A presentation at Cloud-Native Data Day in in Boston, MA, USA by Viktor Gamov

Cloud-Native Streaming Platform: Apache Kafka Meets Kubernetes @gamussa #BOSDataDay @confluentinc
#devkafkaops @gamussa #BOSDataDay @ @confluentinc
@gamussa #BOSDataDay @confluentinc
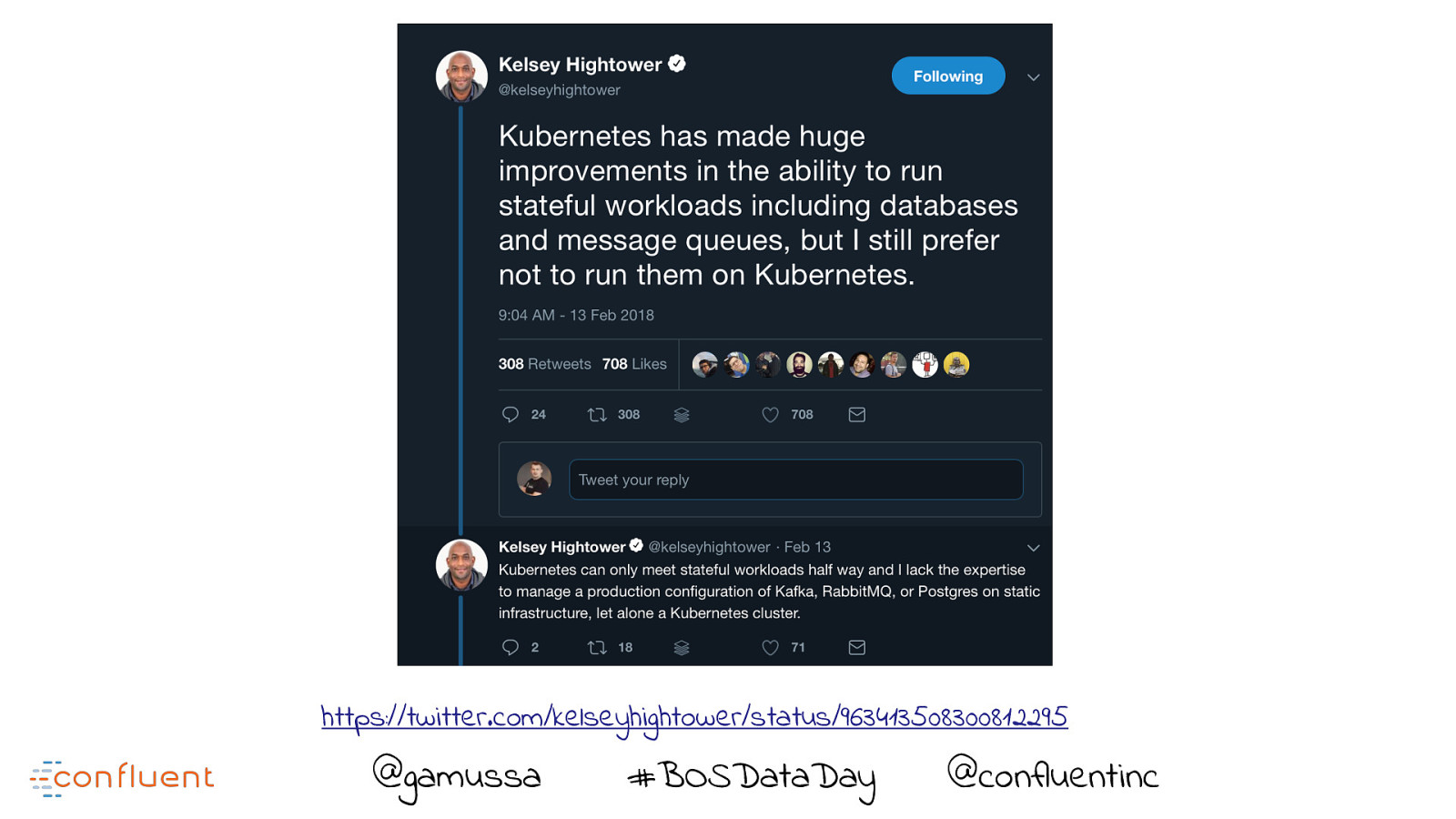
https://twitter.com/kelseyhightower/status/963413508300812295 @gamussa #BOSDataDay @ @confluentinc
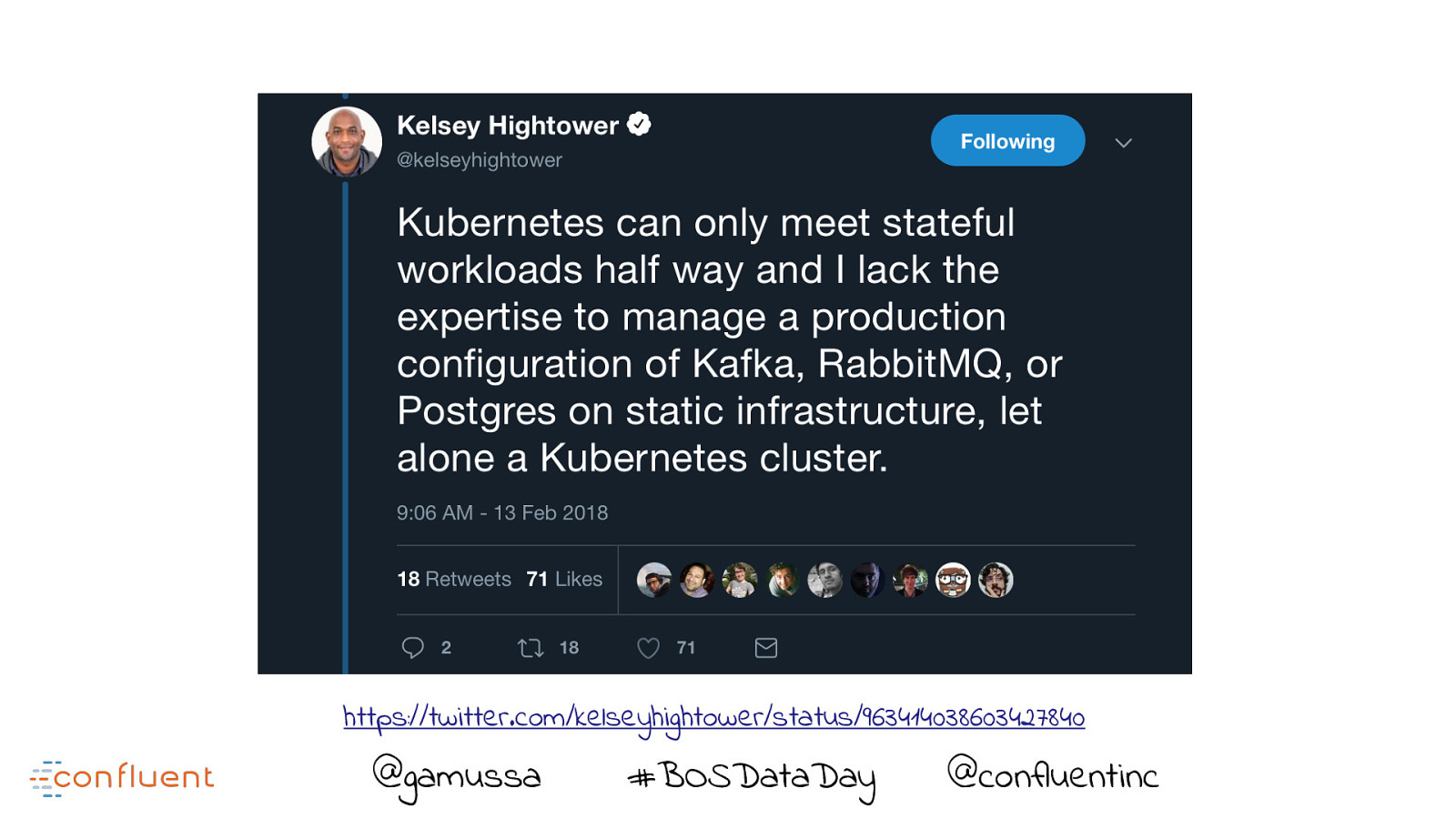
https://twitter.com/kelseyhightower/status/963414038603427840 @gamussa #BOSDataDay @ @confluentinc
Don’t despair… “… not even over the fact that you don't despair. Just when everything seems over with, new forces come marching up, and precisely that means that you are alive” Franz Kafka @gamussa #BOSDataDay @ @confluentinc
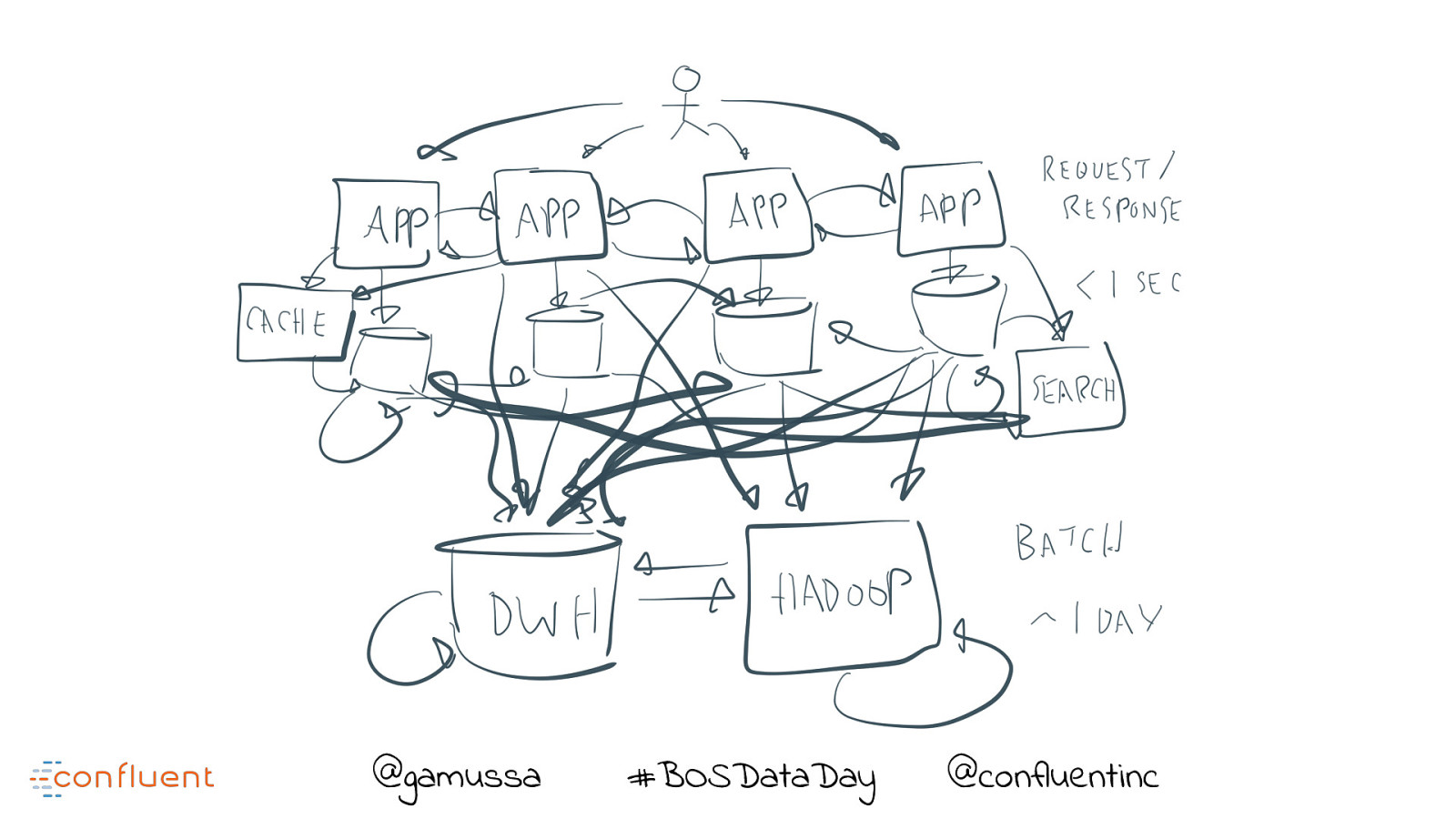
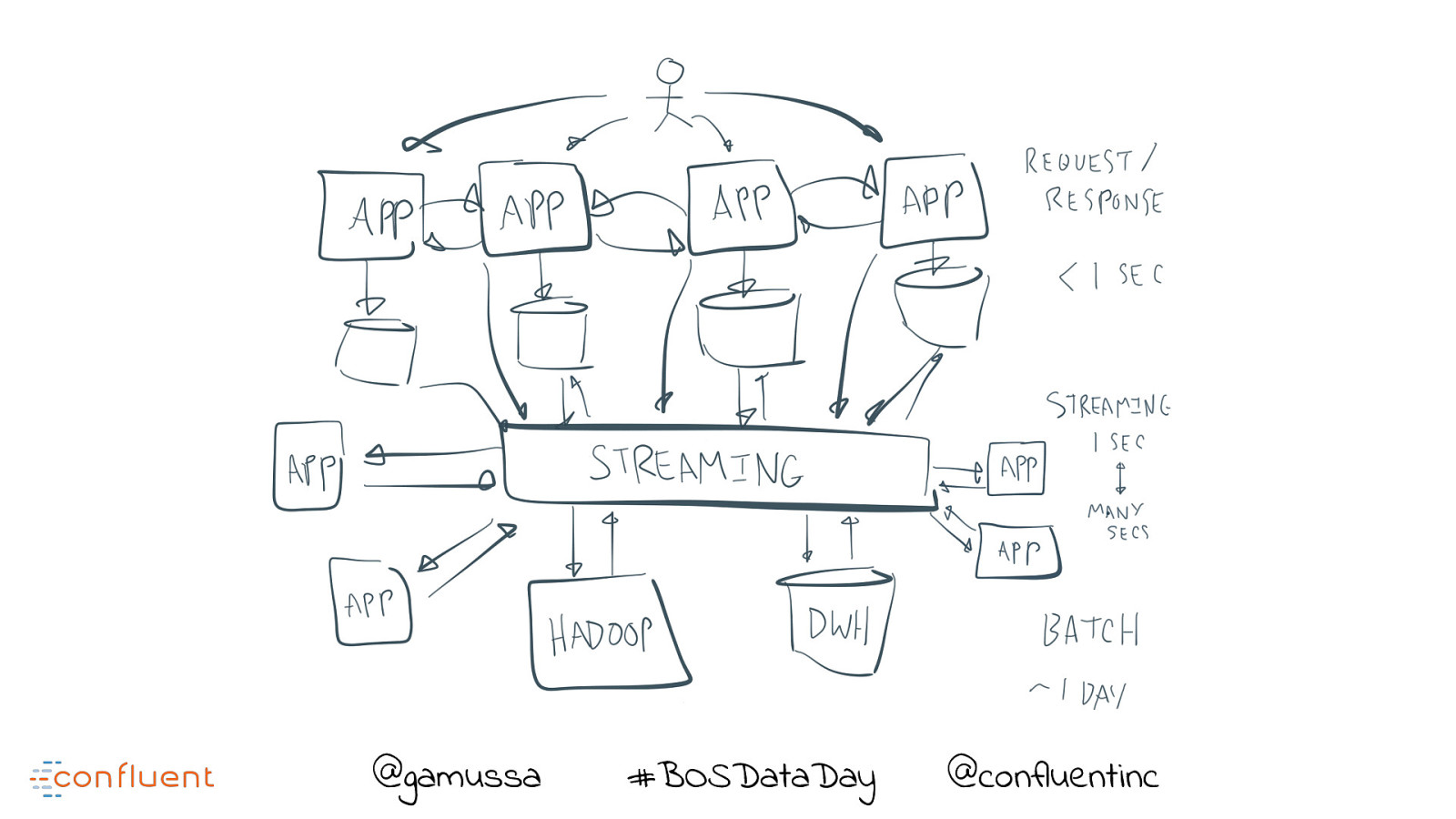
Kafka Streaming Architecture Fundamentals
@gamussa #BOSDataDay @ @confluentinc
@gamussa #BOSDataDay @ @confluentinc
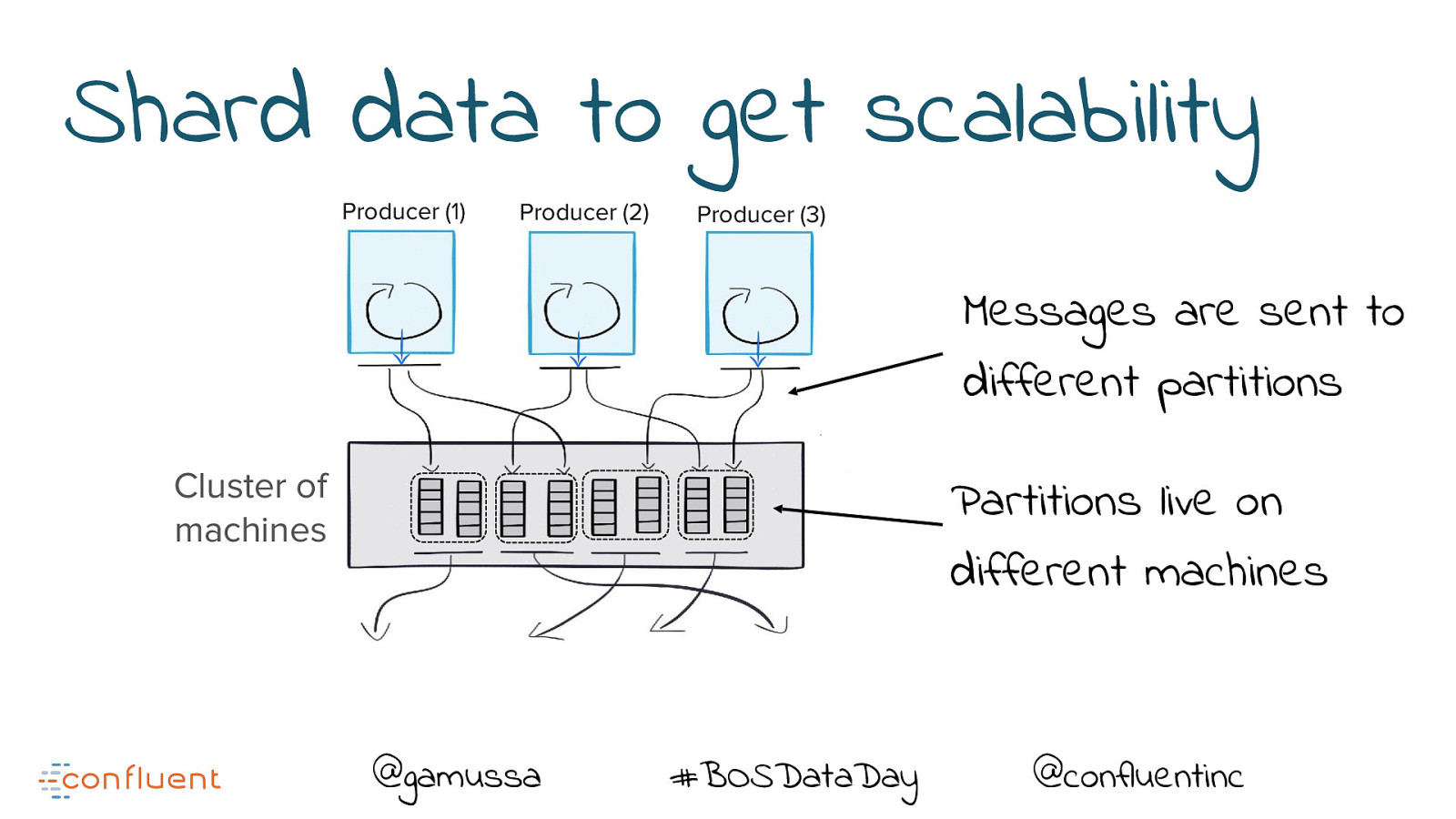
Shard data to get scalability Producer (1) Producer (2) Producer (3) Messages are sent to different partitions Cluster of machines Partitions live on different machines @gamussa #BOSDataDay @confluentinc
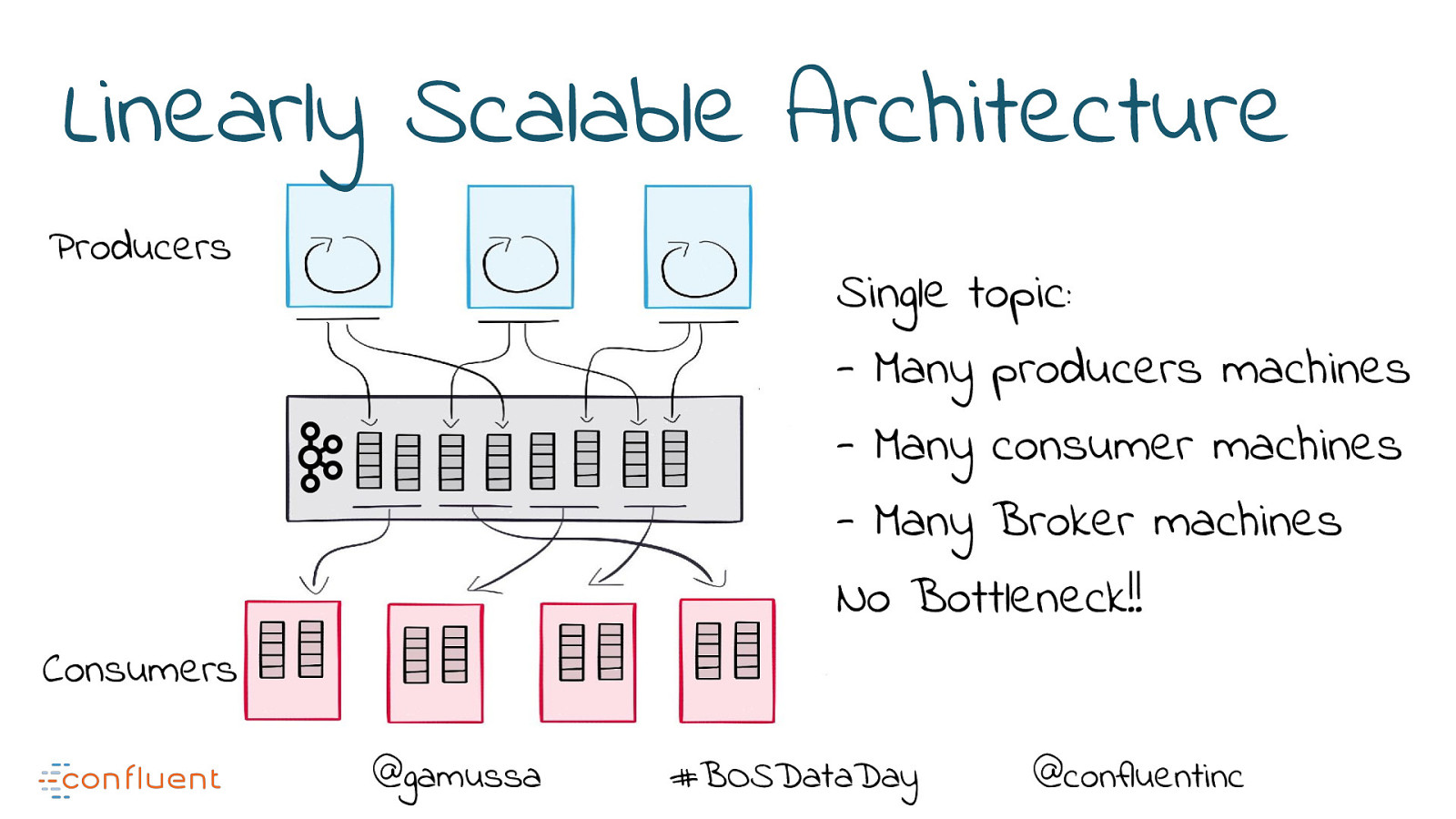
Linearly Scalable Architecture Producers Single topic: - Many producers machines - Many consumer machines - Many Broker machines No Bottleneck!! Consumers @gamussa #BOSDataDay @confluentinc
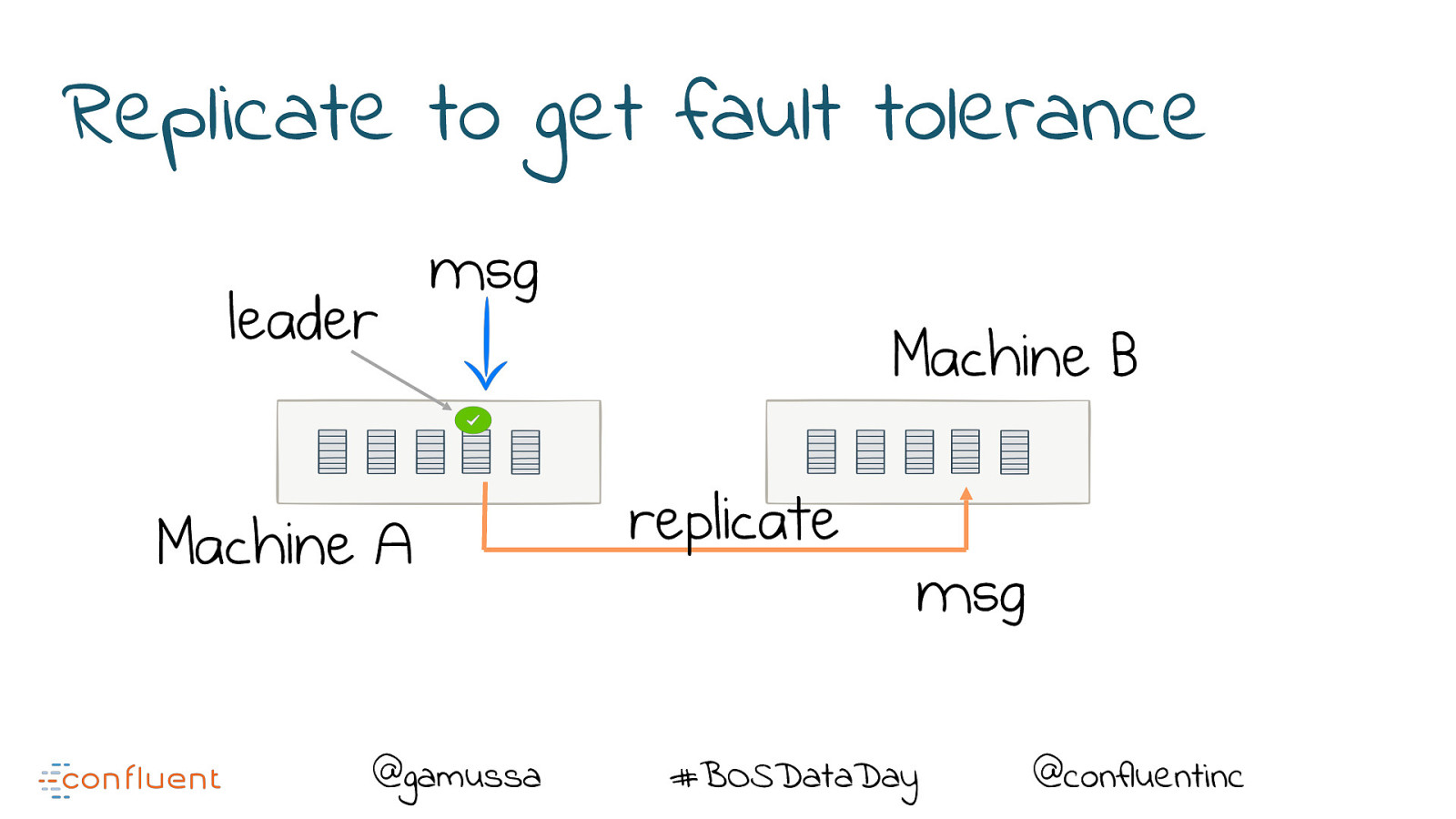
Replicate to get fault tolerance leader msg Machine A @gamussa Machine B replicate msg #BOSDataDay @confluentinc
Replication provides resiliency A ‘replica’ takes over on machine failure @gamussa #BOSDataDay @confluentinc
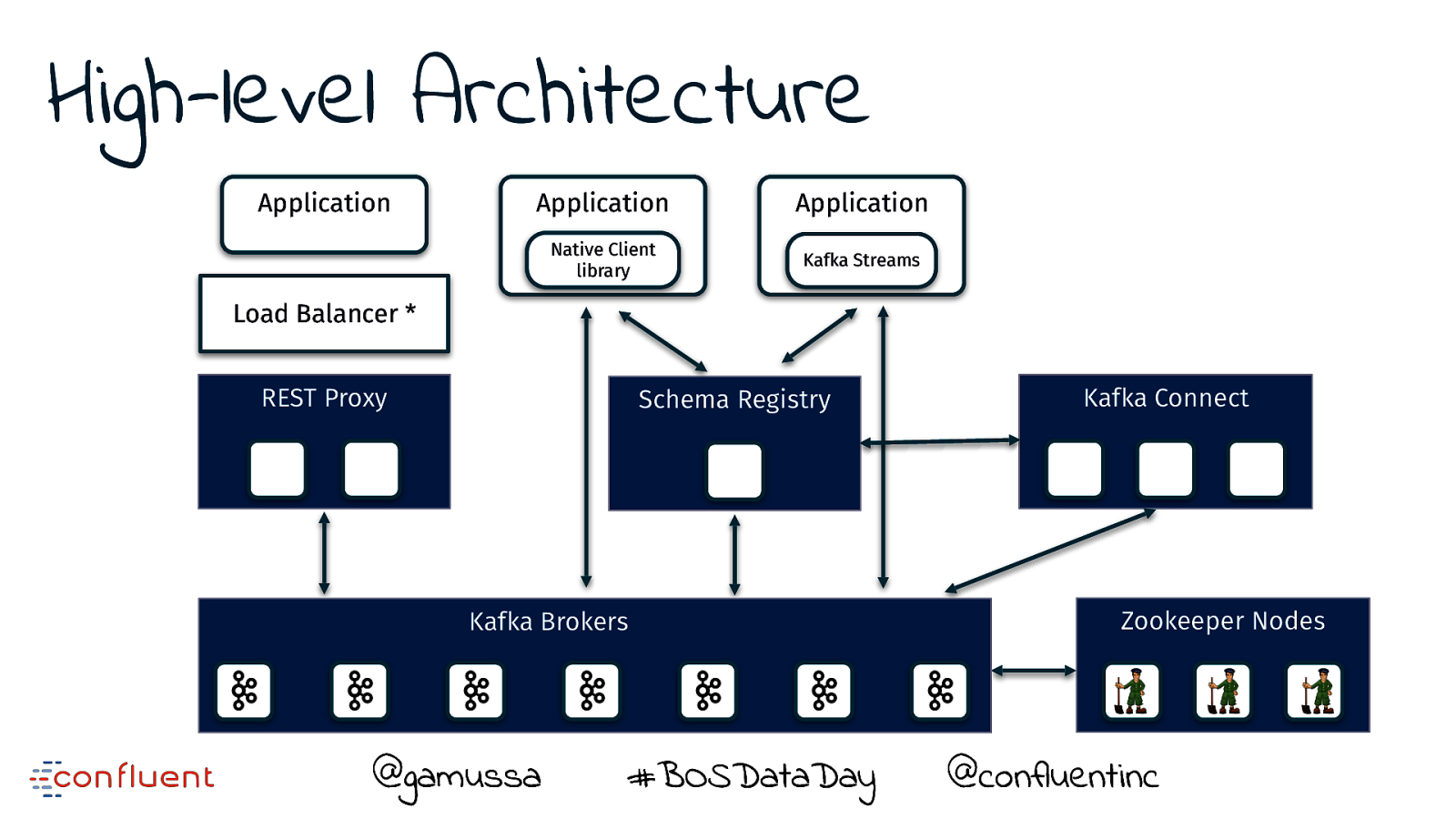
High-level Architecture Application Application Application Native Client library Kafka Streams Load Balancer * REST Proxy Schema Registry Zookeeper Nodes Kafka Brokers @gamussa Kafka Connect #BOSDataDay @ @confluentinc
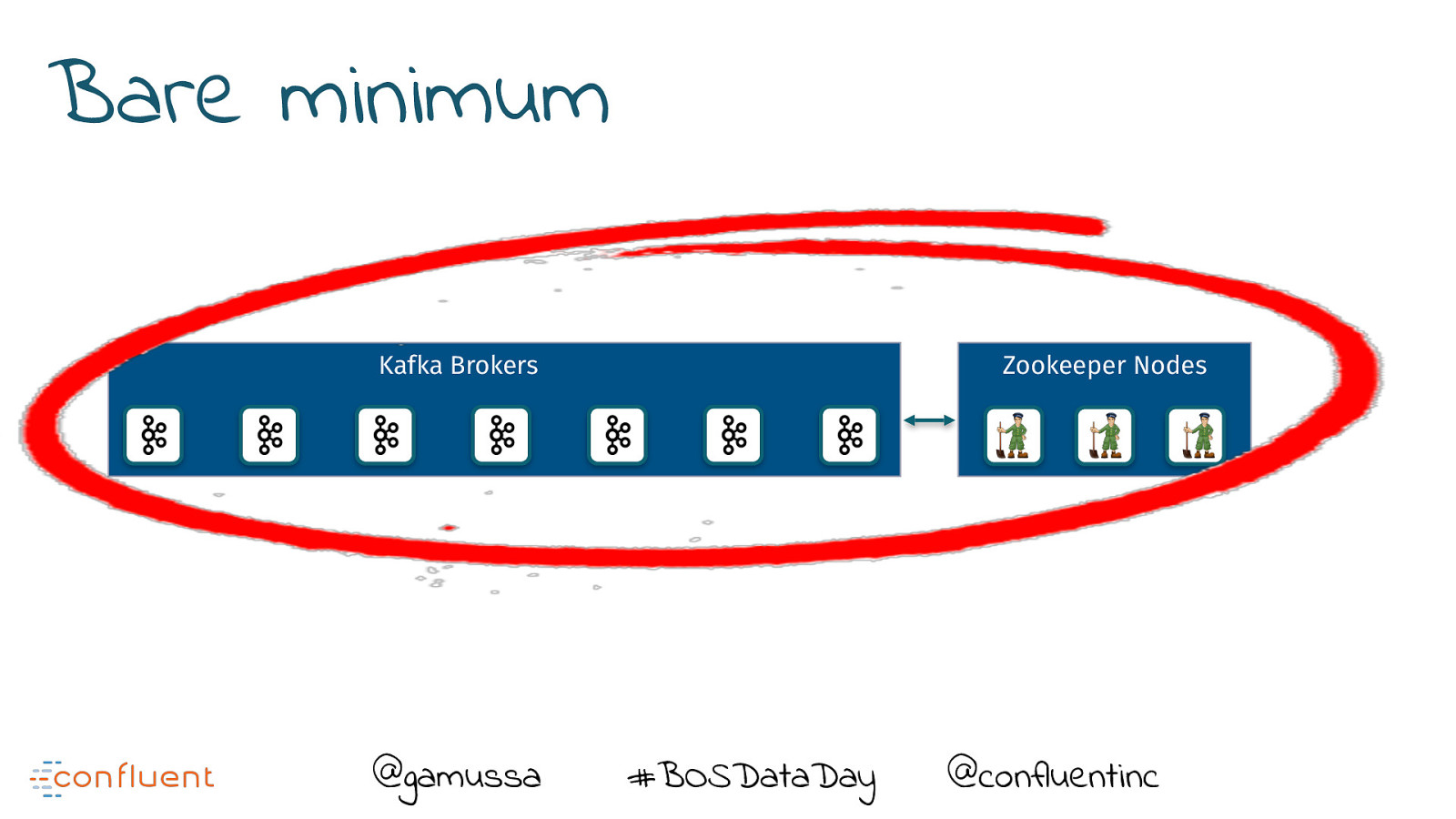
Bare minimum Kafka Brokers @gamussa Zookeeper Nodes #BOSDataDay @ @confluentinc
Workloads Deployment @gamussa #BOSDataDay @confluentinc
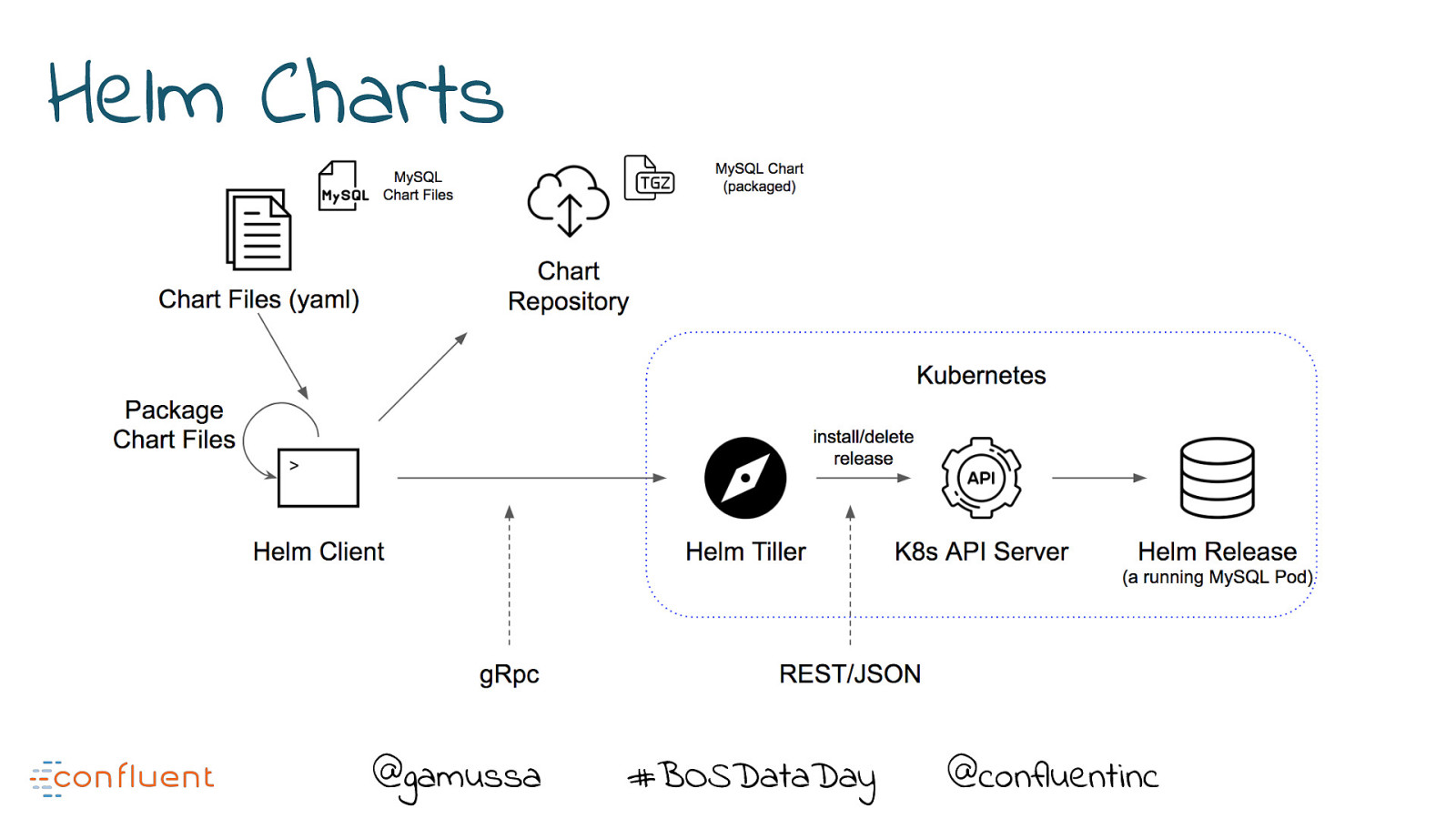
Helm Charts @gamussa #BOSDataDay @ @confluentinc
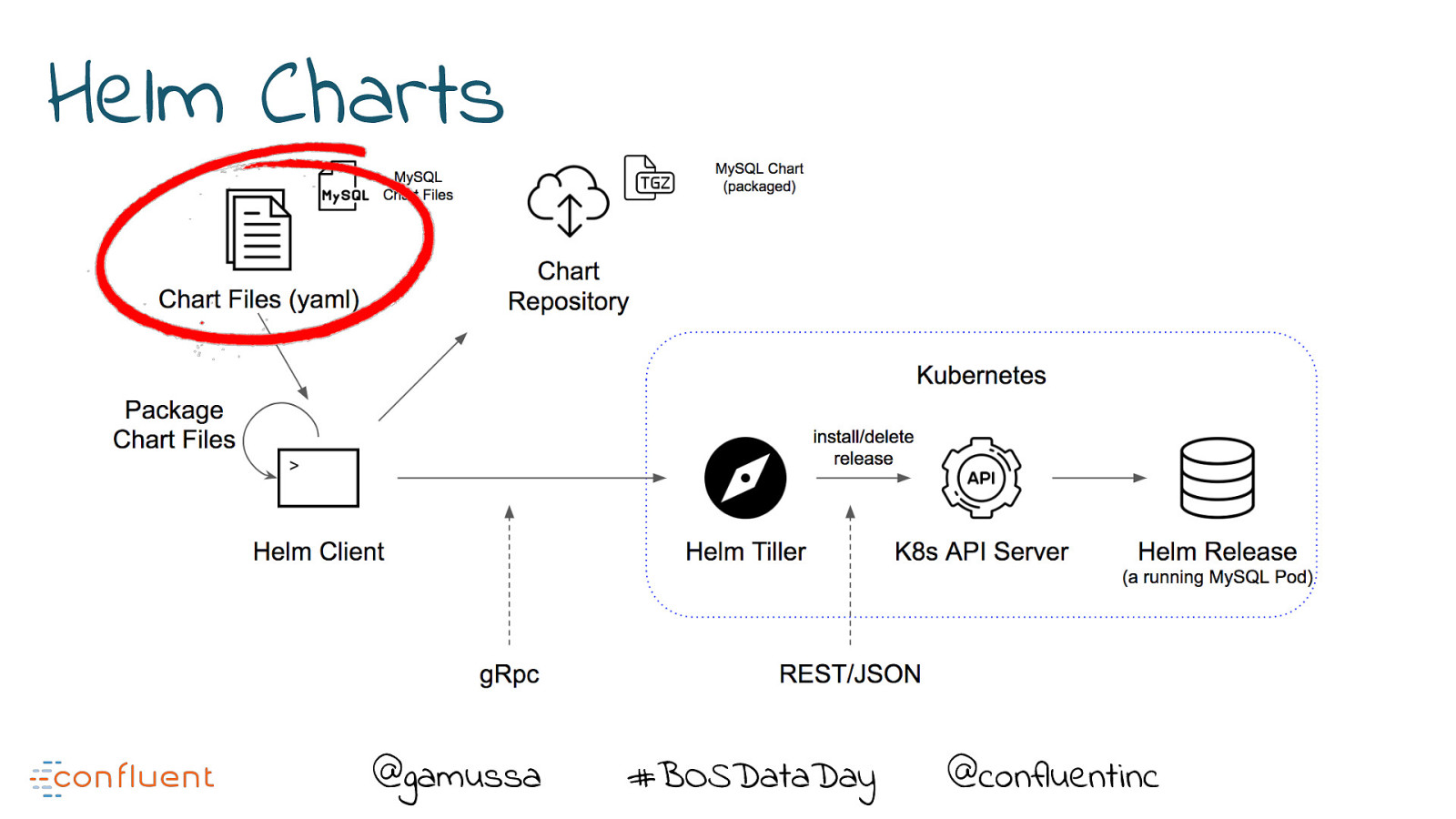
Helm Charts @gamussa #BOSDataDay @ @confluentinc
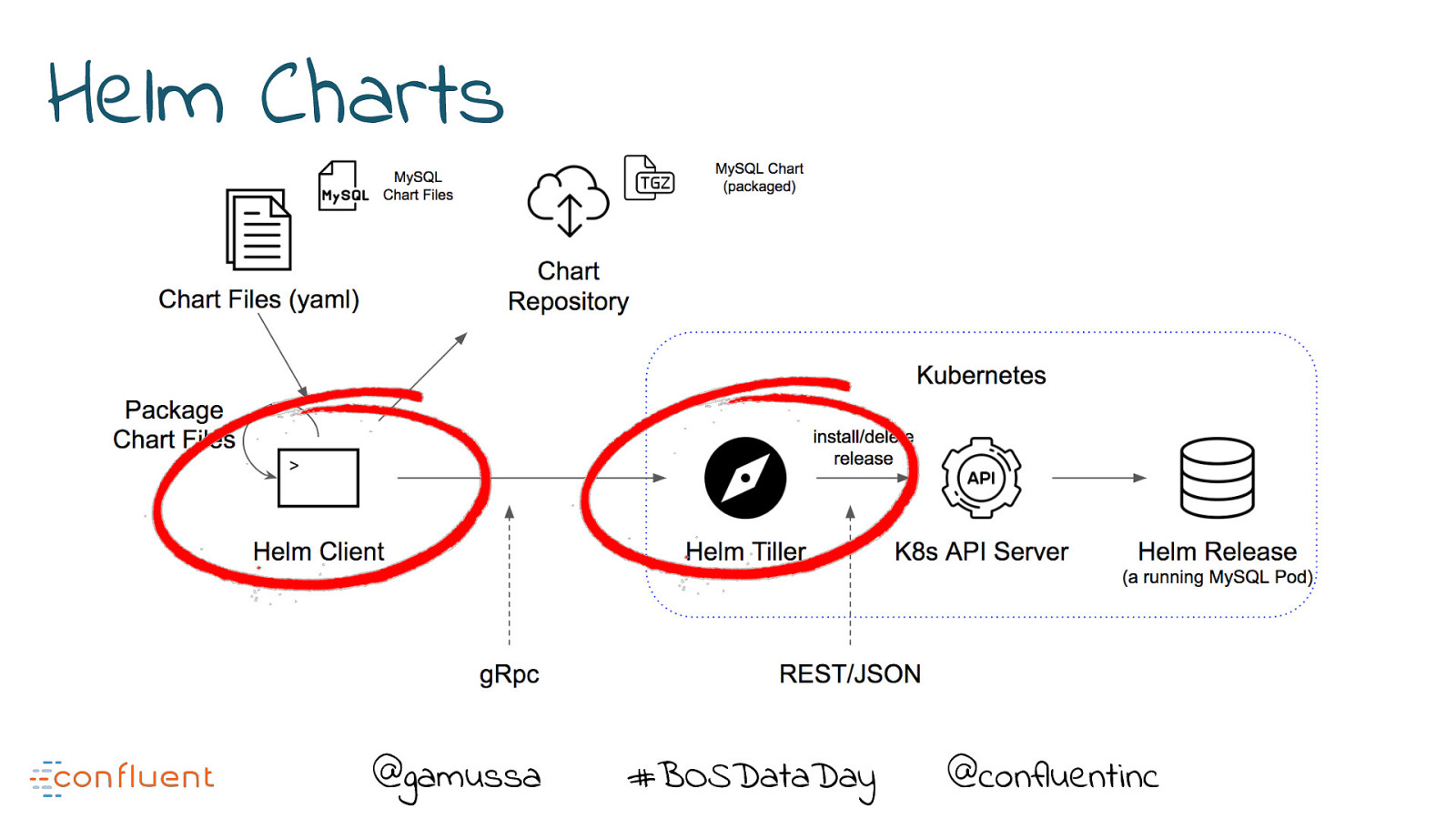
Helm Charts @gamussa #BOSDataDay @ @confluentinc
https://cnfl.io/helm_video @gamussa #BOSDataDay @confluentinc
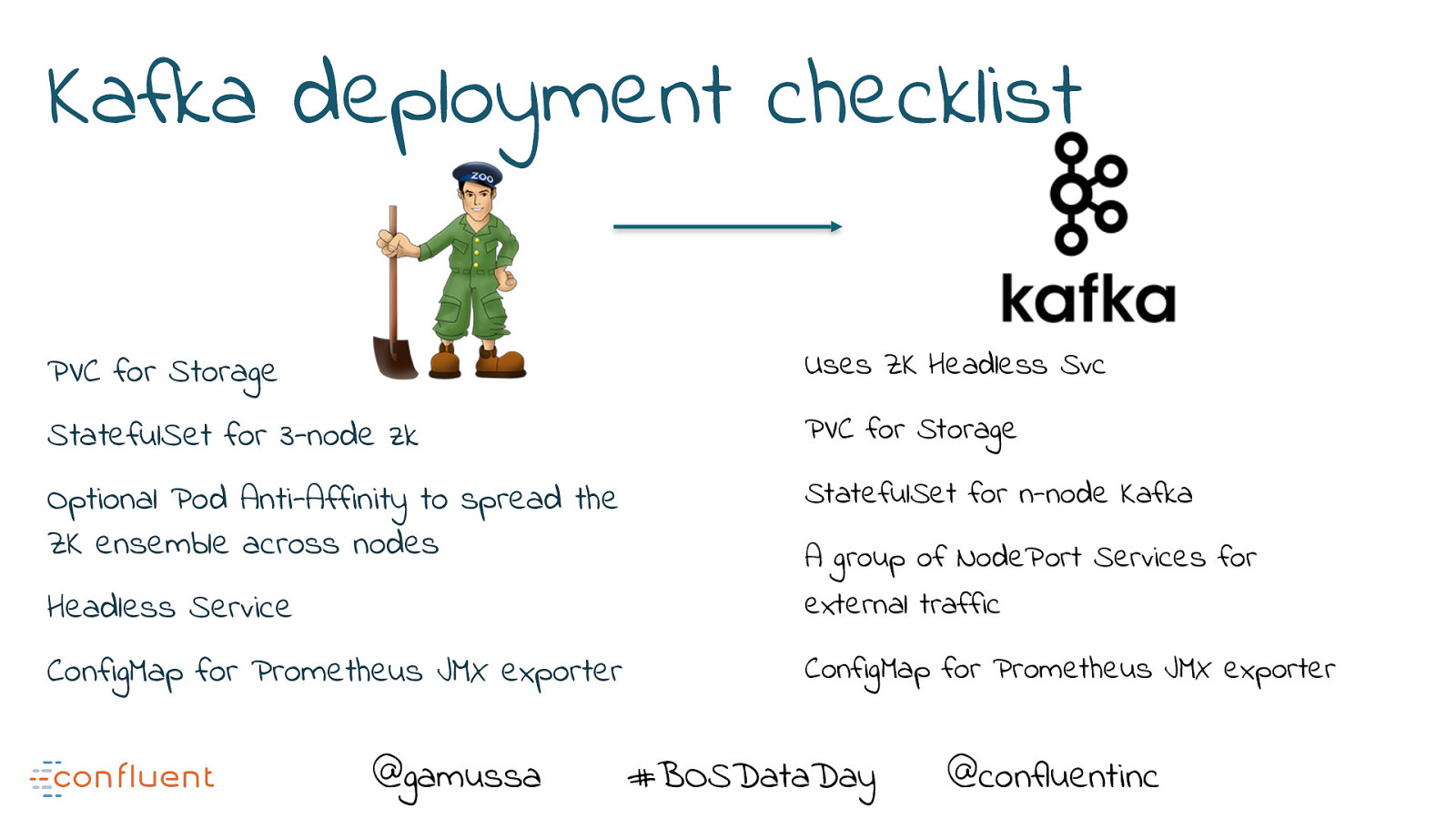
Kafka deployment checklist PVC for Storage Uses ZK Headless Svc StatefulSet for 3-node zk PVC for Storage Optional Pod Anti-Affinity to spread the ZK ensemble across nodes StatefulSet for n-node Kafka Headless Service A group of NodePort Services for external traffic ConfigMap for Prometheus JMX exporter ConfigMap for Prometheus JMX exporter @gamussa #BOSDataDay @ @confluentinc
Meet Kubernetes Operator @gamussa #BOSDataDay @ @confluentinc
Kubernetes Operator Embedded with operational knowledge of both data software and Kubernetes Backup/restore Scale up/down Rebalance data Regular health checks @gamussa #BOSDataDay @ @confluentinc
Controller Brain behind Kubernetes resources e.g. replication controller, namespace controller etc. @gamussa #BOSDataDay @ @confluentinc
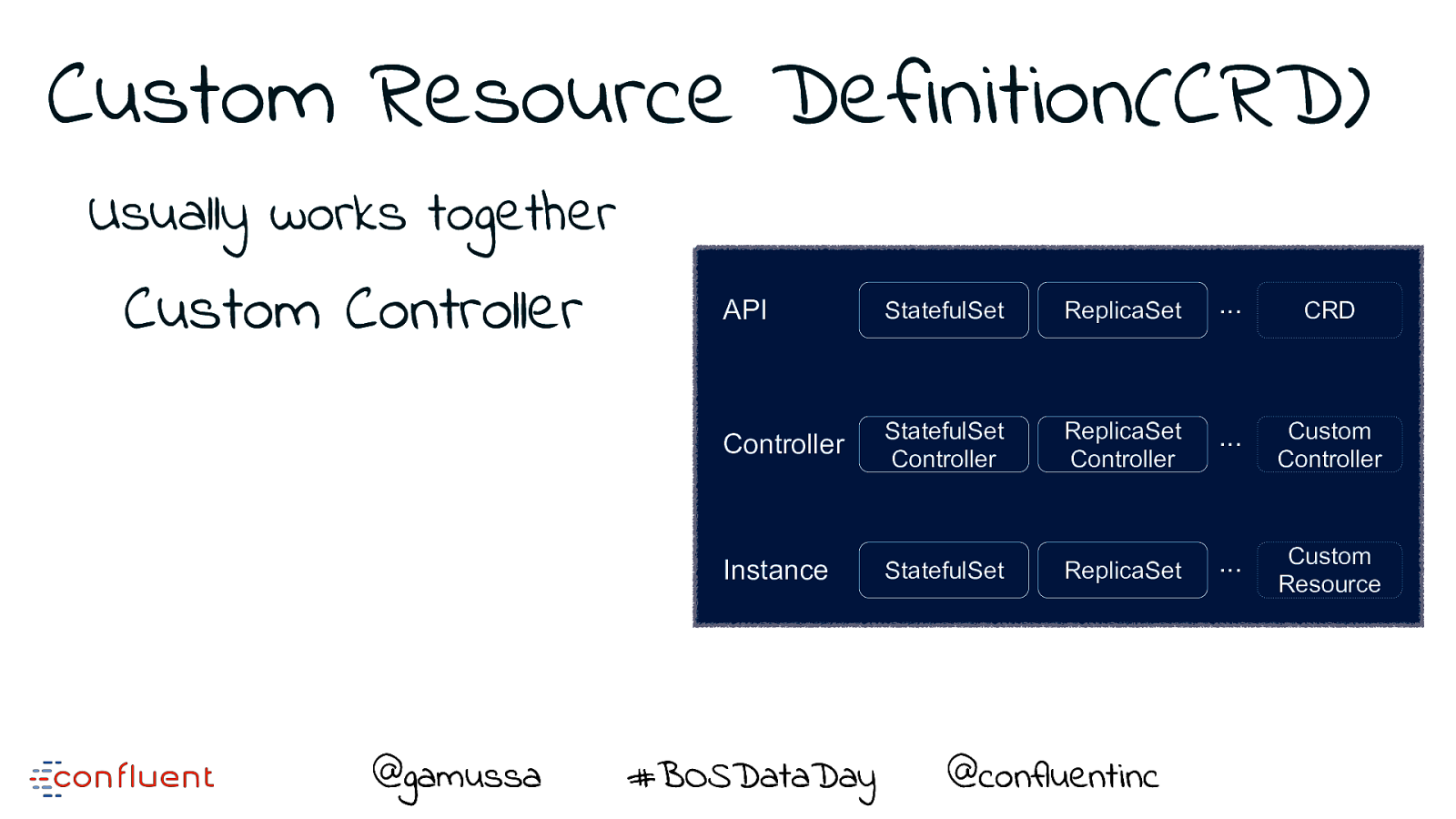
Custom Resource Definition(CRD) Extend existing Kubernetes API API StatefulSet ReplicaSet ... CRD Controller StatefulSet Controller ReplicaSet Controller ... Custom Controller ReplicaSet ... Custom Resource Instance @gamussa #BOSDataDay @ StatefulSet @confluentinc
Custom Resource Definition(CRD) Usually works together Custom Controller API StatefulSet ReplicaSet ... CRD Controller StatefulSet Controller ReplicaSet Controller ... Custom Controller ReplicaSet ... Custom Resource Instance @gamussa #BOSDataDay @ StatefulSet @confluentinc
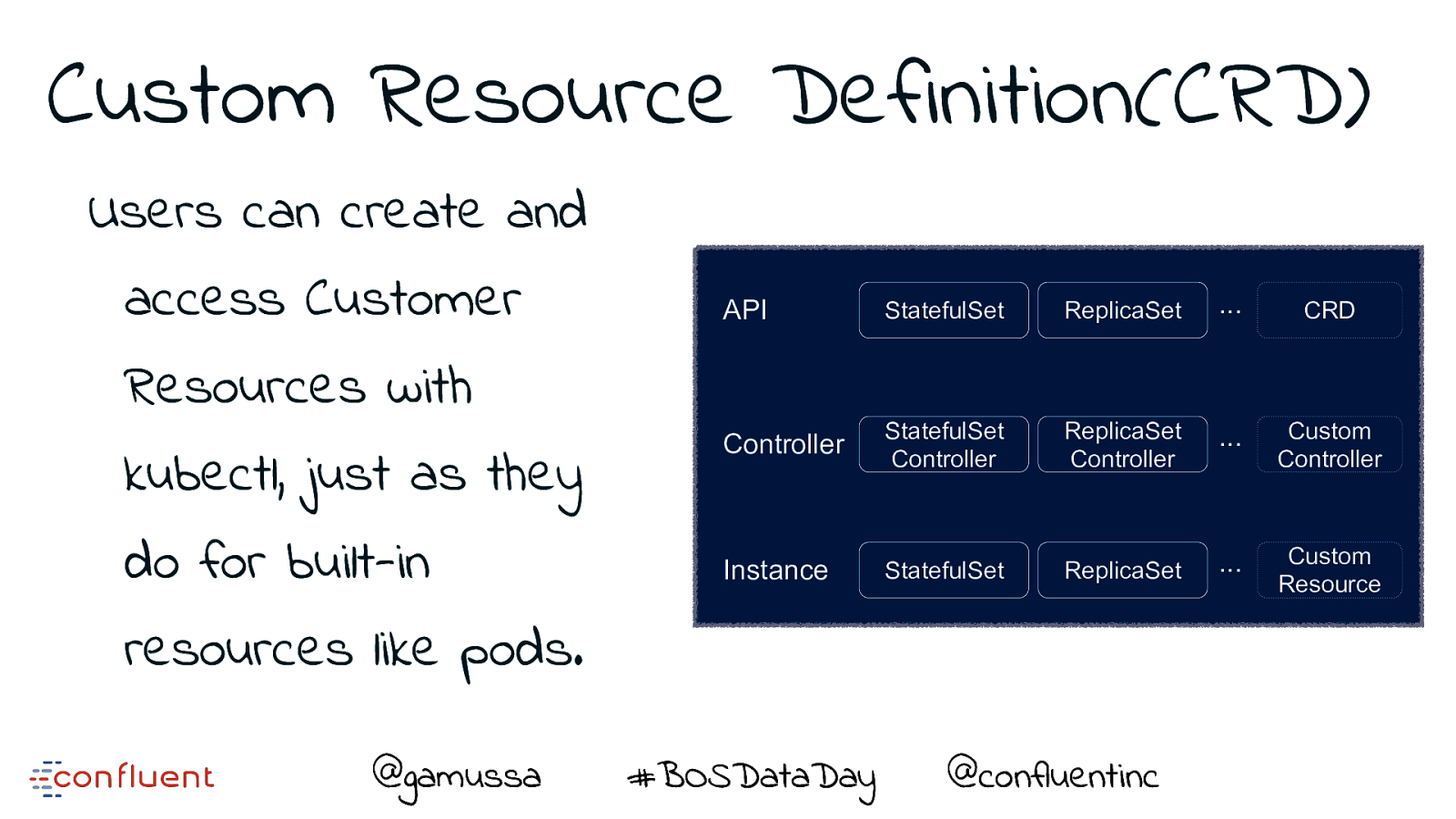
Custom Resource Definition(CRD) Users can create and access Customer Resources with kubectl, just as they do for built-in API StatefulSet ReplicaSet ... CRD Controller StatefulSet Controller ReplicaSet Controller ... Custom Controller ReplicaSet ... Custom Resource Instance StatefulSet resources like pods. @gamussa #BOSDataDay @ @confluentinc
Operator Deploy and Manage your production streaming platform with Confluent Operator. Automated Provisioning Platform Operations Resiliency Monitoring @gamussa #BOSDataDay @ @confluentinc
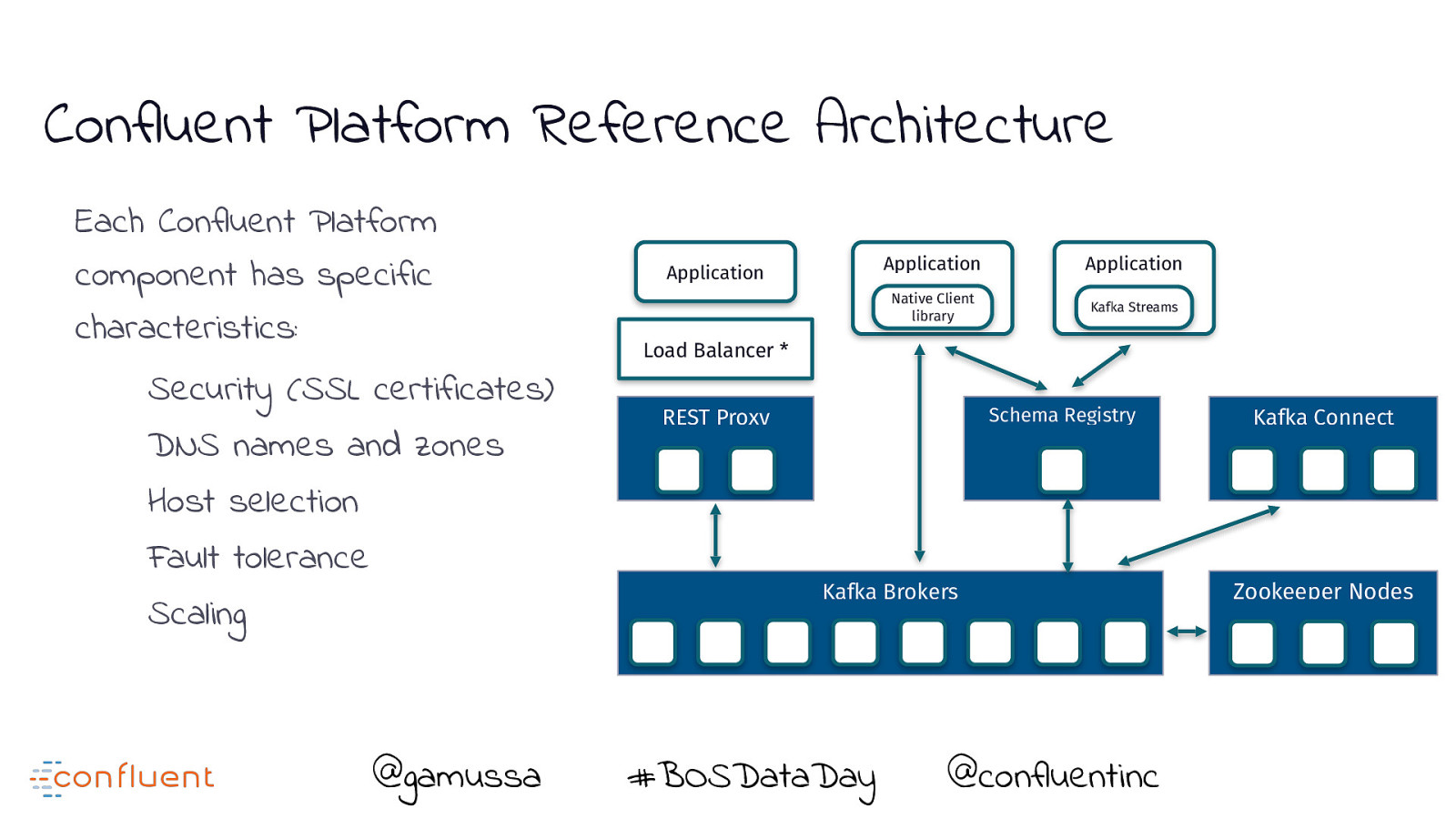
Confluent Platform Reference Architecture Each Confluent Platform component has specific characteristics: Security (SSL certificates) DNS names and zones Application Application Application Native Client library Kafka Streams Load Balancer * Schema Registry REST Proxy Kafka Connect Host selection Fault tolerance Kafka Brokers Scaling @gamussa #BOSDataDay @ @confluentinc Zookeeper Nodes
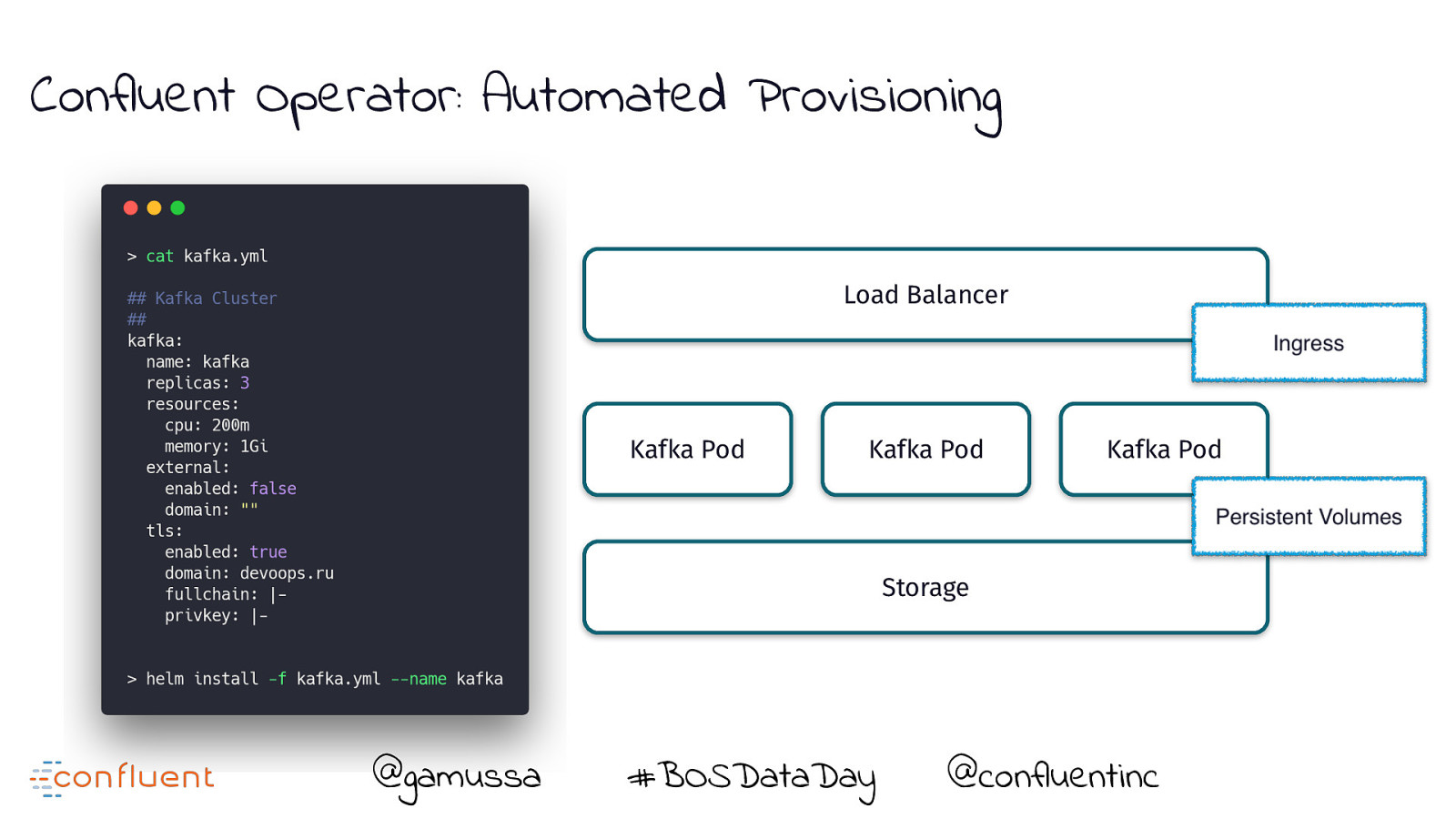
Confluent Operator: Automated Provisioning Load Balancer Kafka Pod Kafka Pod Kafka Pod Storage @gamussa #BOSDataDay @ @confluentinc
Confluent Operator: Scale Horizontally Automate scaling: Spin up new broker pod(s) Distribute partitions to the new broker(s) Determine balancing plan Execute balancing plan Monitor resources @gamussa #BOSDataDay @ @confluentinc
Confluent Operator: Rolling Upgrade Automated rolling upgrade with no downtime for Kafka. Stop broker Wait for leader election to complete Start broker with new version Wait for zero under-replicatedpartitions Repeat @gamussa #BOSDataDay @ @confluentinc
Will it fly? Let’s see @gamussa #BOSDataDay @confluentinc
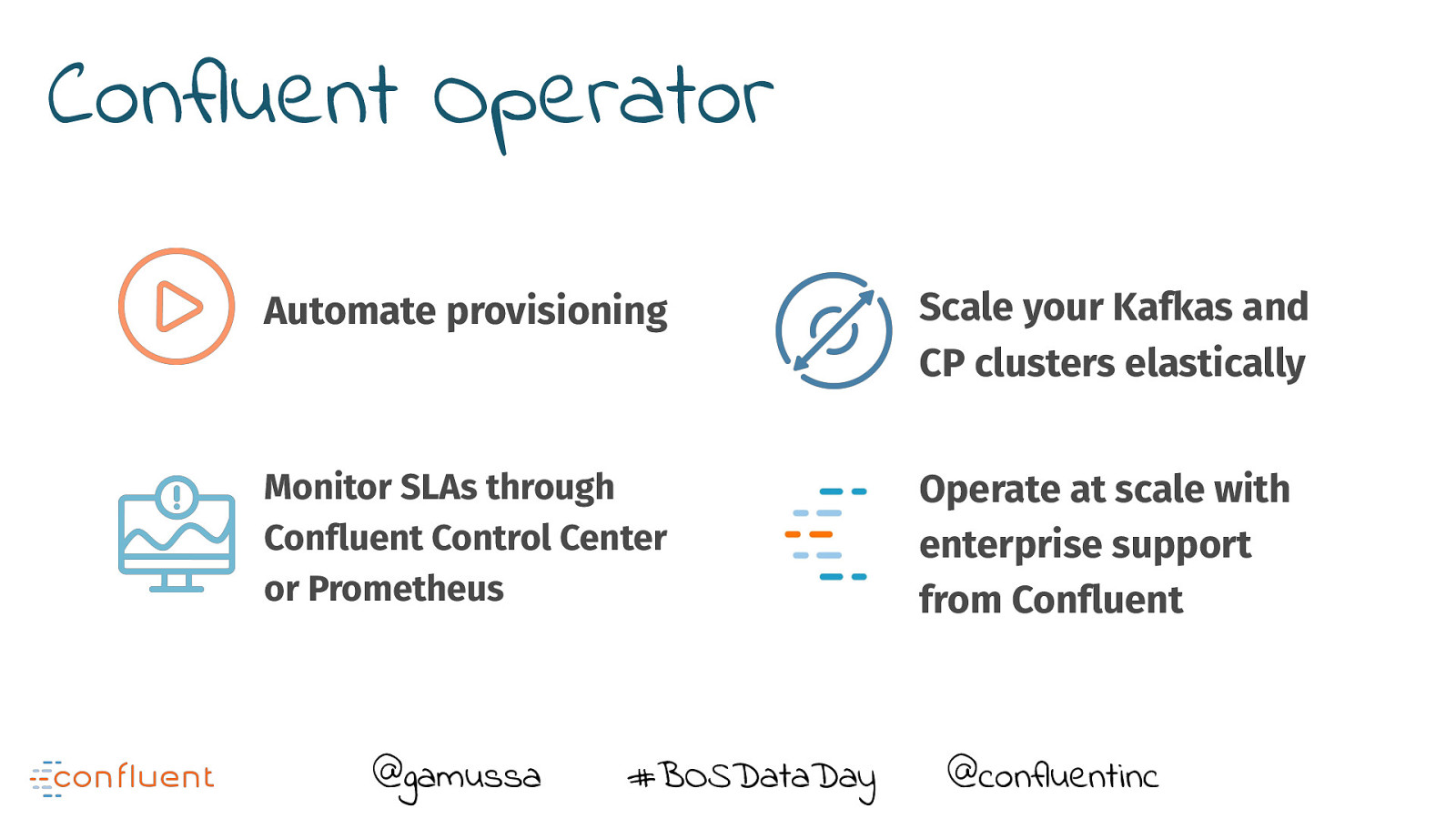
Confluent Operator Automate provisioning Scale your Kafkas and CP clusters elastically Monitor SLAs through Confluent Control Center or Prometheus Operate at scale with enterprise support from Confluent @gamussa #BOSDataDay @ @confluentinc
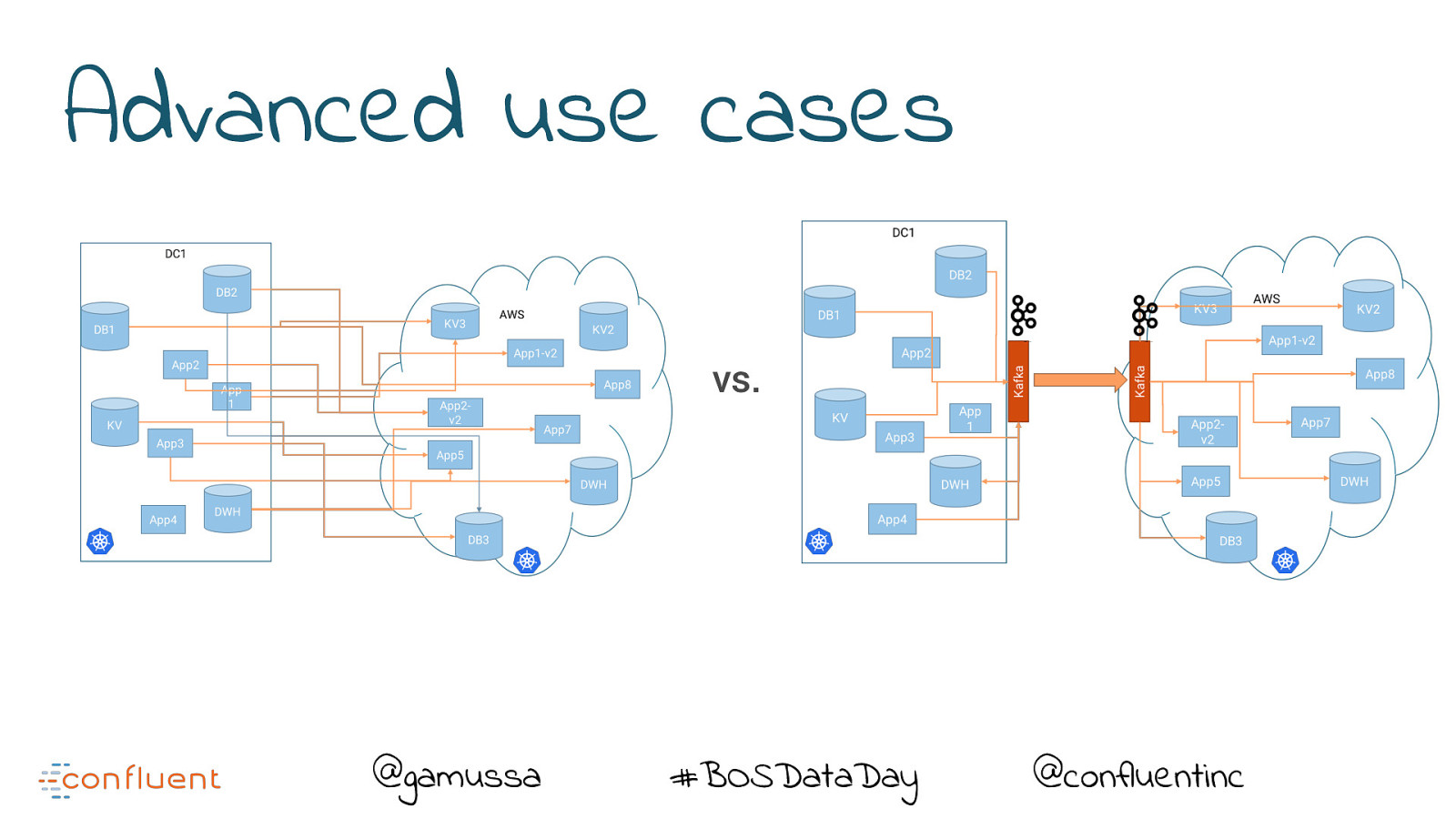
Advanced use cases vs. @gamussa #BOSDataDay @confluentinc
Don’t despair! @gamussa #BOSDataDay @ @confluentinc
Resources and Next Steps https://cnfl.io/helm_video https://cnfl.io/cp-helm https://cnfl.io/k8s https://slackpass.io/confluentcommunity #kubernetes @gamussa #BOSDataDay @confluentinc
Thanks! @gamussa viktor@confluent.io @gamussa #BOSDataDay @ @confluentinc

When the time comes to choose a distributed streaming platform for real-time data pipelines, everyone knows the answer: Apache Kafka. And when it comes to deploying real-time stream processing applications at scale without having to integrate some different pieces of infrastructure yourself? The answer is Kubernetes. This session discusses best practices for running Apache Kafka and other components of a streaming platform such as Kafka Connect and Schema Registry as well as stream processing apps on Kubernetes. It covers the challenges and lessons learned from developing the Confluent Operator for Kubernetes as well as different custom deployments on various Kubernetes installations.
Here’s what was said about this presentation on social media.