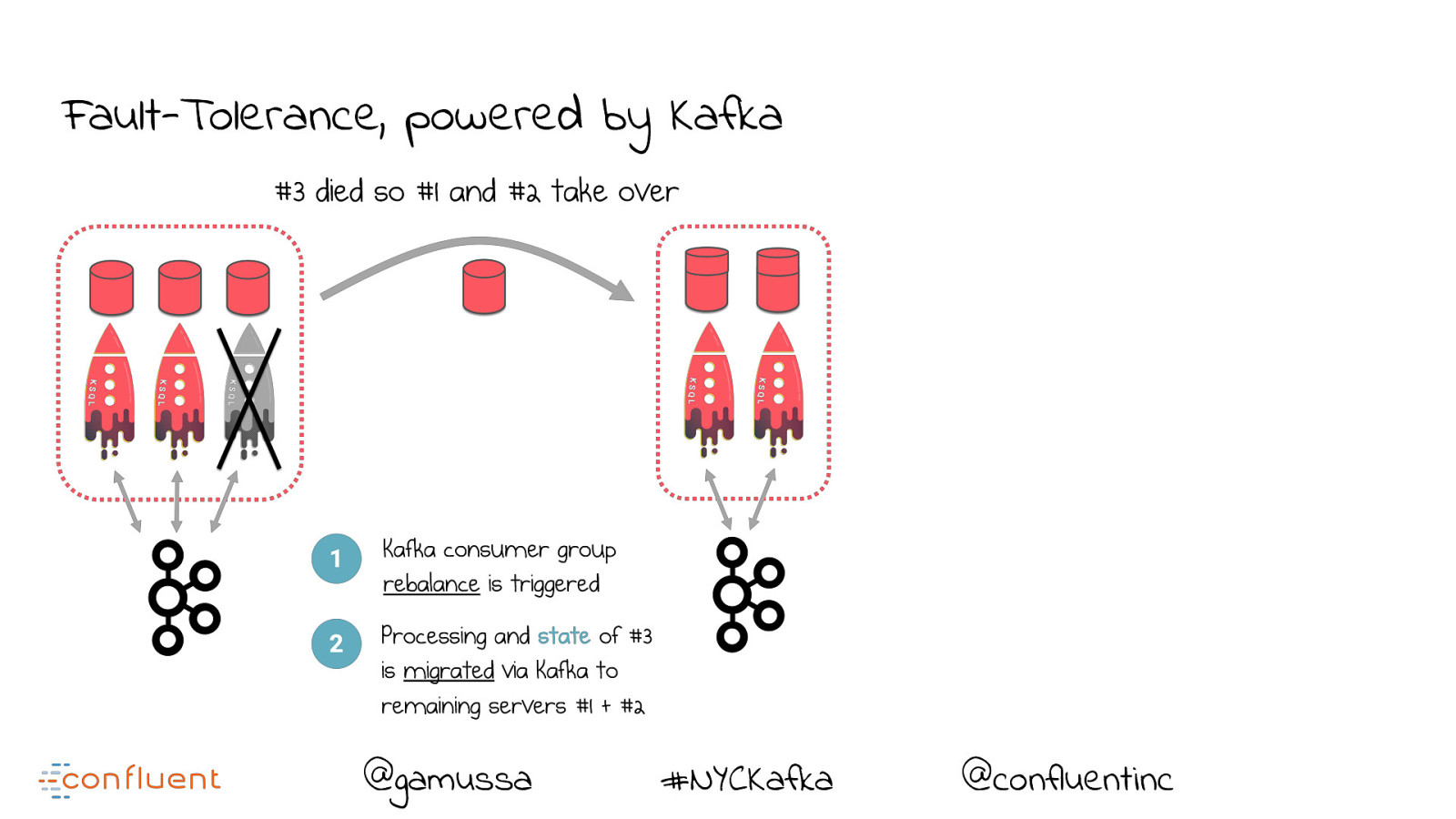
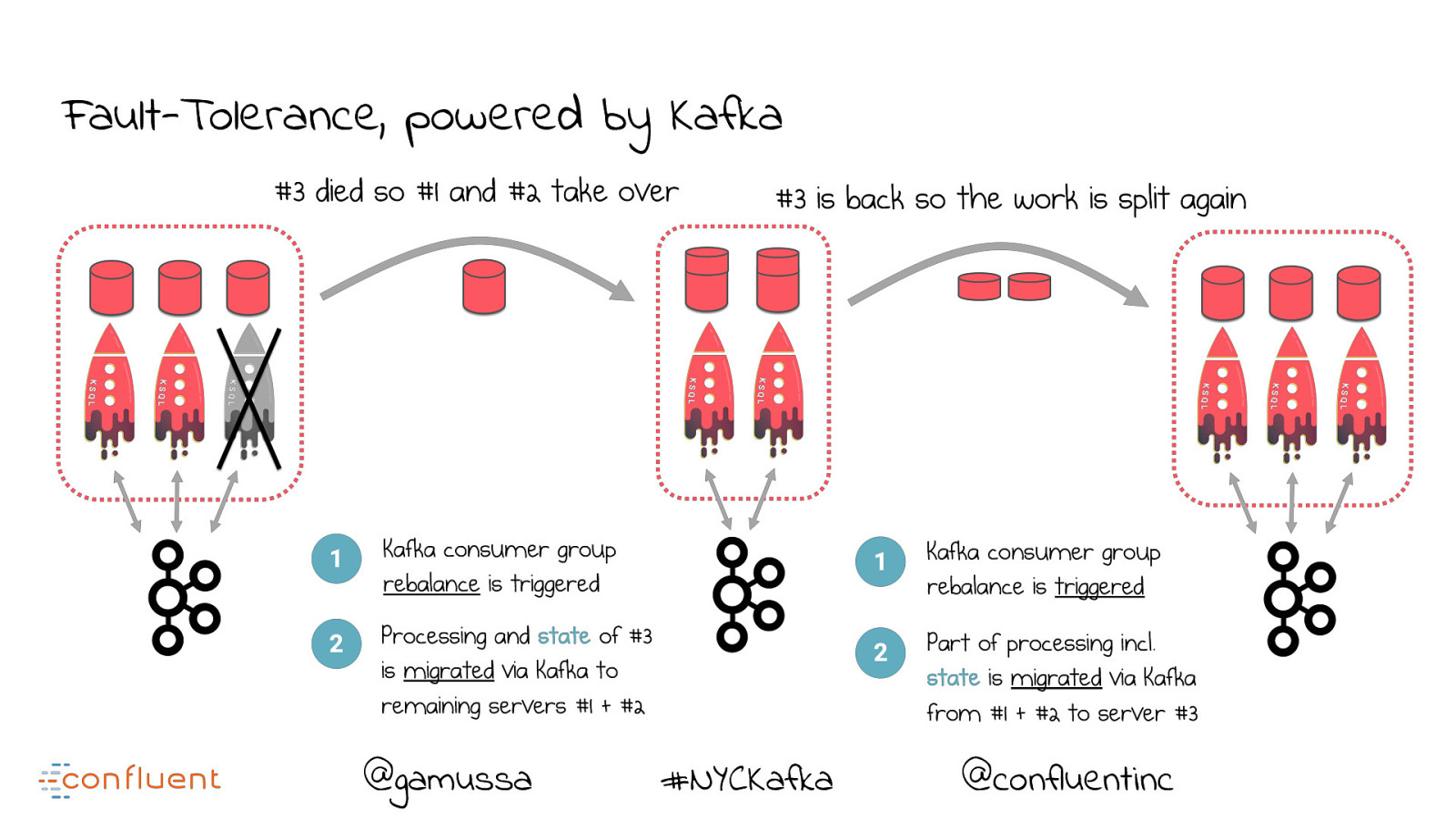
Fault-Tolerance, powered by Kafka @gamussa #NYCKafka @confluentinc
Fault-Tolerance, powered by Kafka @gamussa #NYCKafka @confluentinc
Fault-Tolerance, powered by Kafka @gamussa #NYCKafka @confluentinc
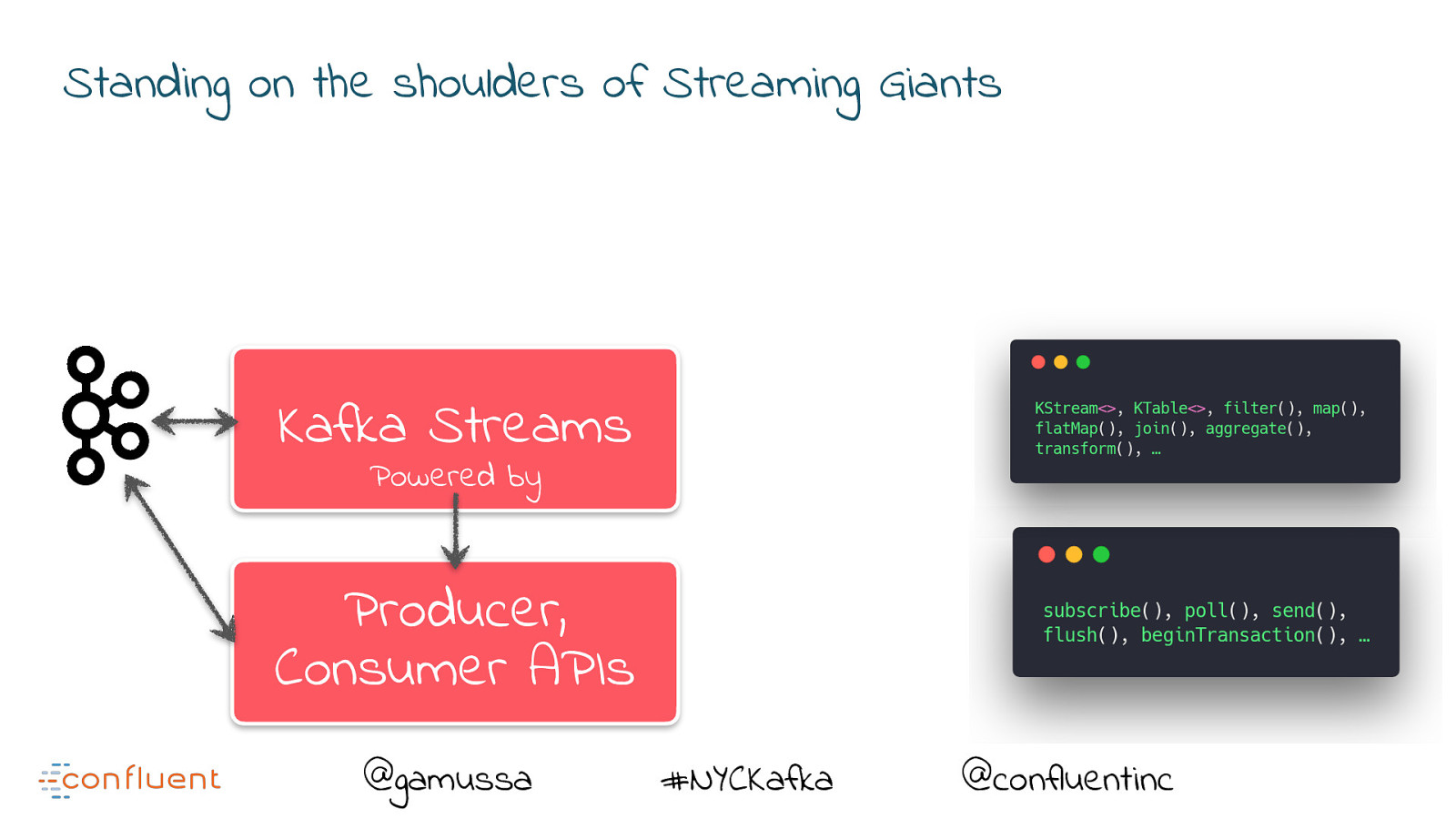
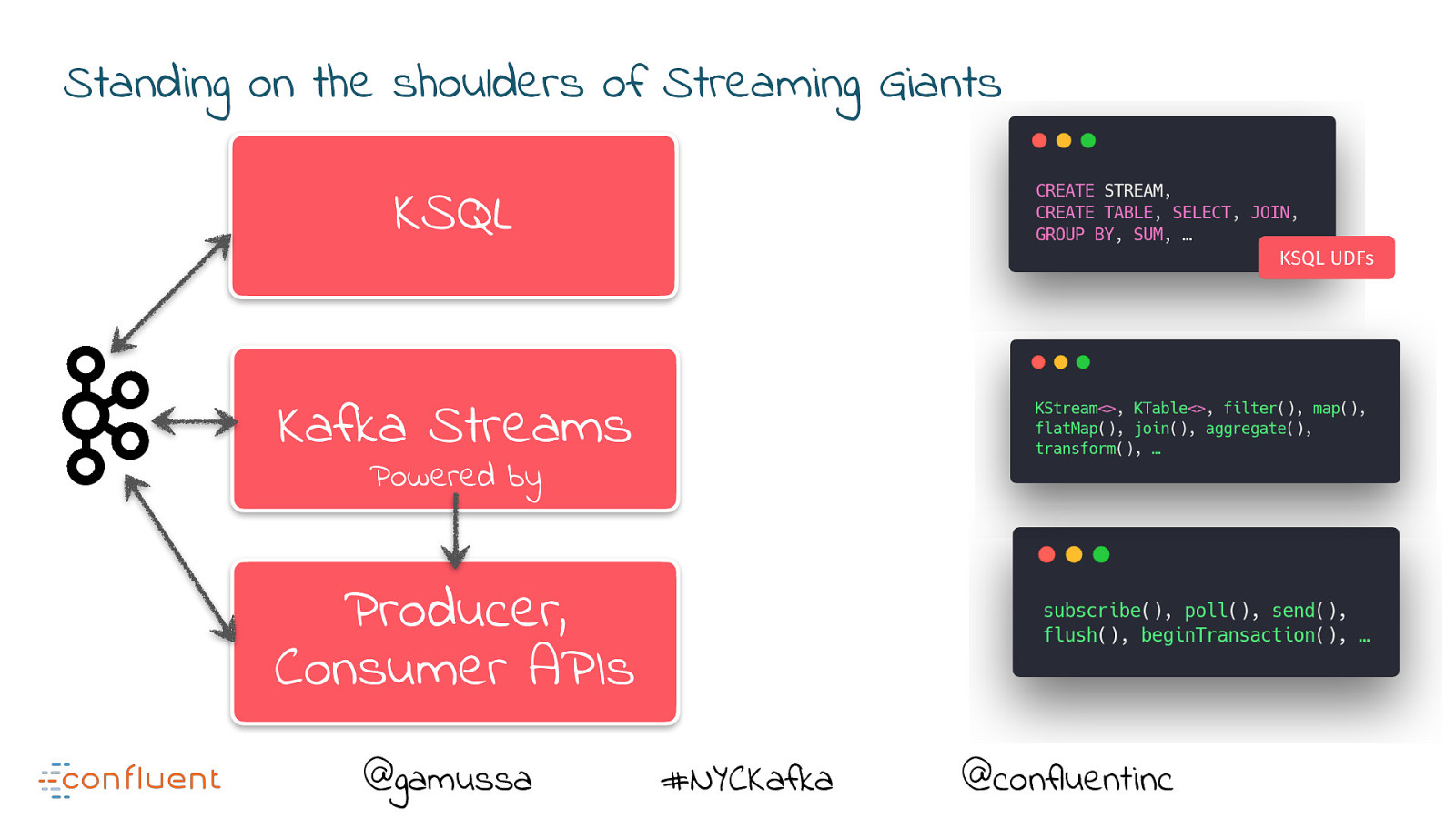
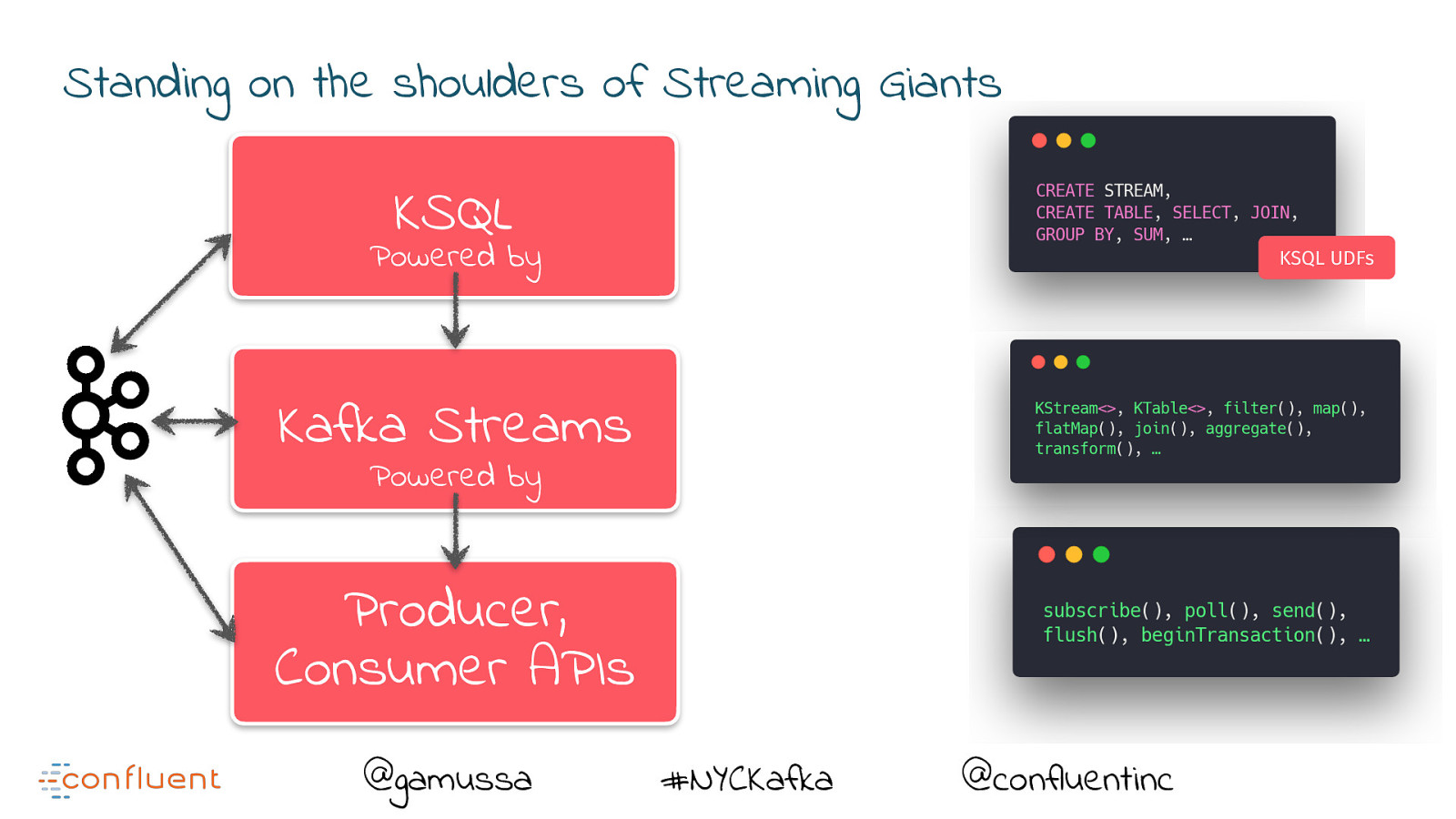
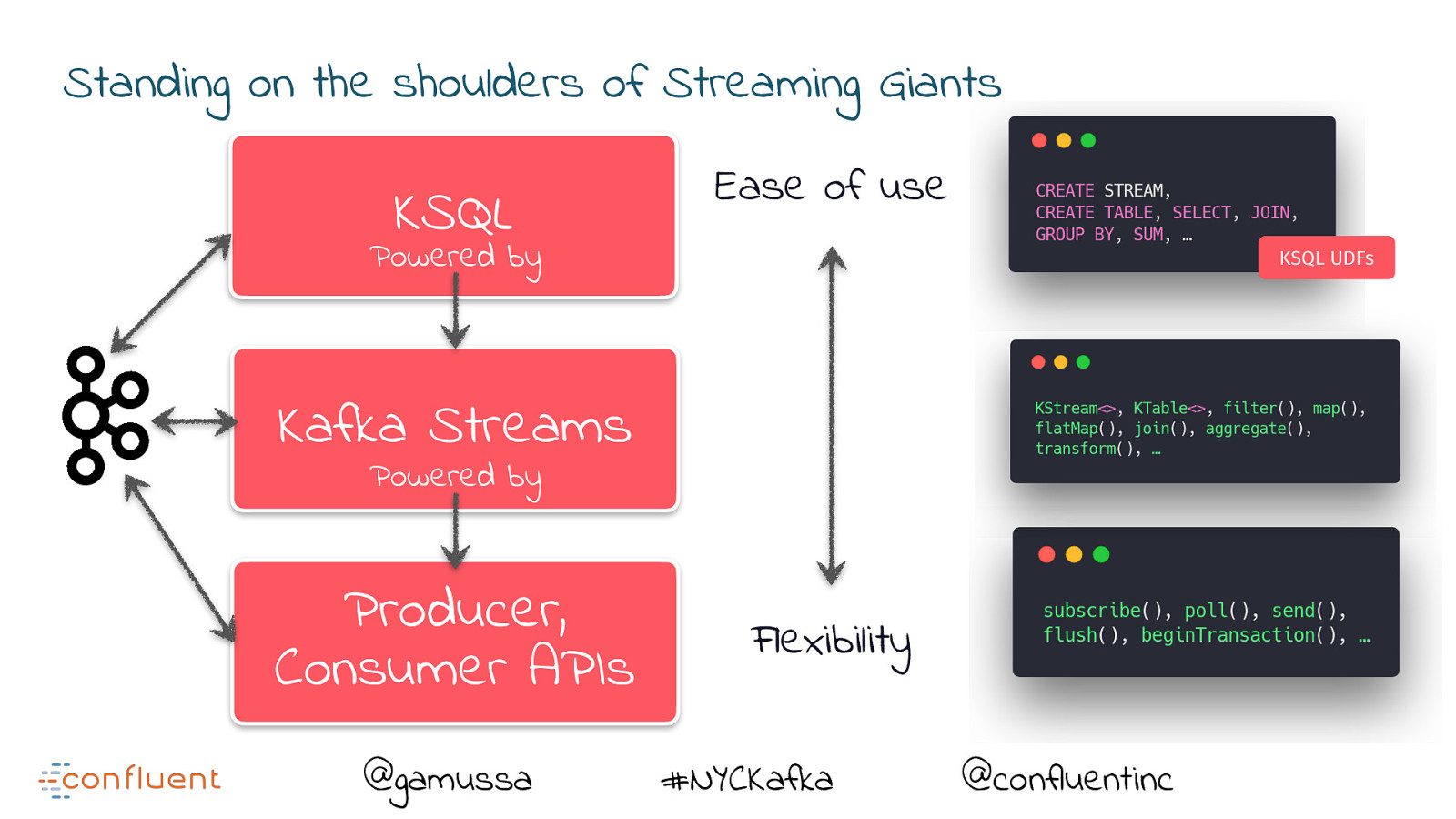
Standing on the shoulders of Streaming Giants @gamussa #NYCKafka @confluentinc
Standing on the shoulders of Streaming Giants @gamussa #NYCKafka @confluentinc
Standing on the shoulders of Streaming Giants Producer, Consumer APIs @gamussa #NYCKafka @confluentinc
Standing on the shoulders of Streaming Giants Kafka Streams Producer, Consumer APIs @gamussa #NYCKafka @confluentinc
Standing on the shoulders of Streaming Giants Kafka Streams Powered by Producer, Consumer APIs @gamussa #NYCKafka @confluentinc
Standing on the shoulders of Streaming Giants KSQL KSQL UDFs Kafka Streams Powered by Producer, Consumer APIs @gamussa #NYCKafka @confluentinc
Standing on the shoulders of Streaming Giants KSQL Powered by KSQL UDFs Kafka Streams Powered by Producer, Consumer APIs @gamussa #NYCKafka @confluentinc
Standing on the shoulders of Streaming Giants KSQL Ease of use Powered by KSQL UDFs Kafka Streams Powered by Producer, Consumer APIs @gamussa Flexibility #NYCKafka @confluentinc
One last thing…
https://kafka-summit.org Gamov30 @gamussa #NYCKafka @ @confluentinc
Thanks! @gamussa viktor@confluent.io We are hiring! https://www.confluent.io/careers/ @gamussa #NYCKafka @ @confluentinc

All things change constantly! And dealing with constantly changing data at low latency is pretty hard. It doesn’t need to be that way. Apache Kafka, the de facto standard open-source distributed stream processing system. Many of us know Kafka’s architectural and pub/sub API particulars. But that doesn’t mean we’re equipped to build the kind of real-time streaming data systems that the next generation of business requirements are doing to demand. We need to get on board with streams!
Viktor Gamov will introduce Kafka Streams and KSQL—an important recent addition to the Confluent platform that lets you build sophisticated stream processing systems with little to no code at all! He will talk about how to deploy stream processing applications and look at the actual working code that will bring your thinking about streaming data systems from the ancient history of batch processing into the current era of streaming data!
The following code examples from the presentation can be tried out live.
The following resources were mentioned during the presentation or are useful additional information.
Here’s what was said about this presentation on social media.