
A presentation at ACM SIGMOD Int’l Conf on Mgmt of Data in in Dallas, TX, USA by erik riedel

Erik Riedel Hewlett-Packard Labs Greg Ganger, Christos Faloutsos, Dave Nagle Carnegie Mellon University Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Outline Motivation Freeblock Scheduling Scheduling Trade-Offs Performance Details Applications Related Work Conclusion & Future Work Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Disk Trends 1980 Model IBM 3330 Average Seek 38.6 ms Rotational Speed 3,600 rpm Capacity 0.09 GB Bandwidth 0.74 MB/s 8 KB Transfer 65.2 ms 1 MB Transfer 1,382 ms 1987 1990 1994 1999 Fujitsu Seagate Seagate Quantum M2361A ST-41600n ST-15150n Atlas 10k 16.7 ms 11.5 ms 8.0 ms 5.0 ms 3,600 rpm 5,400 rpm 7,200 rpm 10,000 rpm 0.6 GB 1.37 GB 4.29 GB 18.2 GB 2.5 MB/s 3-4.4 MB/s 6-9 MB/s 18-22 MB/s 28.3 ms 18.9 ms 13.1 ms 9.6 ms 425 ms 244 ms 123 ms 62 ms 80-99 Annual Improvement 11% / year 6% / year 32% / year 20% / year 11% / year 18% / year Trends in single drive performance • huge capacity increases • bandwidth doesn’t keep pace • seek/rotation lagging far behind Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Outline Motivation Freeblock Scheduling Scheduling Trade-Offs Performance Details Applications Related Work Conclusion & Future Work Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
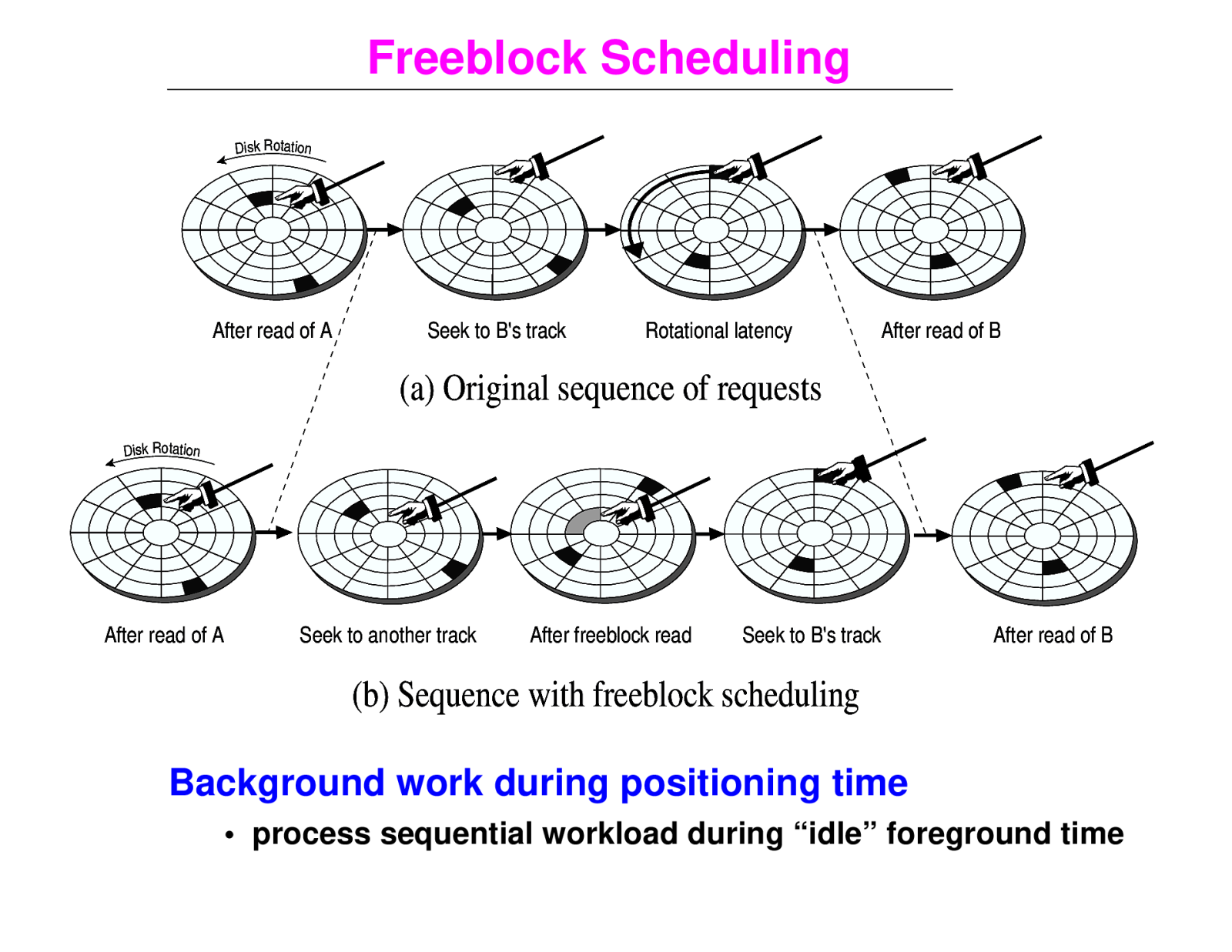
Freeblock Scheduling Disk Rotation After read of A Seek to B’s track Rotational latency After read of B (a) Original sequence of requests Disk Rotation After read of A Seek to another track After freeblock read Seek to B’s track After read of B (b) Sequence with freeblock scheduling Background work during positioning time • process sequential workload during “idle” foreground time
Freeblock Opportunities ordering of processing blocks does not affect the result foreach block(B) in relation(X) { process(B) -> B’ } combine(B’) -> result(R) Freeblock choices Most effective background workloads • scan across a large number of blocks • order of processing blocks doesn’t matter • “opportunistic” performance acceptable Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Outline Motivation Freeblock Scheduling Scheduling Trade-Offs Performance Details Applications Related Work Conclusion & Future Work Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
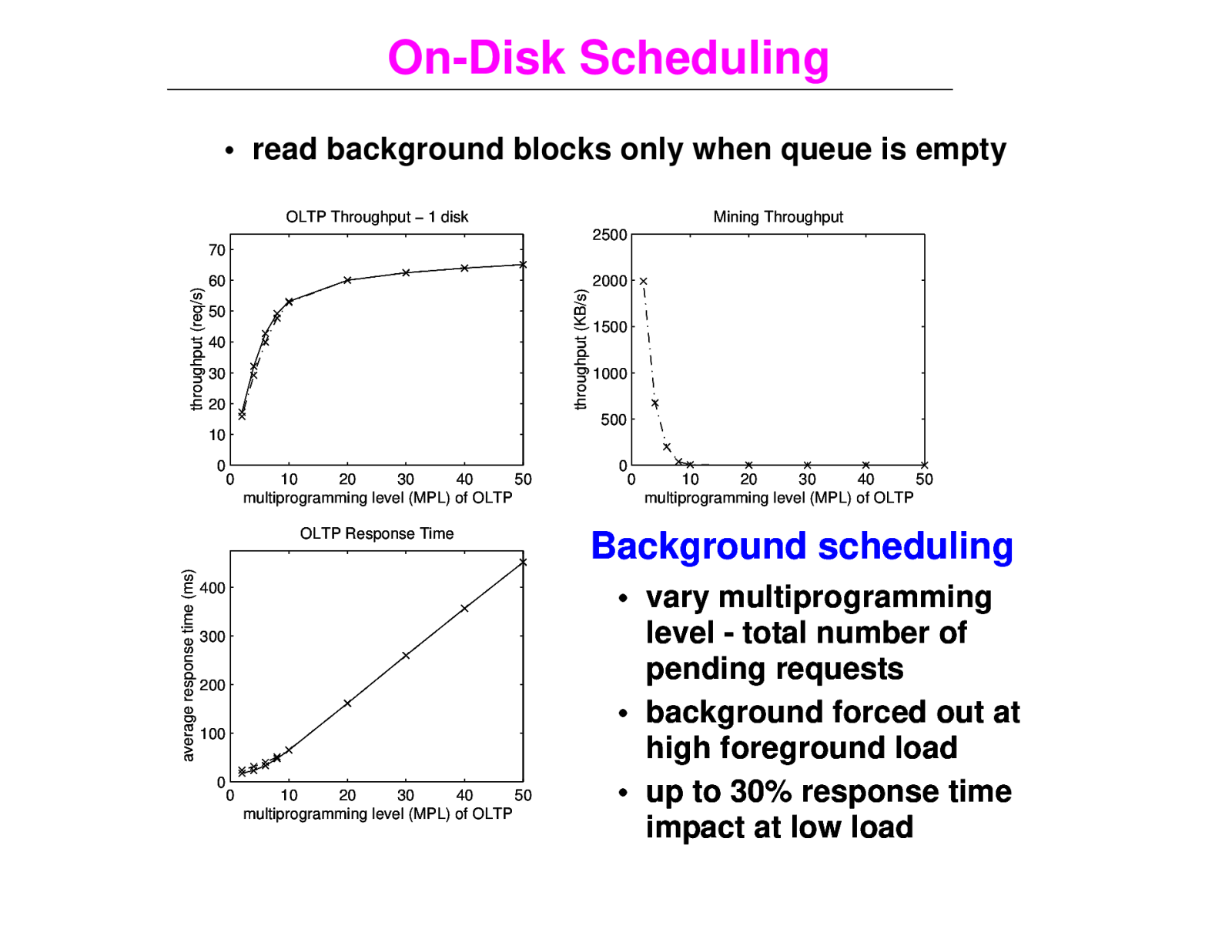
On-Disk Scheduling • read background blocks only when queue is empty OLTP Throughput − 1 disk Mining Throughput 2500 60 throughput (KB/s) throughput (req/s) 70 50 40 30 20 2000 1500 1000 500 10 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP average response time (ms) OLTP Response Time 400 300 200 100 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP Background scheduling • vary multiprogramming level - total number of pending requests • background forced out at high foreground load • up to 30% response time impact at low load
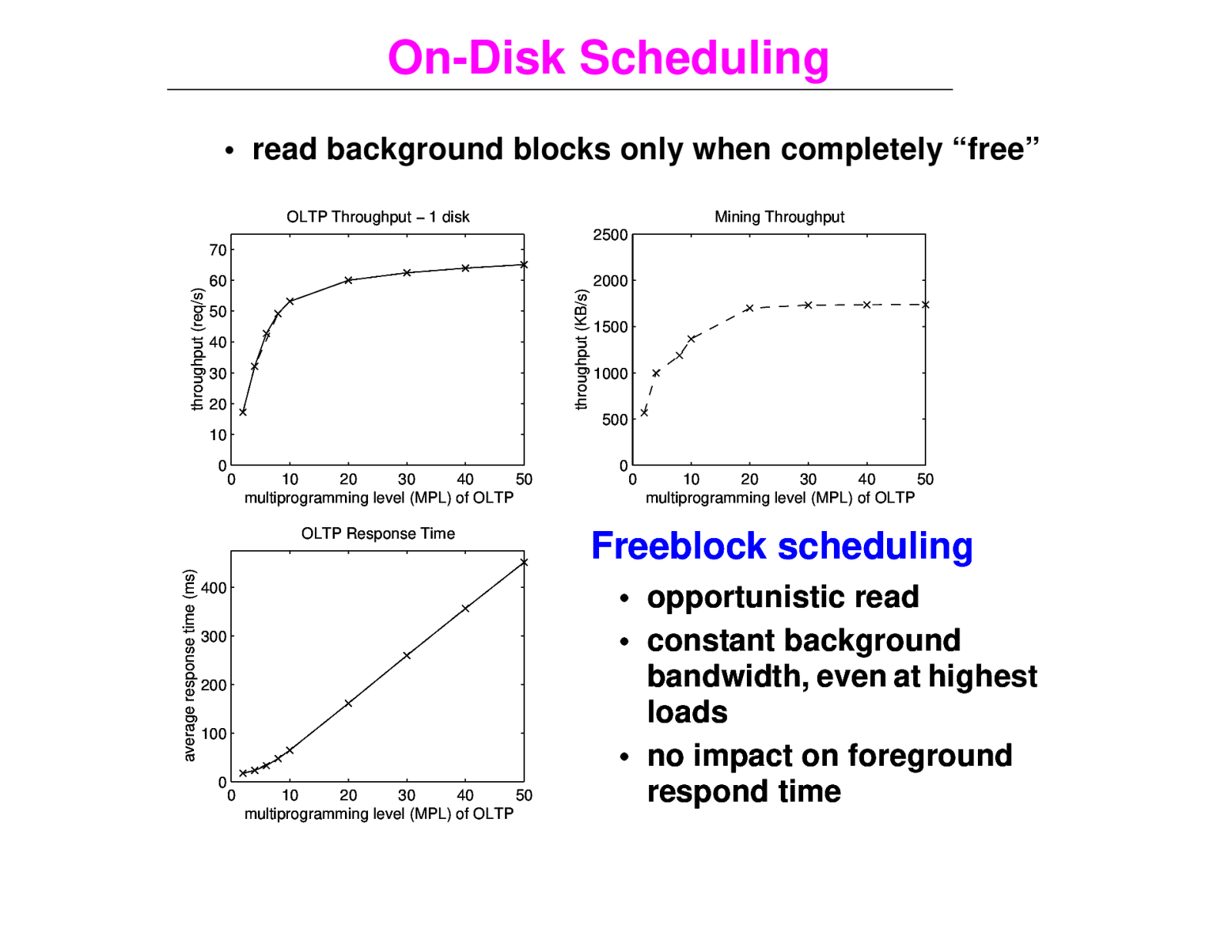
On-Disk Scheduling • read background blocks only when completely “free” OLTP Throughput − 1 disk Mining Throughput 2500 60 throughput (KB/s) throughput (req/s) 70 50 40 30 20 2000 1500 1000 500 10 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP average response time (ms) OLTP Response Time 400 300 200 100 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP Freeblock scheduling • opportunistic read • constant background bandwidth, even at highest loads • no impact on foreground respond time
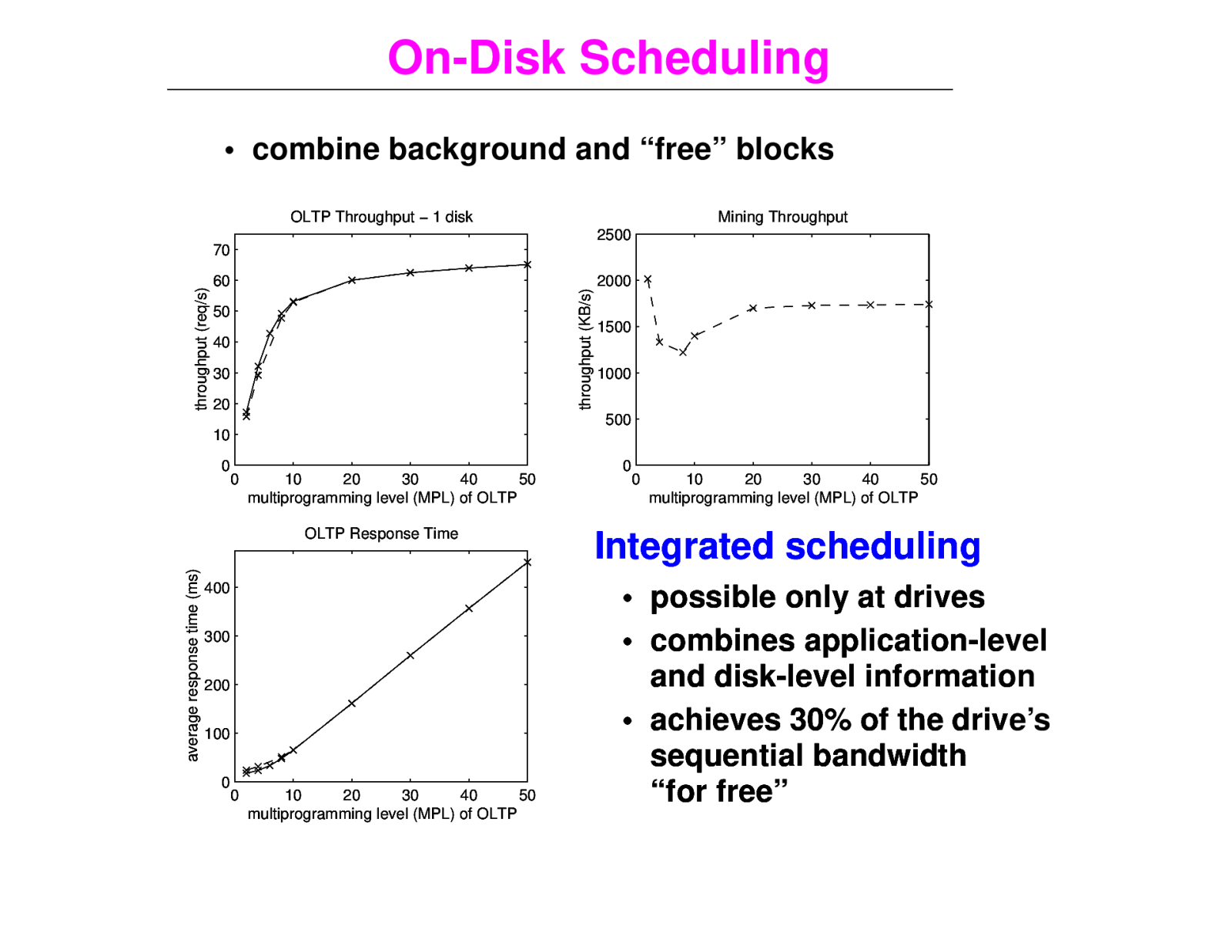
On-Disk Scheduling • combine background and “free” blocks OLTP Throughput − 1 disk Mining Throughput 2500 60 throughput (KB/s) throughput (req/s) 70 50 40 30 20 2000 1500 1000 500 10 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP average response time (ms) OLTP Response Time 400 300 200 100 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP Integrated scheduling • possible only at drives • combines application-level and disk-level information • achieves 30% of the drive’s sequential bandwidth “for free”
Outline Motivation Freeblock Scheduling Scheduling Trade-Offs Performance Details Applications Related Work Conclusion & Future Work Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
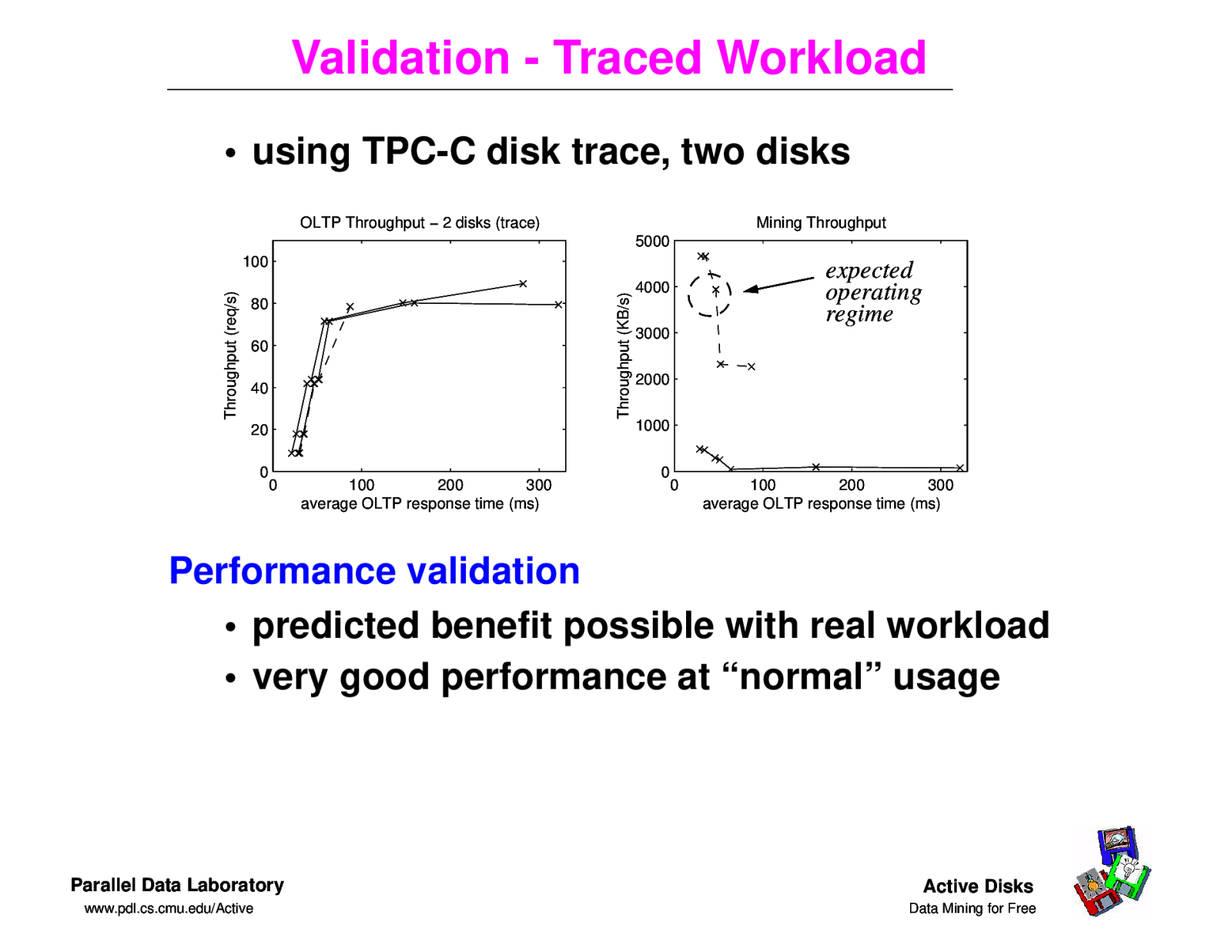
Validation - Traced Workload • using TPC-C disk trace, two disks OLTP Throughput − 2 disks (trace) Mining Throughput 5000 Throughput (KB/s) Throughput (req/s) 100 80 60 40 3000 2000 1000 20 0 expected operating regime 4000 0 100 200 300 average OLTP response time (ms) 0 0 100 200 300 average OLTP response time (ms) Performance validation • predicted benefit possible with real workload • very good performance at “normal” usage Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
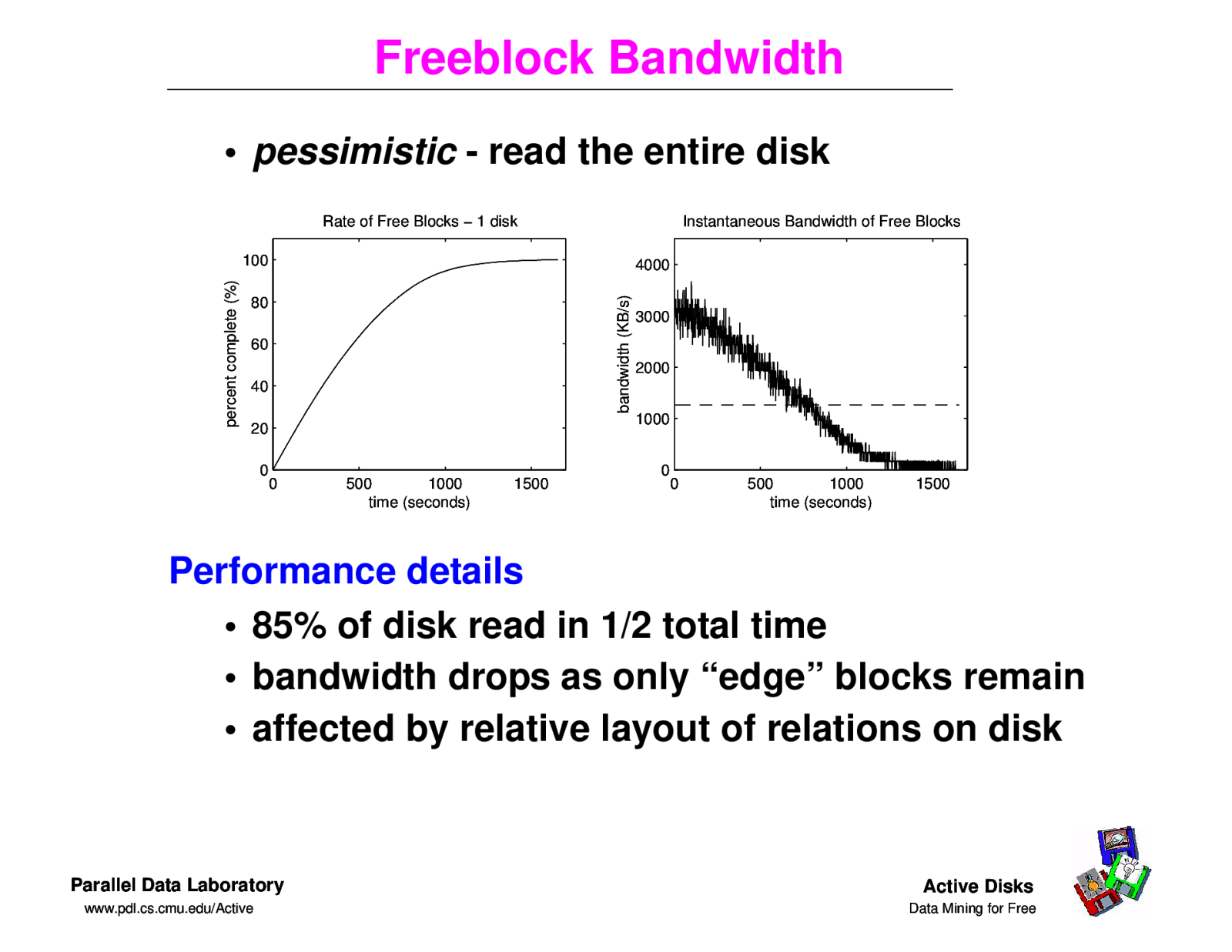
Freeblock Bandwidth • pessimistic - read the entire disk Rate of Free Blocks − 1 disk Instantaneous Bandwidth of Free Blocks 4000 bandwidth (KB/s) percent complete (%) 100 80 60 40 20 0 0 500 1000 time (seconds) 1500 3000 2000 1000 0 0 500 1000 time (seconds) 1500 Performance details • 85% of disk read in 1/2 total time • bandwidth drops as only “edge” blocks remain • affected by relative layout of relations on disk Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
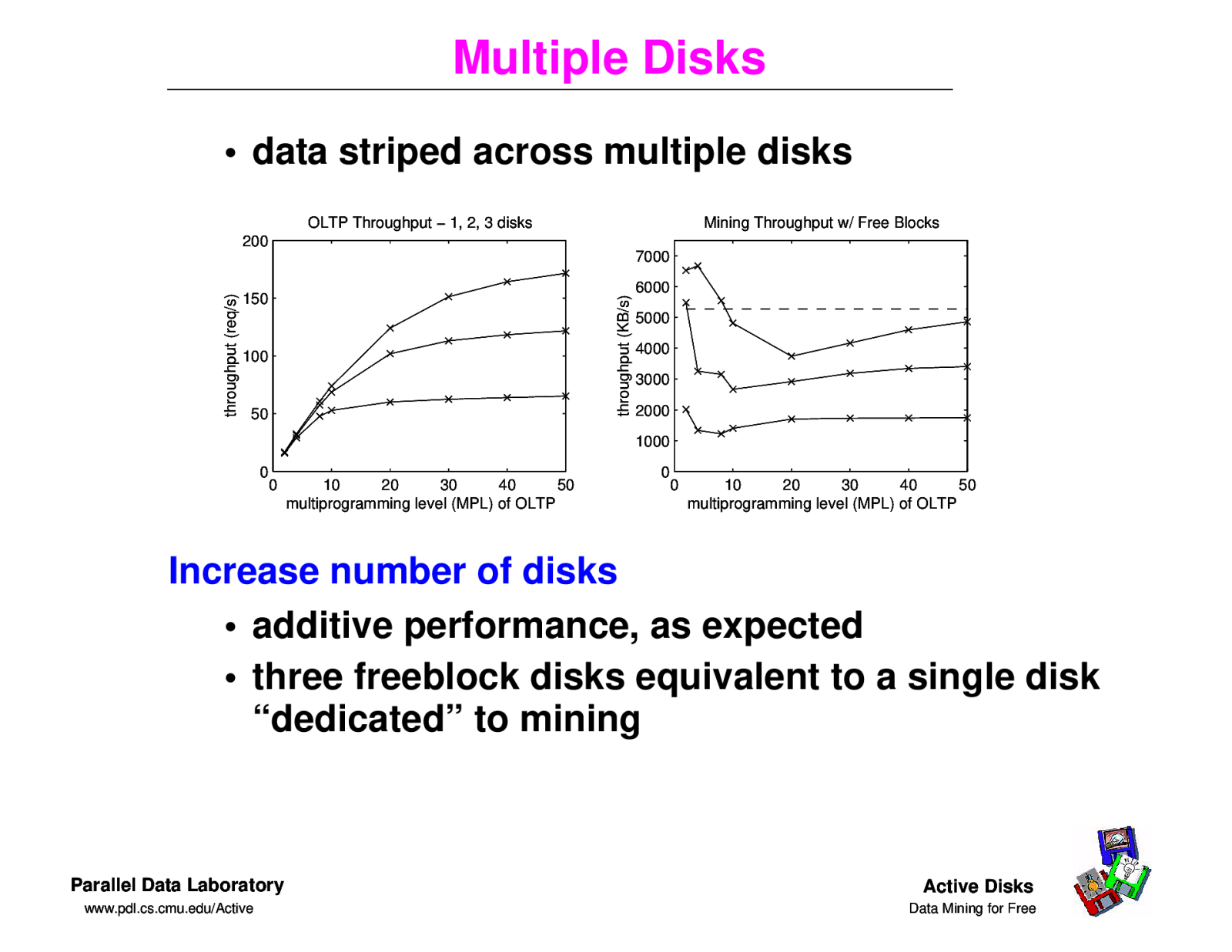
Multiple Disks • data striped across multiple disks OLTP Throughput − 1, 2, 3 disks Mining Throughput w/ Free Blocks 200 150 throughput (KB/s) throughput (req/s) 7000 100 50 6000 5000 4000 3000 2000 1000 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP 0 0 10 20 30 40 50 multiprogramming level (MPL) of OLTP Increase number of disks • additive performance, as expected • three freeblock disks equivalent to a single disk “dedicated” to mining Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Outline Motivation Freeblock Scheduling Scheduling Trade-Offs Performance Details Applications Related Work Conclusion & Future Work Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Applications for Freeblocks Data Mining for Free • scans • parallel table scans • search, association rules, ratio rules & SVD, clustering • sampling • statistical mining, histogram maintenance • assuming a slightly modified “random” is acceptable • assuming that CPU and memory resources are available Background Utilities • • • • layout optimization incremental backup virus scan, fast find assures “some” progress, even on busy disks Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Synergy with Active Disks Traditional System Active Disk System selective processing reduces network bandwidth required upstream on-disk processing offloads server CPU disk bandwidth becomes the critical resource resources required: cpu, memory, network, disk Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Outline Motivation Freeblock Scheduling Scheduling Trade-Offs Performance Details Applications Related Work Conclusion & Future Work Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
On-drive Optimization Request Scheduling • fcfs, scan, look, elevator, sptf • limited by short queues Interface Advances • MFM - direct control • SCSI - abstracted interface, fixed size blocks, linear addresses • cylinder groups, block remapping, … • current debates - which higher-level interface? • Network-Attached Storage (NAS) • Object-Based Disks (OBD) How to Get More Information from Applications • operating system interfaces limited • “hints” - informed prefetching and caching • Active Disks - push application knowledge to disks Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Related Work Disk Scheduling • studied for many years [Denning67, …, Worthington94] Combined OLTP and Mining • memory in mixed workload [Brown92, Brown93] • multiple workload classes, boundary shifts • OLTP and DSS on same system [Paulin97] • 35% - 100% impact • disk is critical resource • Sun/IBM benchmark system [TPC97] • separate CPUs, separate memory • (mostly) separate disks On-disk Optimization • zero-latency reads for prefetch • fast writes [Wang99] Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Conclusion & Further Work Exploit technology trends • disk bandwidth and positioning time not keeping pace • use scheduling knowledge at the disks Novel functionality • data mining for free - close to 30% bandwidth “for free” • even at high foreground loads Interface design • how to get more information into the disk • where is the best to place processing resources Further Work • details of interface, what file system extensions? • explore interaction/synergy with data layout • quantify costs/benefits in a running system Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Future Work Evaluation of All Database Operations • optimization for index-based scans • update performance, combine with fast writes Programming Model - Application Layers • get information through the file system interface • storage layout • access patterns Implementation Details • drive resource requirements • memory - low • cpu - medium • demonstrate a “real” background workload • implement combined OLTP/mining • or a utility operation Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Excess Device Cycles Are Here Higher and higher levels of integration in electronics • specialized drive chips combined into single ASIC • technology trends push toward integrated control processor • Siemens TriCore - 100 MHz, 32-bit superscalar today • to 500 MIPS within 2 years, up to 2 MB on-chip memory • Cirrus Logic 3CI - ARM7 core today • to ARM9 core at 200 MIPS in next generation High volume, commodity product • 145 million disk drives sold in 1998 • about 725 petabytes of total storage • manufacturers looking for value-added functionality Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Evolution of Disk Drive Electronics Integration • • • • reduces chip count improves reliability reduces cost future integration to processor on-chip • but there must be at least one chip
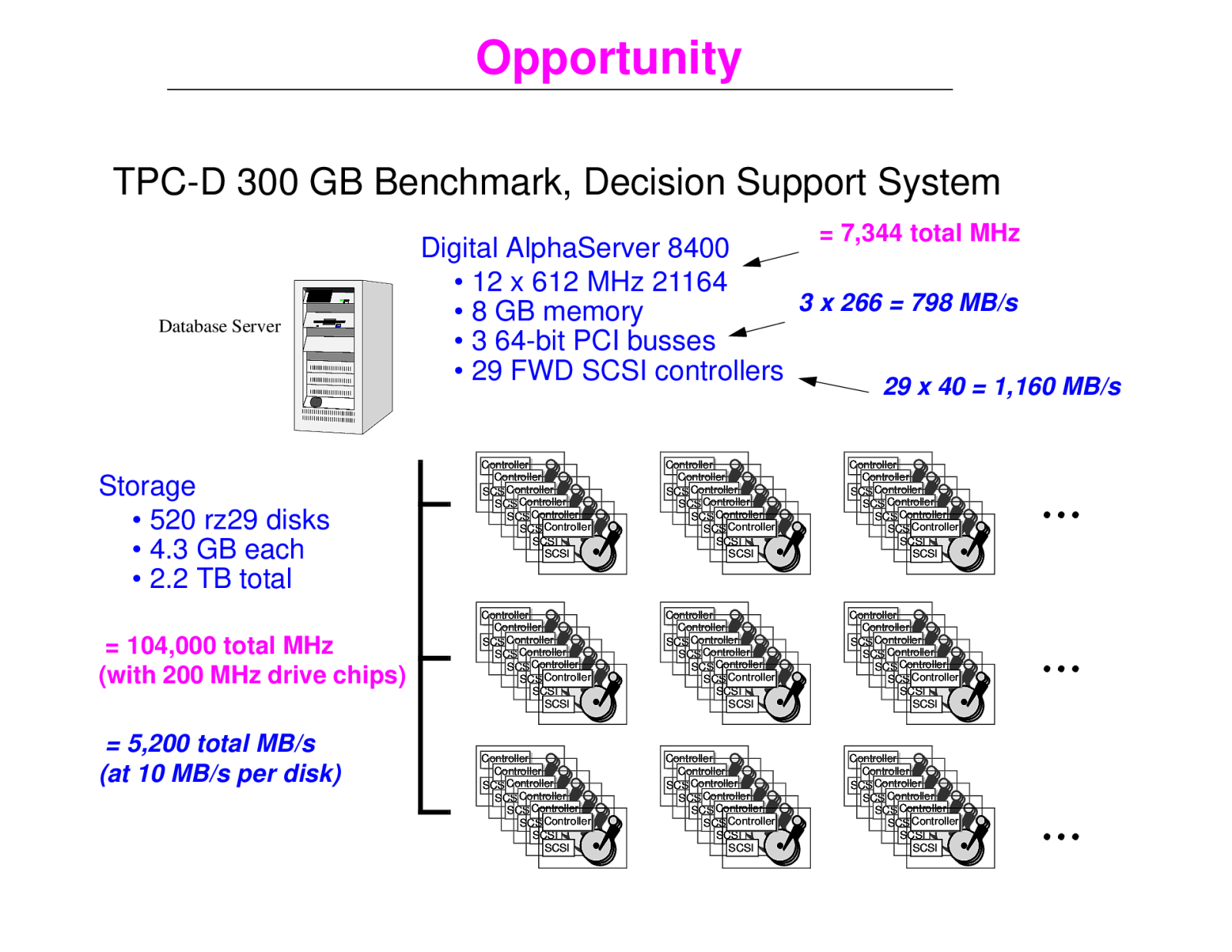
Opportunity TPC-D 300 GB Benchmark, Decision Support System = 7,344 total MHz Database Server Digital AlphaServer 8400 • 12 x 612 MHz 21164 3 x 266 = 798 MB/s • 8 GB memory • 3 64-bit PCI busses • 29 FWD SCSI controllers 29 x 40 = 1,160 MB/s Storage • 520 rz29 disks • 4.3 GB each • 2.2 TB total = 104,000 total MHz (with 200 MHz drive chips) = 5,200 total MB/s (at 10 MB/s per disk) Controller Controller SCSIController SCSIController SCSIController SCSIController SCSI SCSI Controller Controller SCSIController SCSIController SCSIController SCSIController SCSI SCSI Controller Controller SCSIController SCSIController SCSIController SCSIController SCSI SCSI Controller Controller SCSIController SCSIController SCSIController SCSIController SCSI SCSI Controller Controller SCSIController SCSIController SCSIController SCSIController SCSI SCSI Controller Controller SCSIController SCSIController SCSIController SCSIController SCSI SCSI Controller Controller SCSIController SCSIController SCSIController SCSIController SCSI SCSI Controller Controller SCSIController SCSIController SCSIController SCSIController SCSI SCSI Controller Controller SCSIController SCSIController SCSIController SCSIController SCSI SCSI
Advantage - Active Disks Active Disks execute application-level code on drives Basic advantages of an Active Disk system • parallel processing - lots of disks • bandwidth reduction - filtering operations are common • scheduling - little bit of “strategy” can go a long way Characteristics of appropriate applications • • • • execution time dominated by data-intensive “core” allows parallel implementation of “core” cycles per byte of data processed - computation data reduction of processing - selectivity Parallel Data Laboratory www.pdl.cs.cmu.edu/Active Active Disks Data Mining for Free
Network “Appliances” Can Win Today Dell PowerEdge & PowerVault System Dell PowerVault 650F $46,549 x 12 =558,588 512 MB cache, dual link controllers, additional 630F cabinet, 20 x 9 GB FC disks, software support, installation Dell PowerEdge 6350 $9,210 x 12 = 110,520 500 MHz PIII, 512 MB RAM, 27 GB disk 3Com SuperStack II 3800 Switch 6,679 10/100 Ethernet, Layer 3, 24-port Rack Space for all that NASRaQ System Cobalt NASRaQ 20,710 Comparison $1,617 x 240 =388,080 250 MHz RISC, 32 MB RAM, 2 x 10 GB disks Extra Memory (to 128 MB each) $174 x 240= 3Com SuperStack II 3800 Switch $6,679 x 11= 41,760 76,736 240/24 = 10 + 1 to connect those 10 Dell PowerEdge 6350 Front-End Rack Space (estimate 4x as much as the Dells) Installation & Misc 9,210 82,840 50,000 Storage Spindles Compute Memory Power Cost Dell 2.1 TB 240 6 GHz 12.0 GB 23,122 W $696,794 Cobalt 4.7 TB 480 60 GHz 30.5 GB 12,098 W $648,626

This paper proposes a scheme for scheduling disk requests that takes advantage of the ability of high-level functions to operate directly at individual disk drives. We show that such a scheme makes it possible to support a Data Mining workload on an OLTP system almost for free: there is only a small impact on the throughput and response time of the existing workload. Specifically, we show that an OLTP system has the disk resources to consistently provide one third of its sequential bandwidth to a background Data Mining task with close to zero impact on OLTP throughput and response time at high transaction loads. At low transaction loads, we show much lower impact than observed in previous work. This means that a production OLTP system can be used for Data Mining tasks without the expense of a second dedicated system. Our scheme takes advantage of close interaction with the on-disk scheduler by reading blocks for the Data Mining workload as the disk head “passes over” them while satisfying demand blocks from the OLTP request stream. We show that this scheme provides a consistent level of throughput for the background workload even at very high foreground loads. Such a scheme is of most benefit in combination with an Active Disk environment that allows the background Data Mining application to also take advantage of the processing power and memory available directly on the disk drives.

















 for free. You
can too.
for free. You
can too.