
A presentation at VoxxedDays Ticino 2019 in in Lugano, Switzerland by Hans-Peter Grahsl

Streaming ETL on the Shoulders of G I A N T S
Hans-Peter Grahsl ” • working & living in Graz • technical trainer at • independent consultant & engineer • associate lecturer • @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland occasional conference speaker 2
Speed & Agility @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 3
For businesses to stay relevant they must deliver value at a breakneck pace and be constantly seeking new sources of value … @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 4
@hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 5
@hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 6
@hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 7
@hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 8
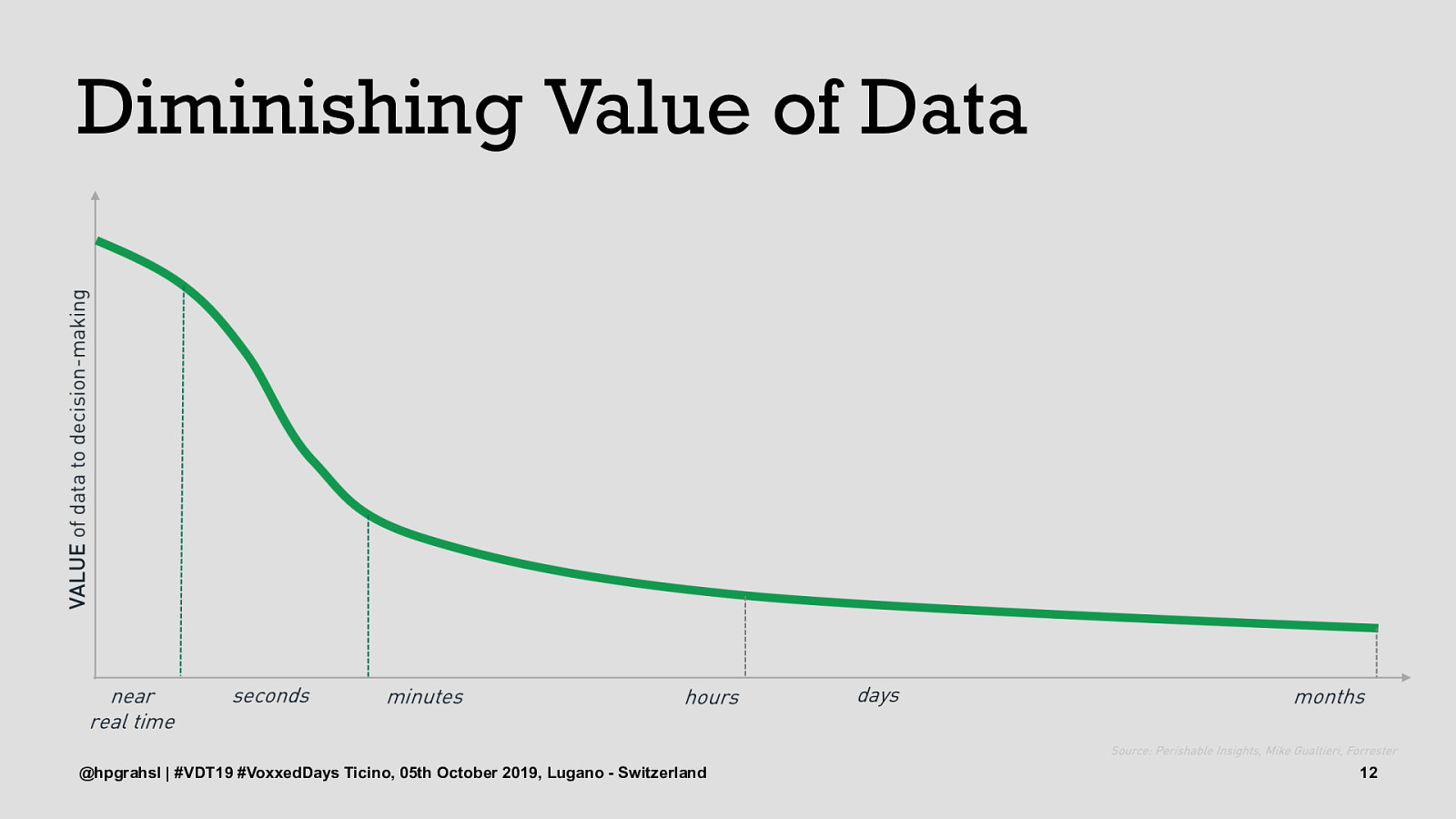
Diminishing Value of Data @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 9
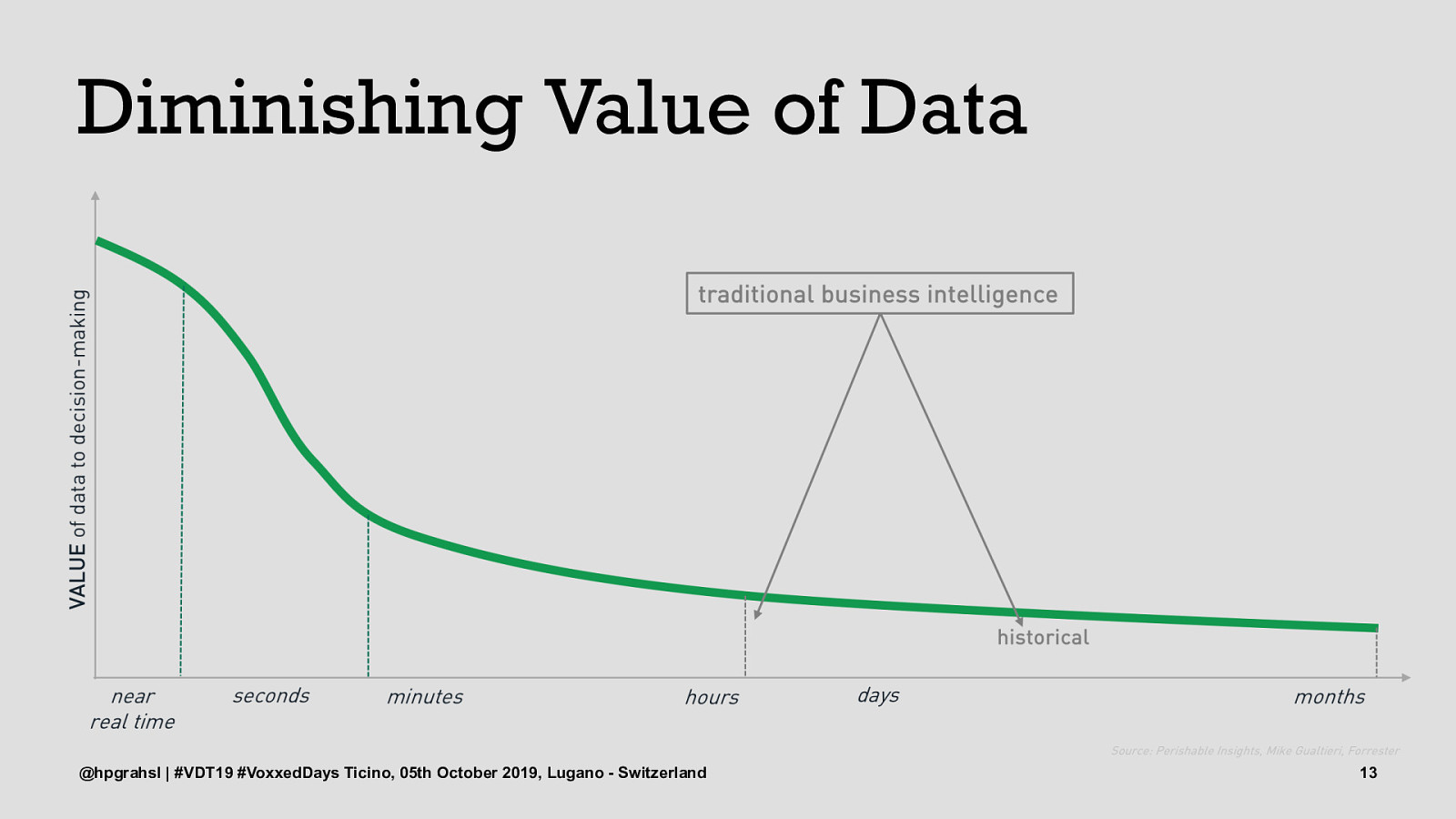
Diminishing Value of Data @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 10
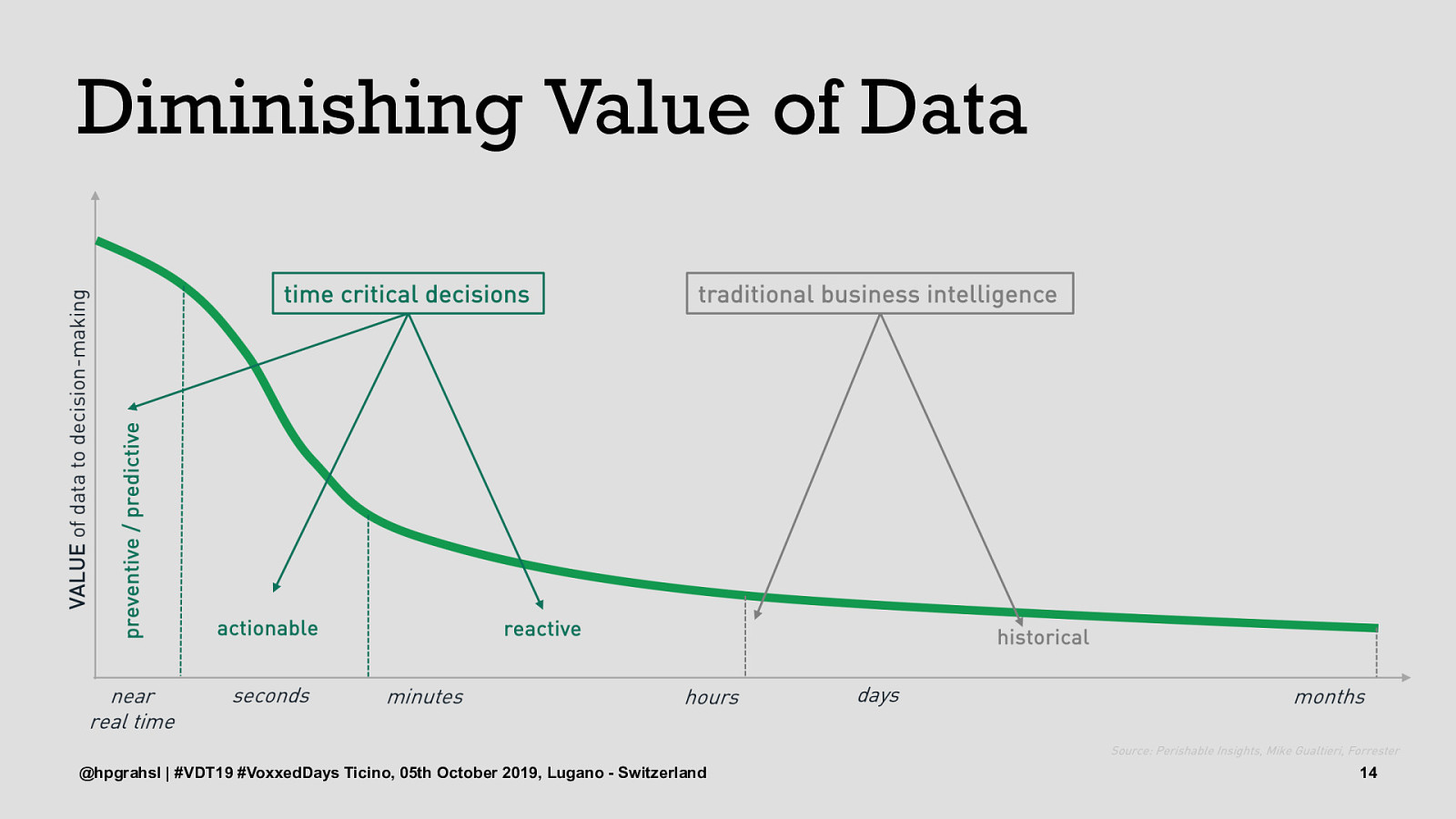
Diminishing Value of Data @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 11
Diminishing Value of Data @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 12
Diminishing Value of Data @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 13
Diminishing Value of Data @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 14
Historic ETL causes Pain • batch-driven • brittle / error prone • slow & late answers @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 15
Antipattern for Speed & Agility @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 16
Streaming ETL alleviates Pain • event-centric • stream-oriented • fast & timely answers @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 17
Enabler for Speed & Agility @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 18
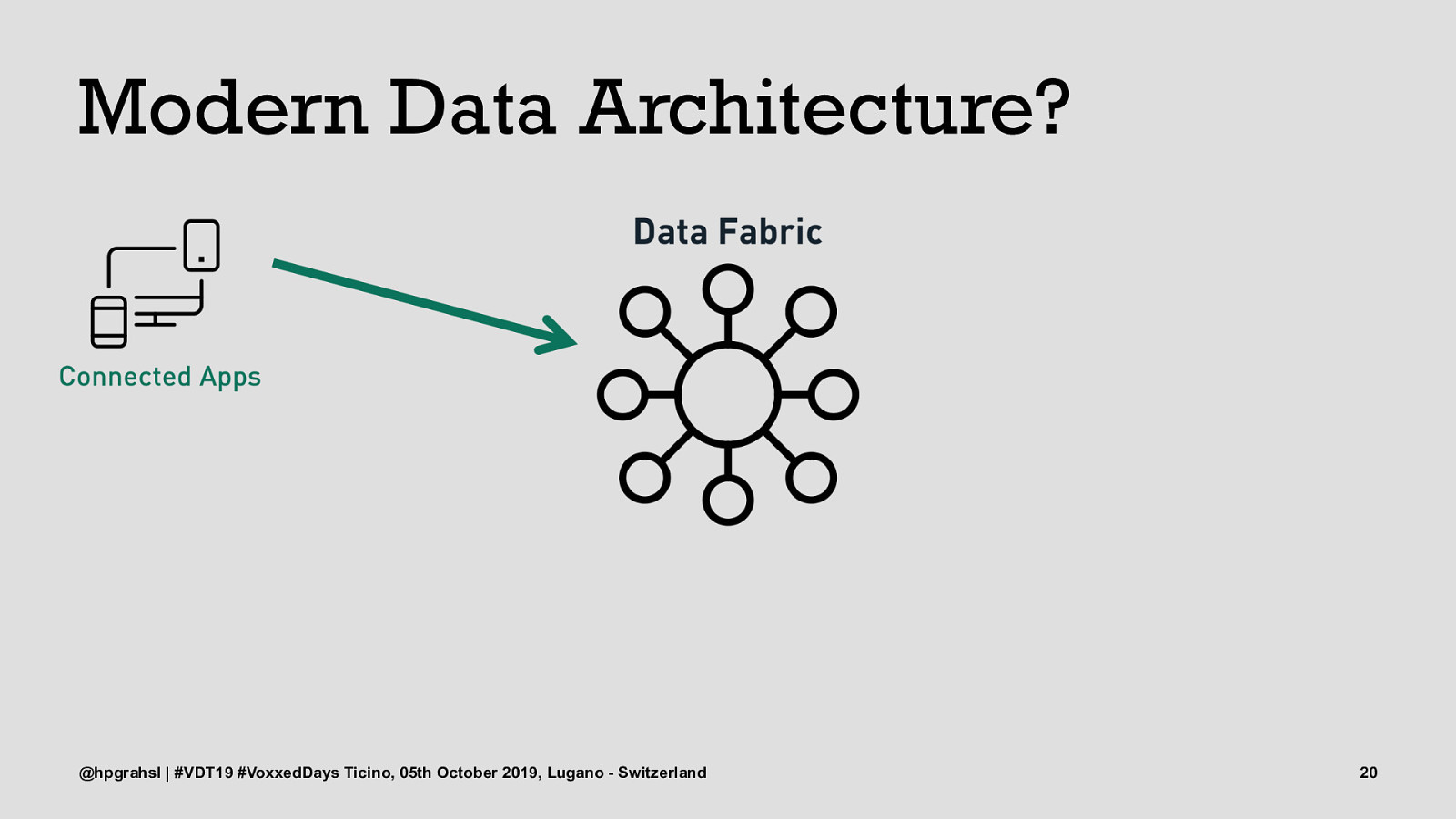
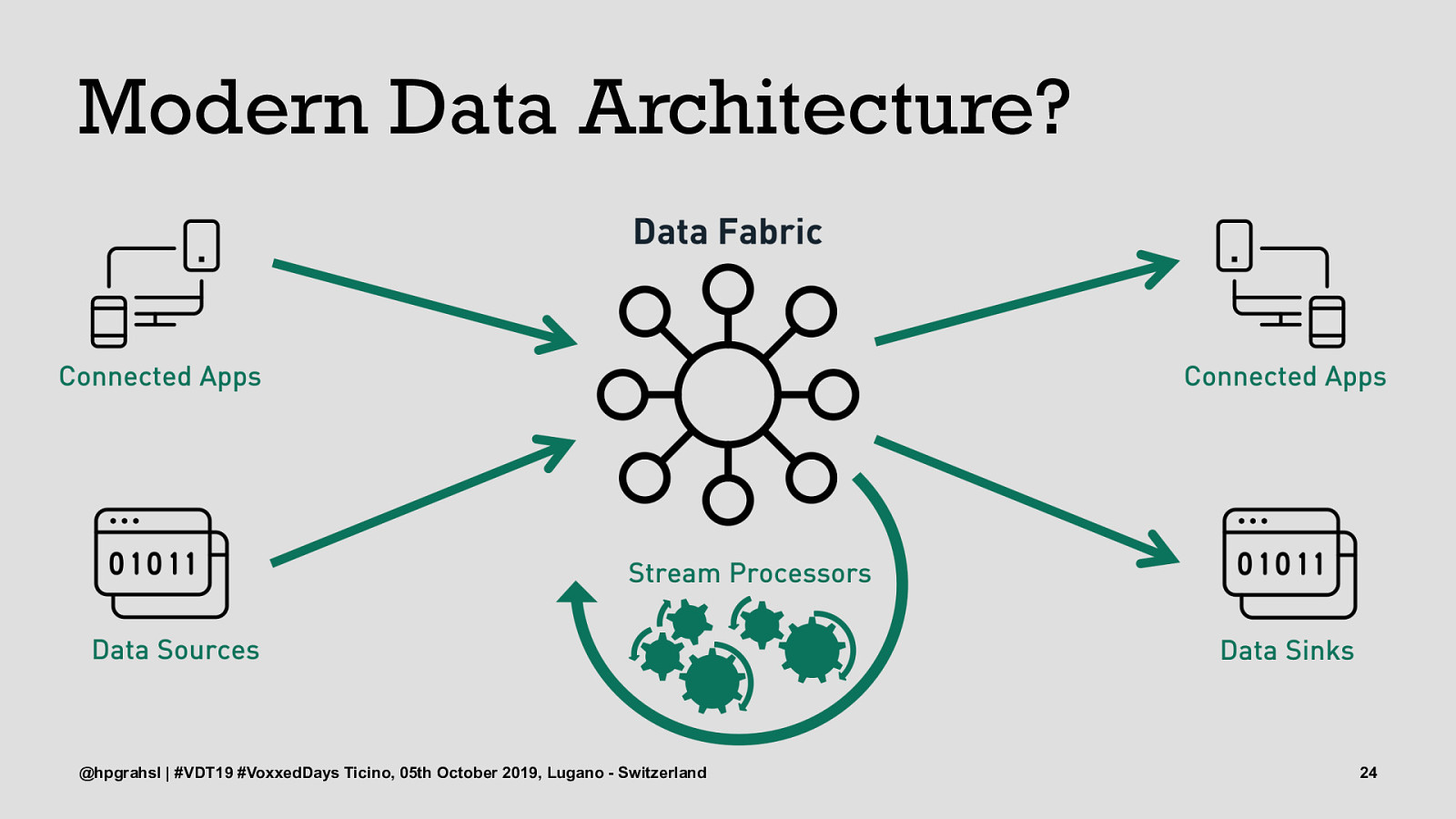
Modern Data Architecture? @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 19
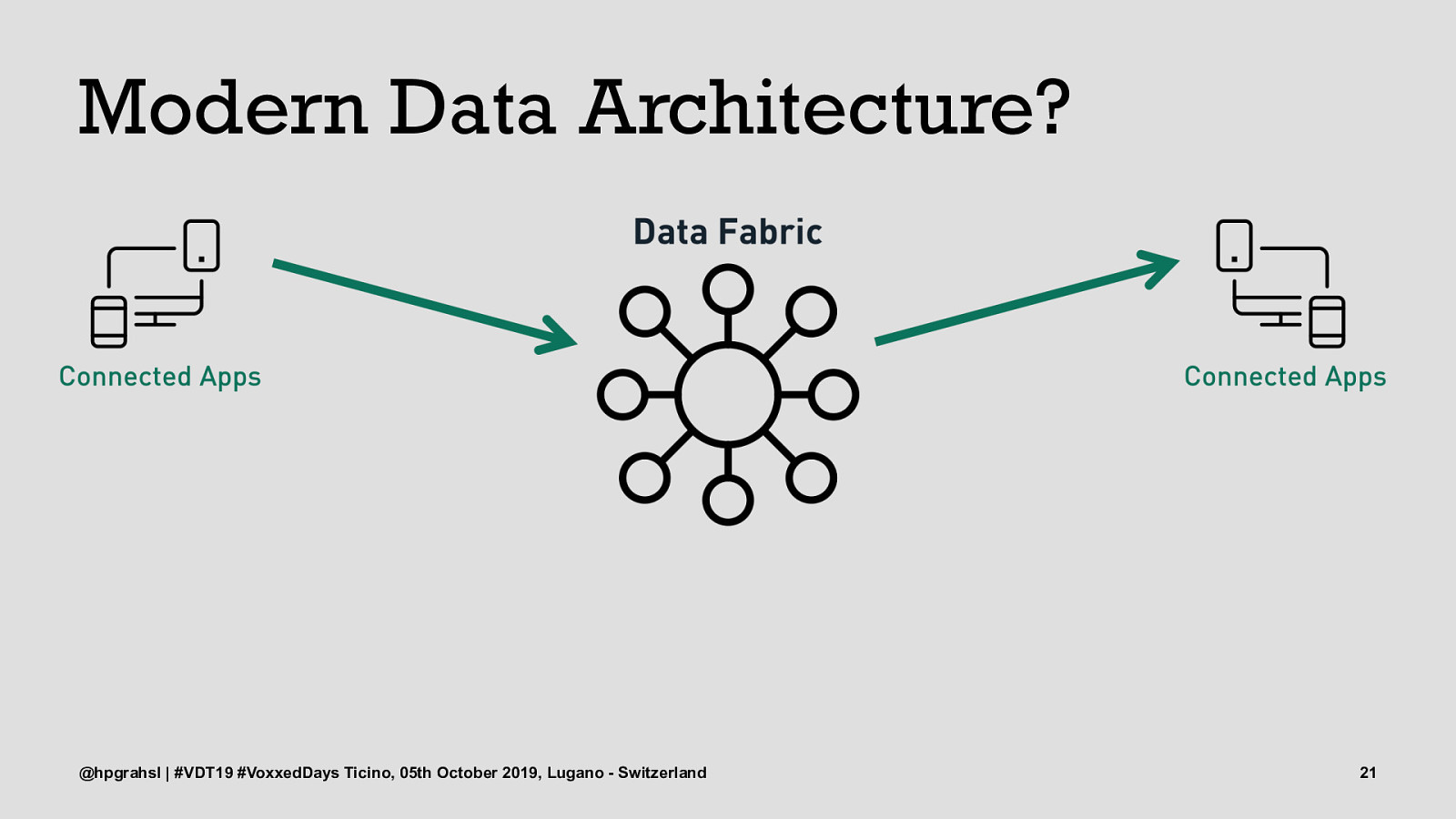
Modern Data Architecture? @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 20
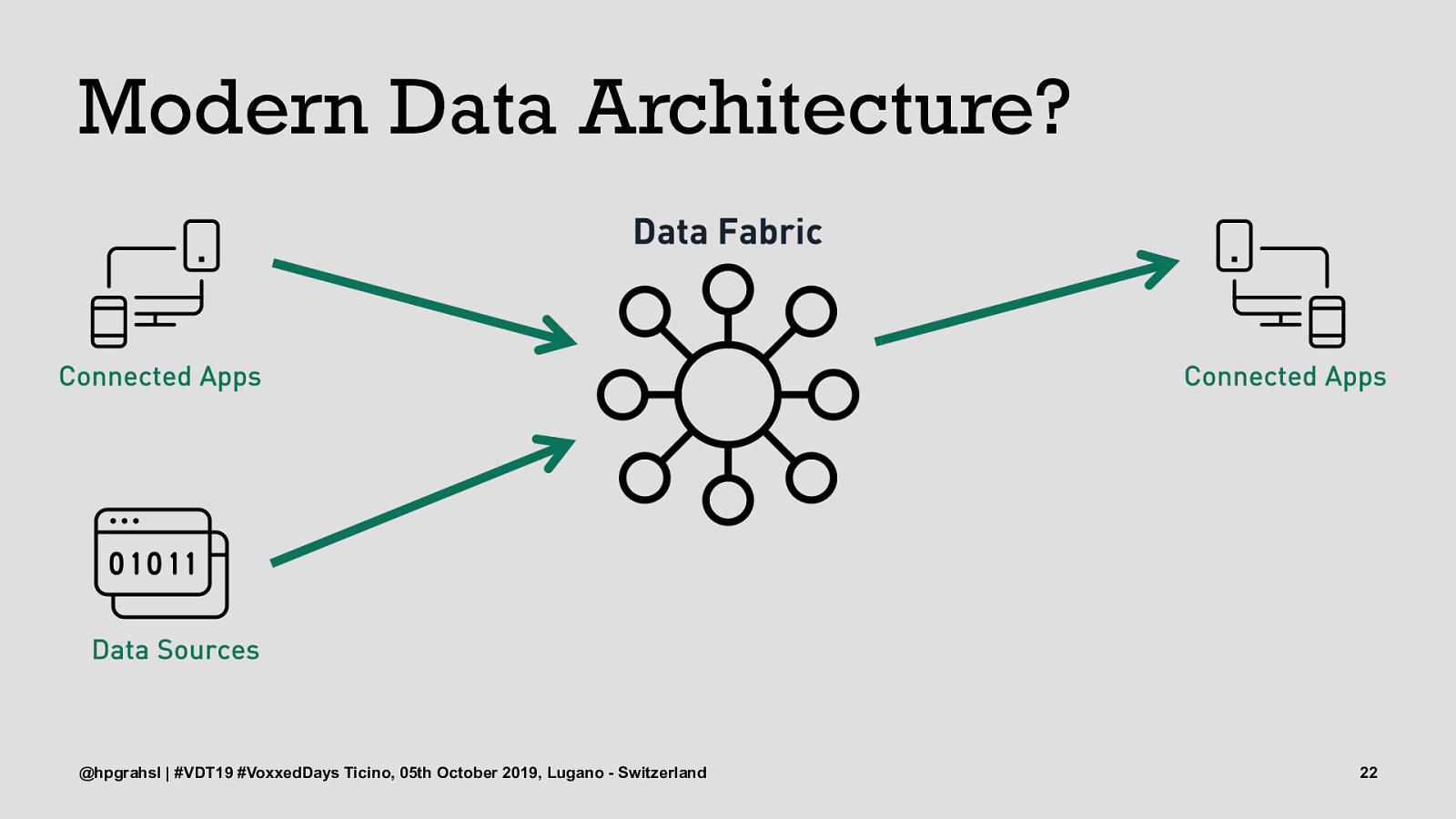
Modern Data Architecture? @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 21
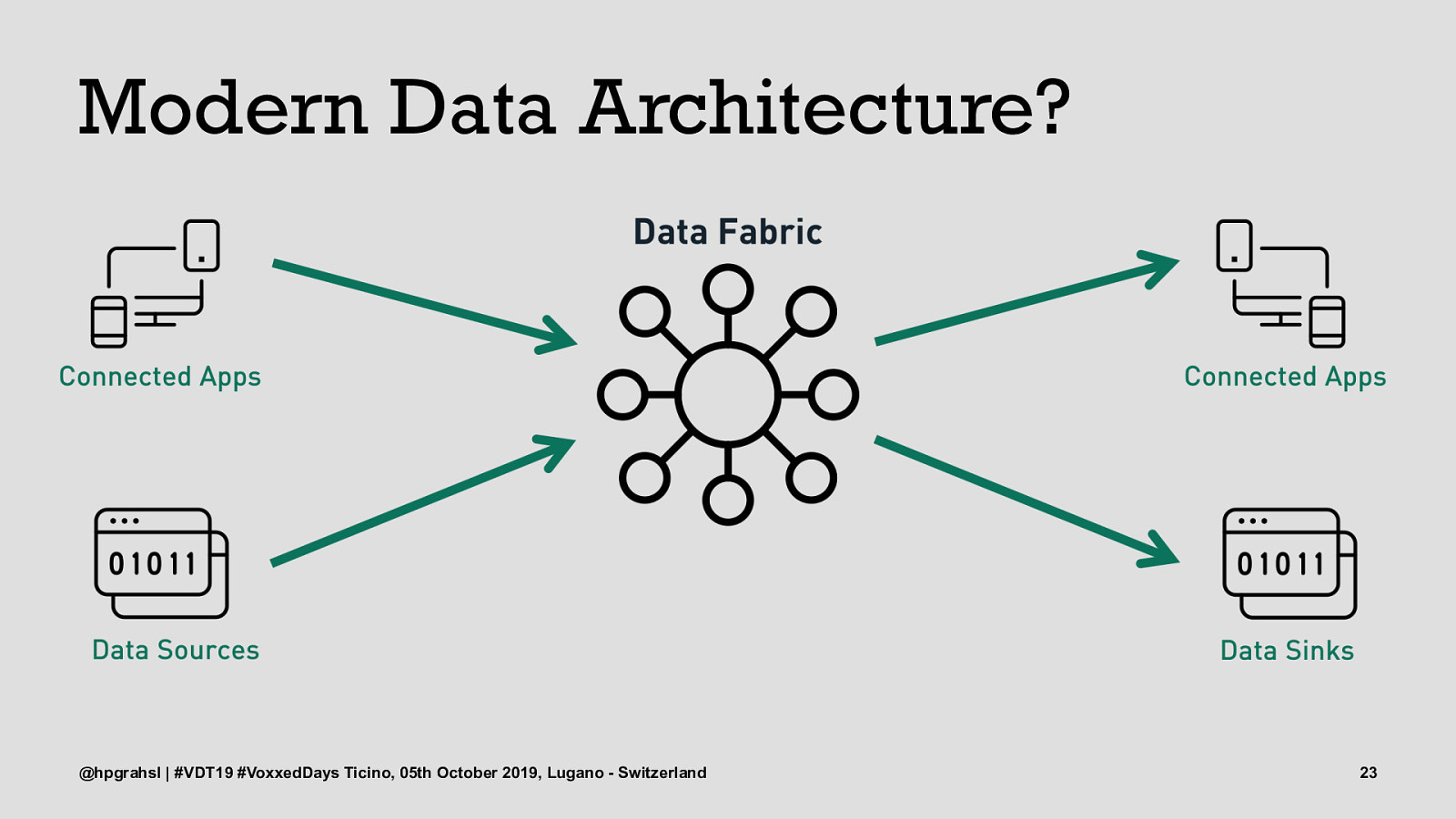
Modern Data Architecture? @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 22
Modern Data Architecture? @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 23
Modern Data Architecture? @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 24
On the Shoulders of G I A N T S @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 25
Operational Data Store @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 26
MongoDB • rich document model • powerful queries & indexing • ACID transactions • transparent sharding & replication @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 27
Streaming Platform @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 28
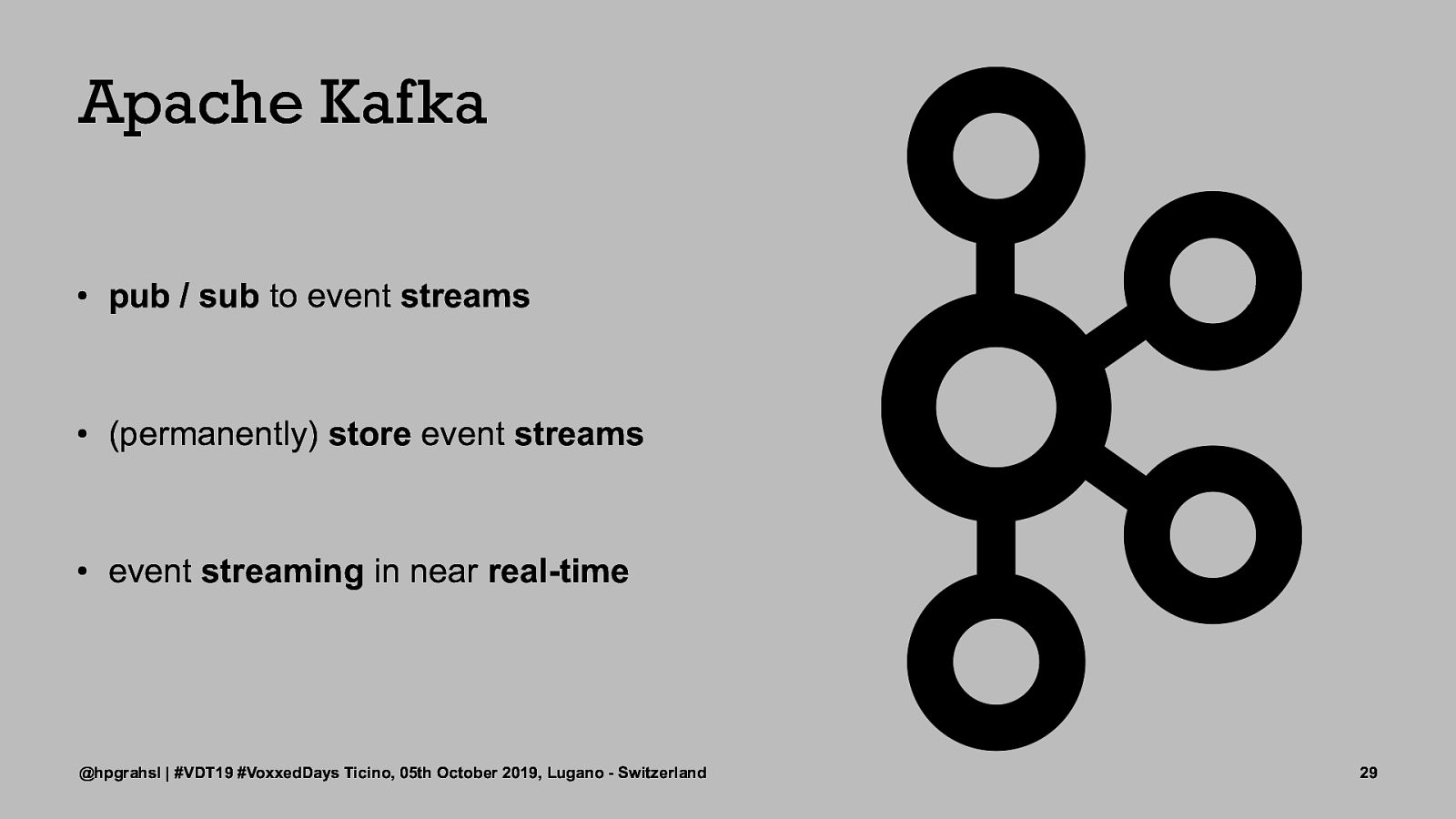
Apache Kafka • pub / sub to event streams • (permanently) store event streams • event streaming in near real-time @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 29
@hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 30
“… data processing that is designed with infinite data sets in mind.” — Tyler Akidau @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 31
EVENTS EVENTS EVERYWHERE! @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 32
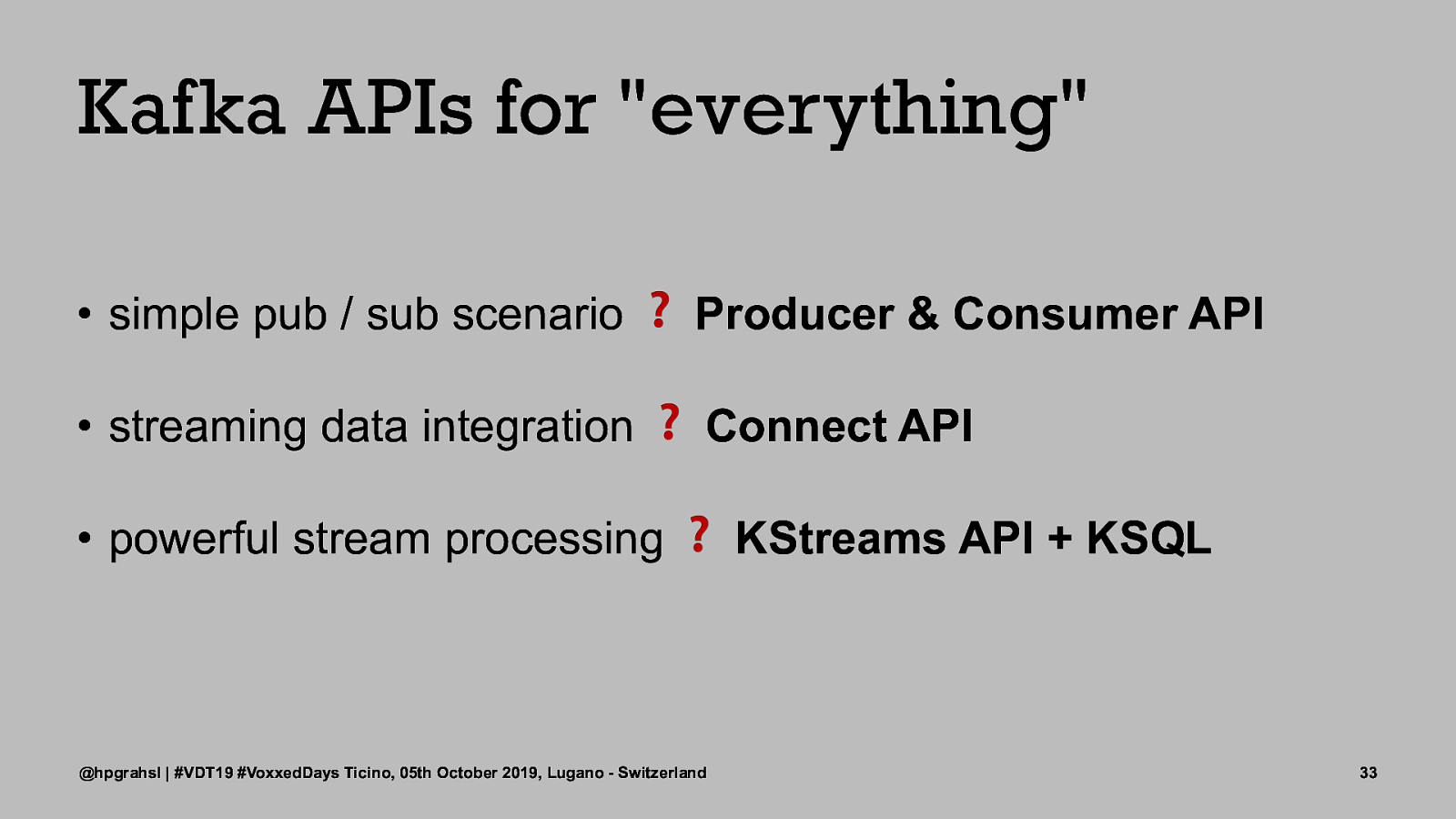
Kafka APIs for “everything” • simple pub / sub scenario Producer & Consumer API • streaming data integration Connect API • powerful stream processing @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland ❓ ❓❓ KStreams API + KSQL 33
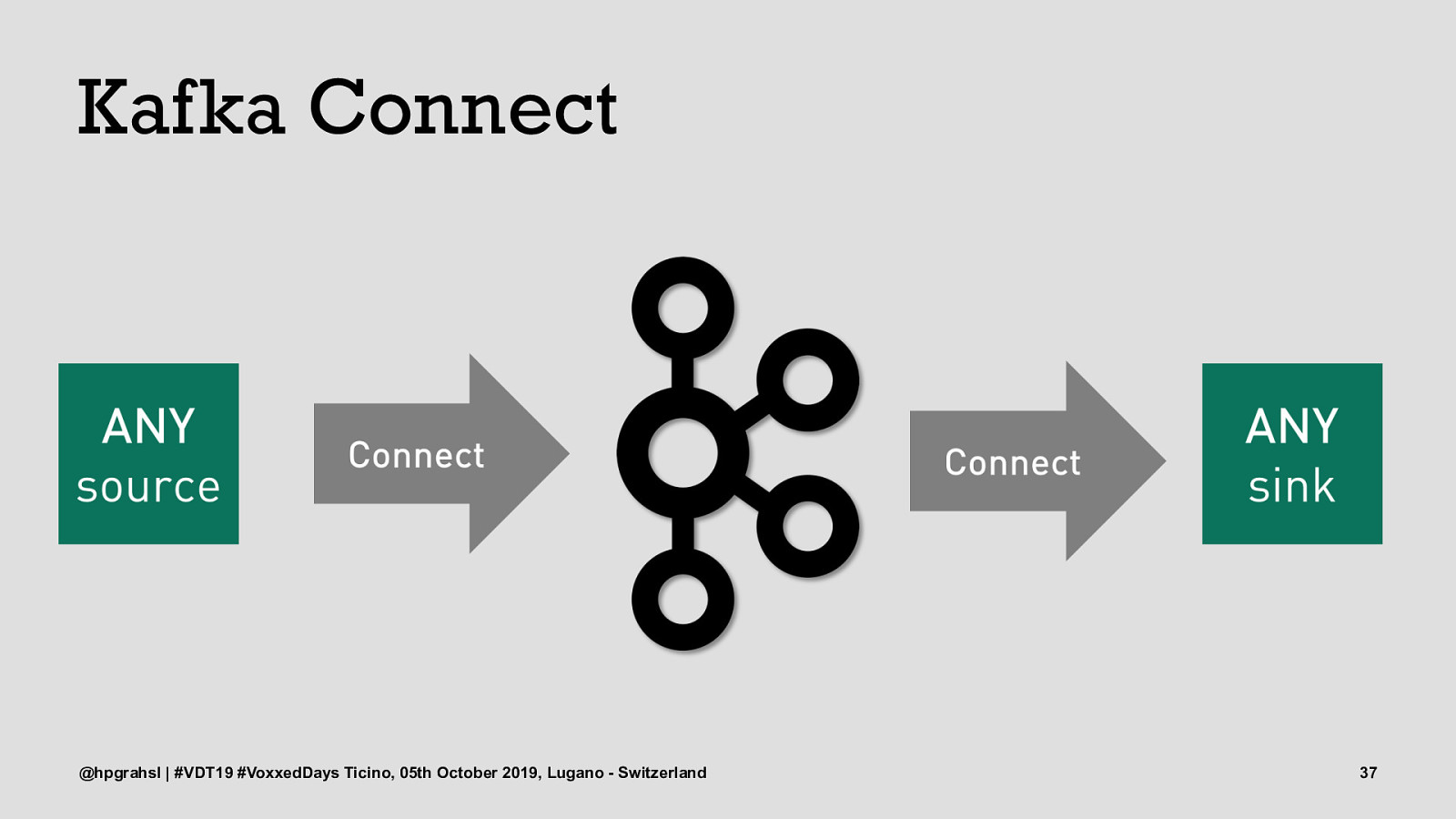
Kafka Connect @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 34
Kafka Connect @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 35
Kafka Connect @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 36
Kafka Connect @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 37
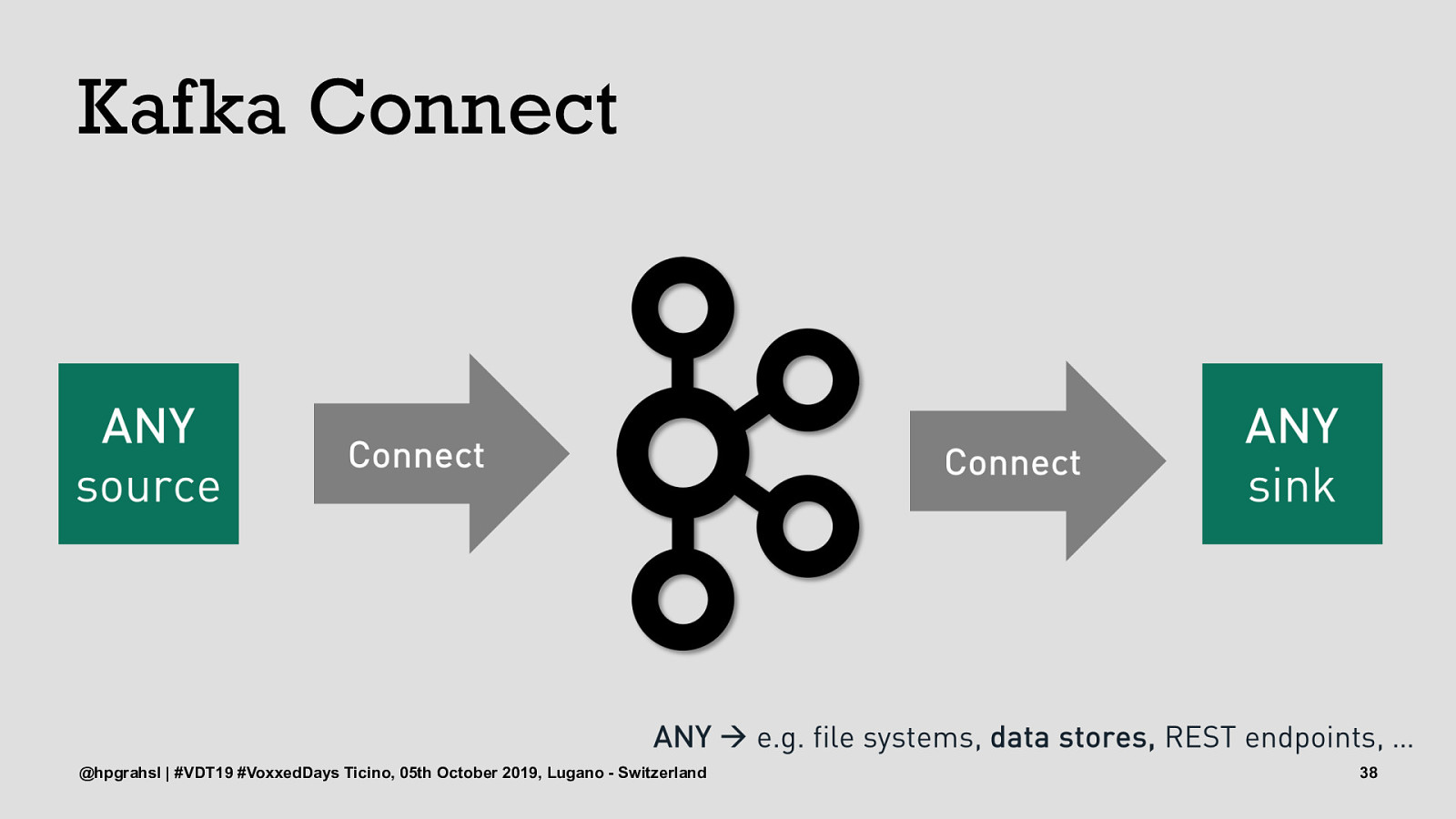
Kafka Connect @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 38
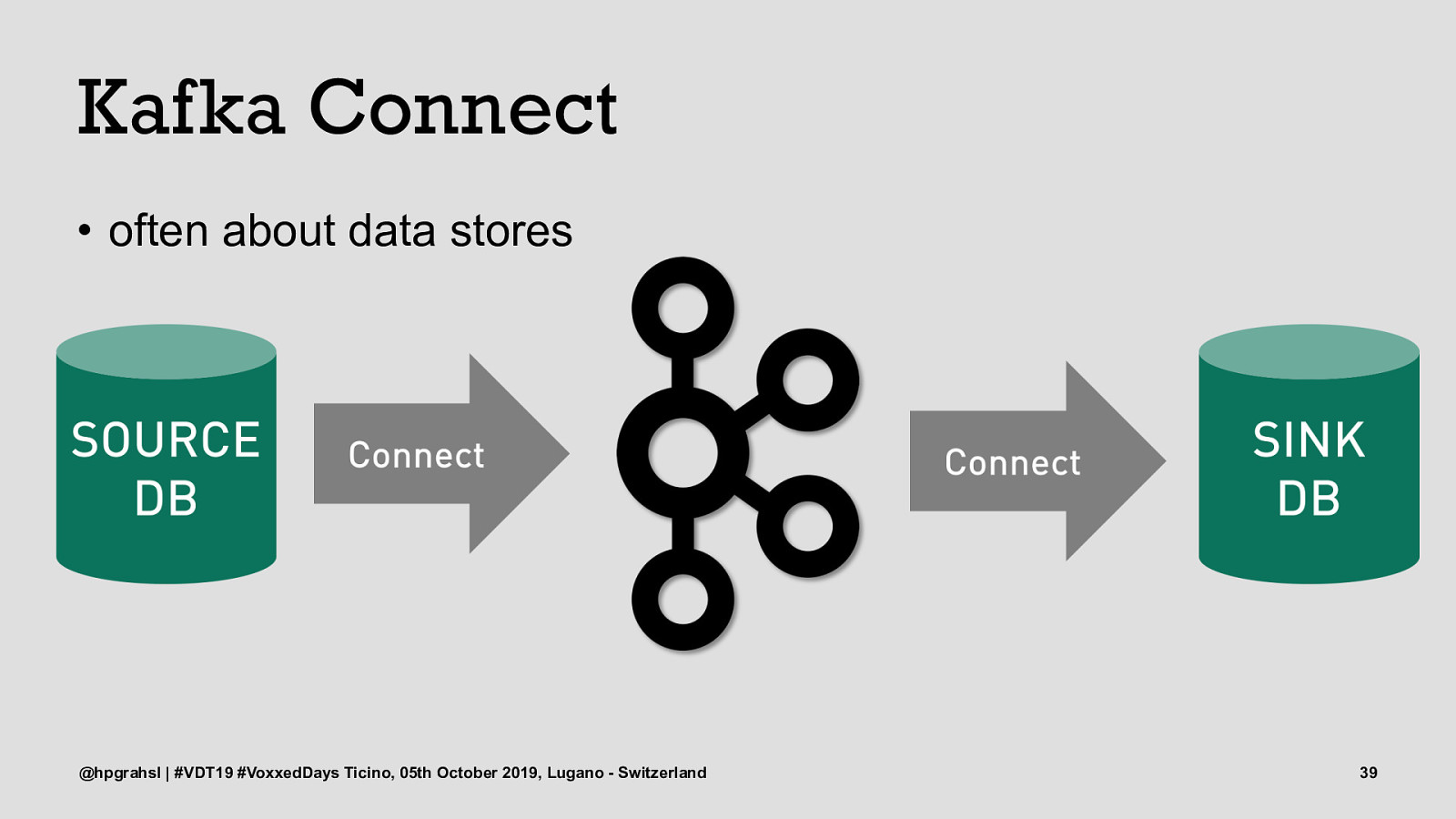
Kafka Connect • often about data stores @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 39
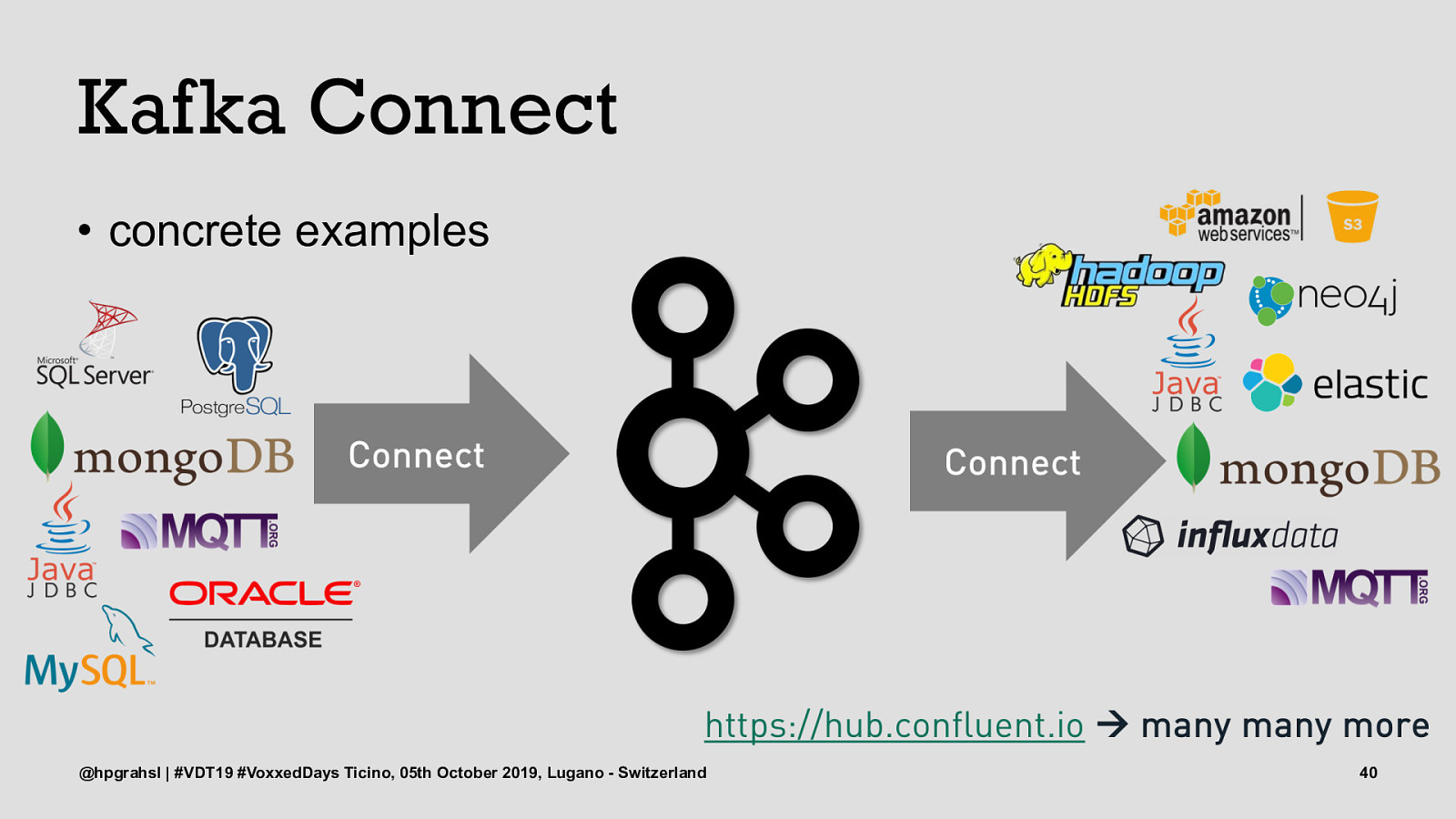
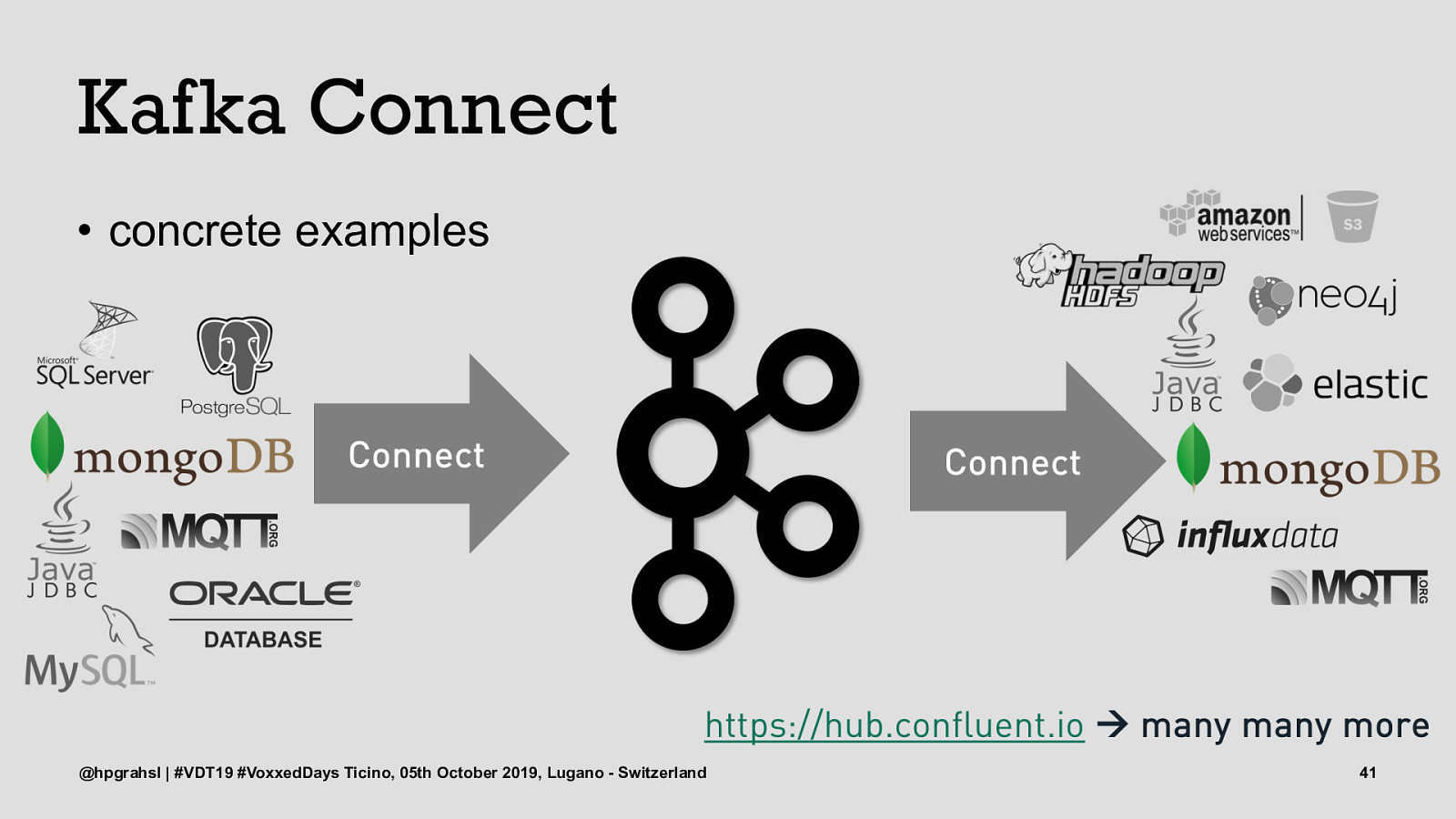
Kafka Connect • concrete examples @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 40
Kafka Connect • concrete examples @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 41
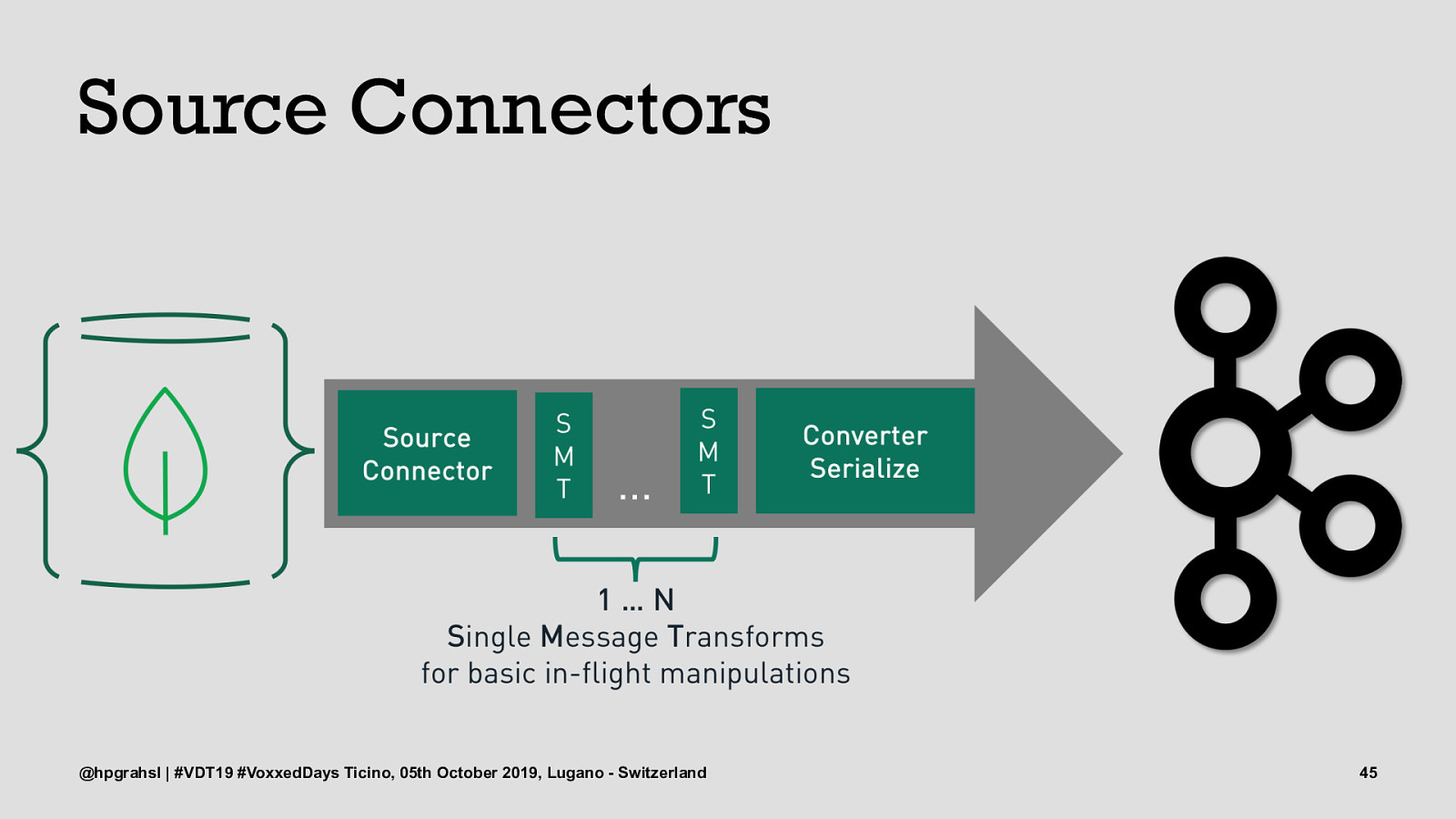
Source Connectors @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 42
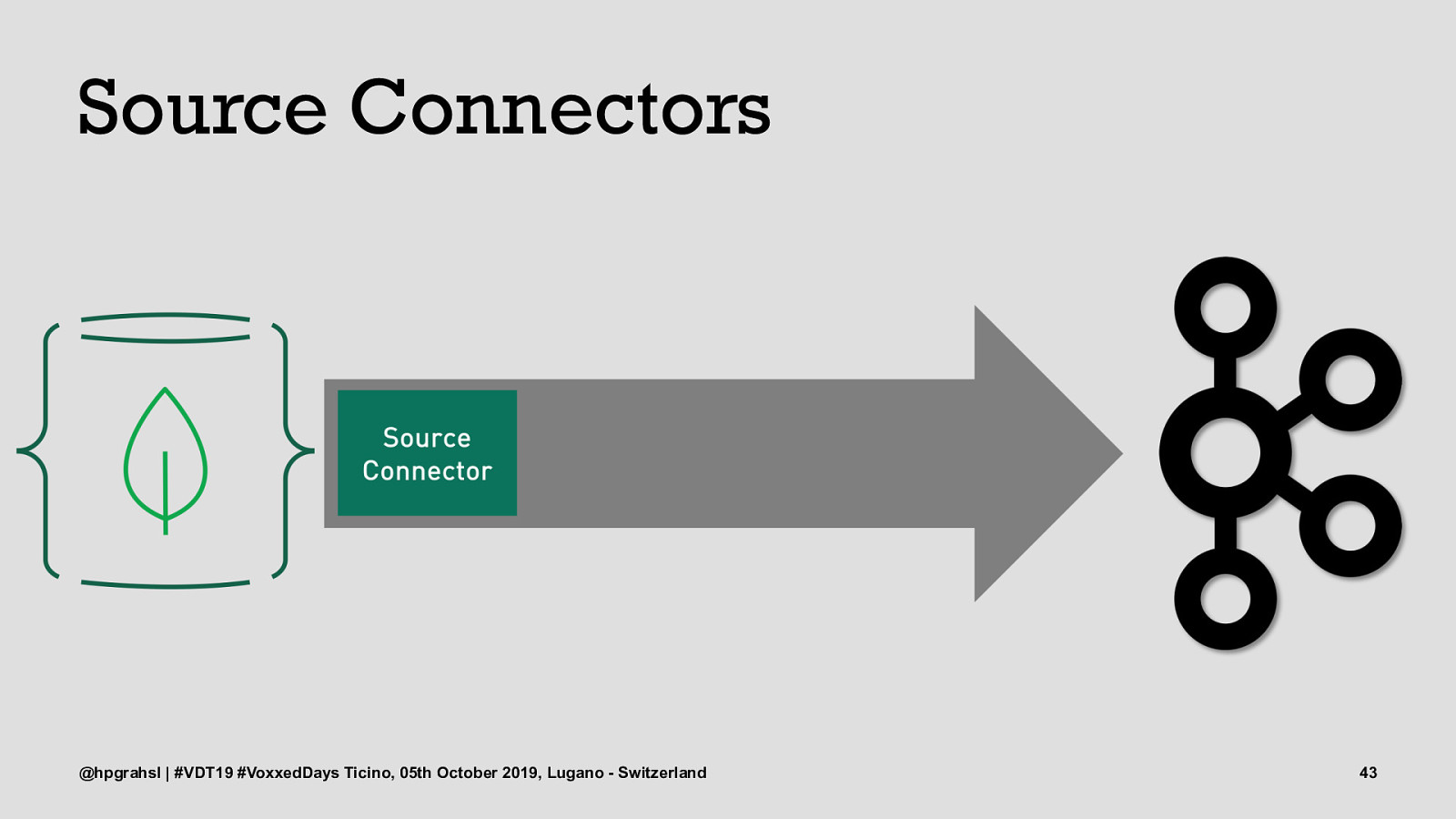
Source Connectors @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 43
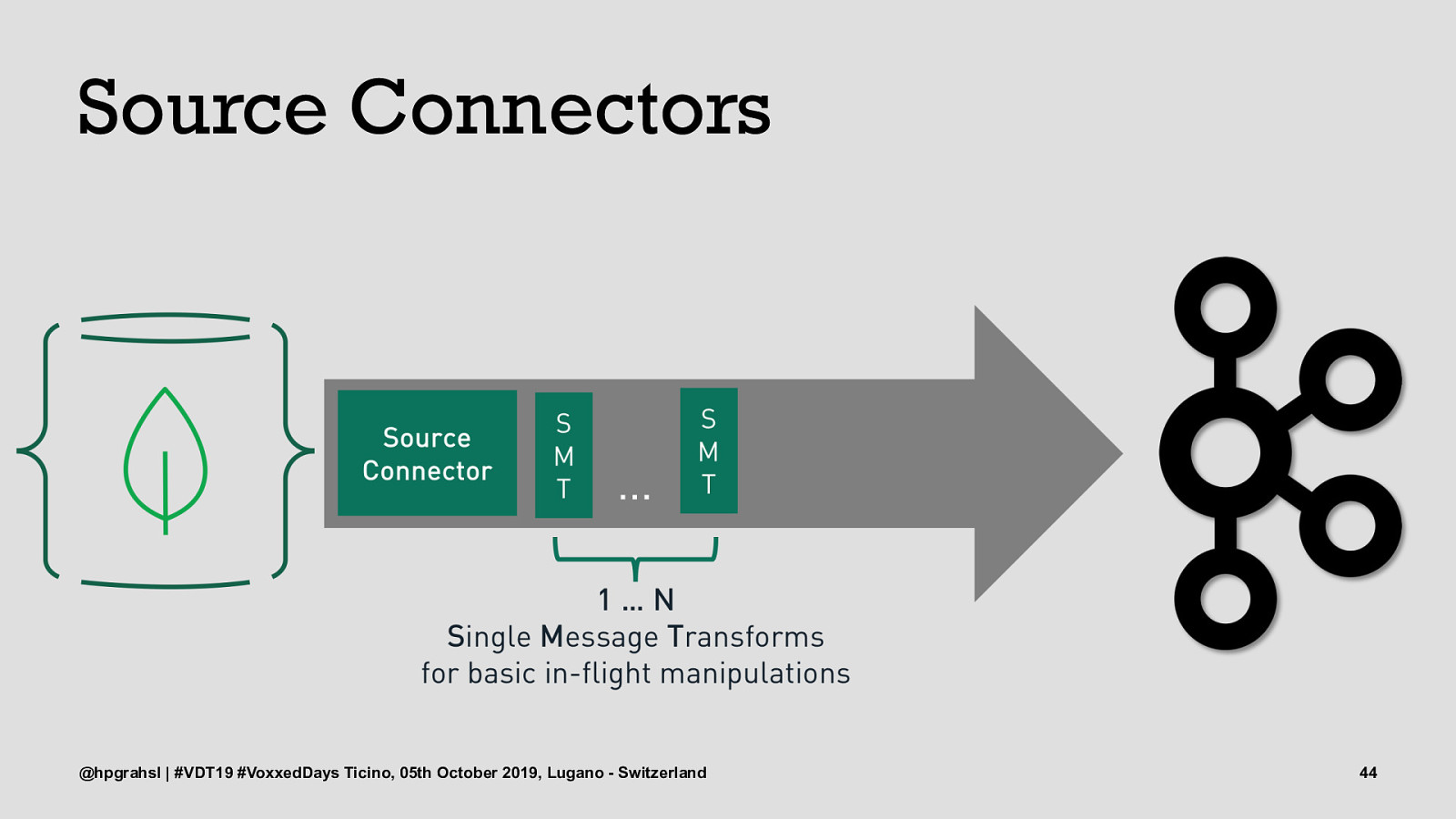
Source Connectors @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 44
Source Connectors @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 45
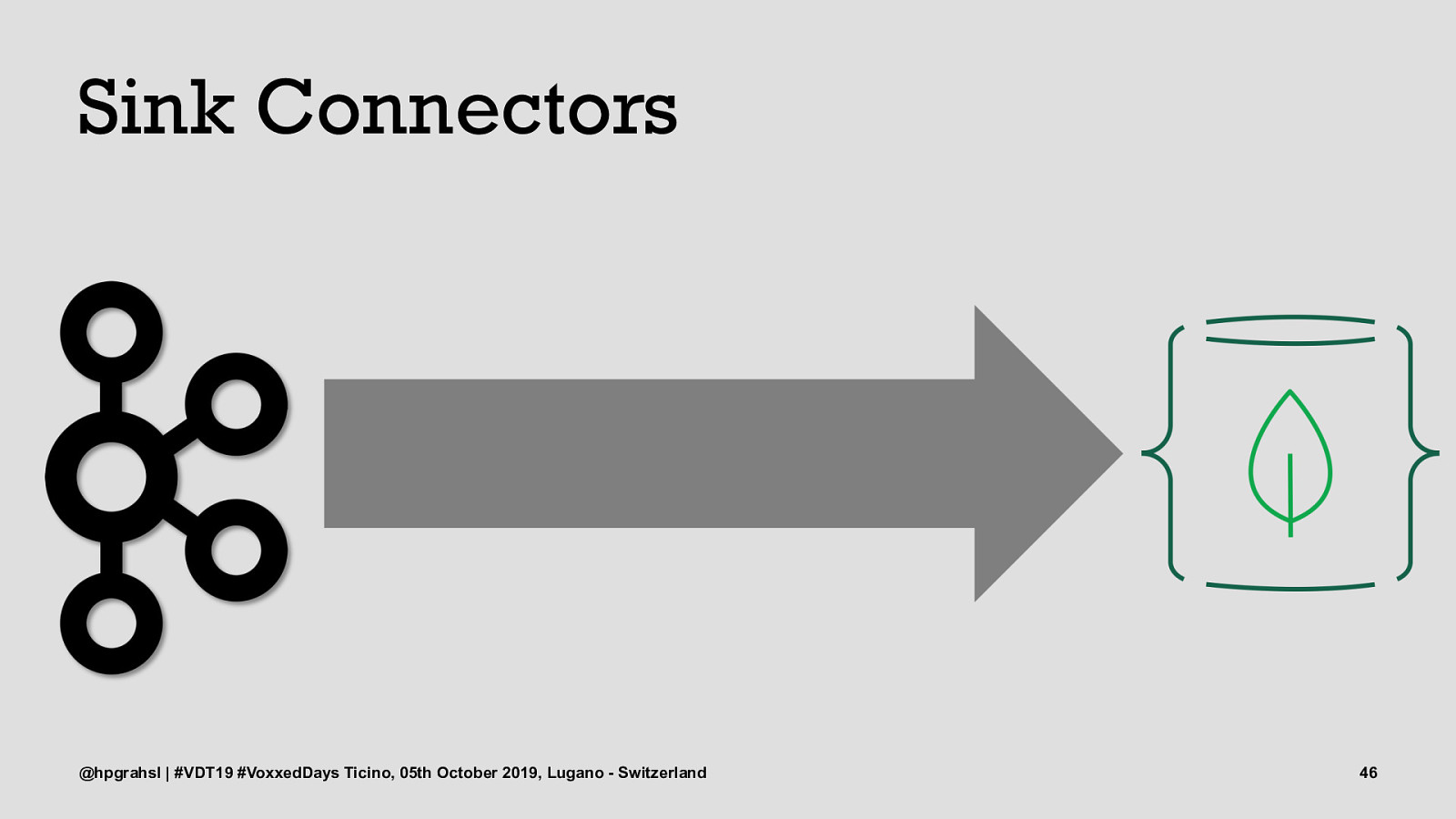
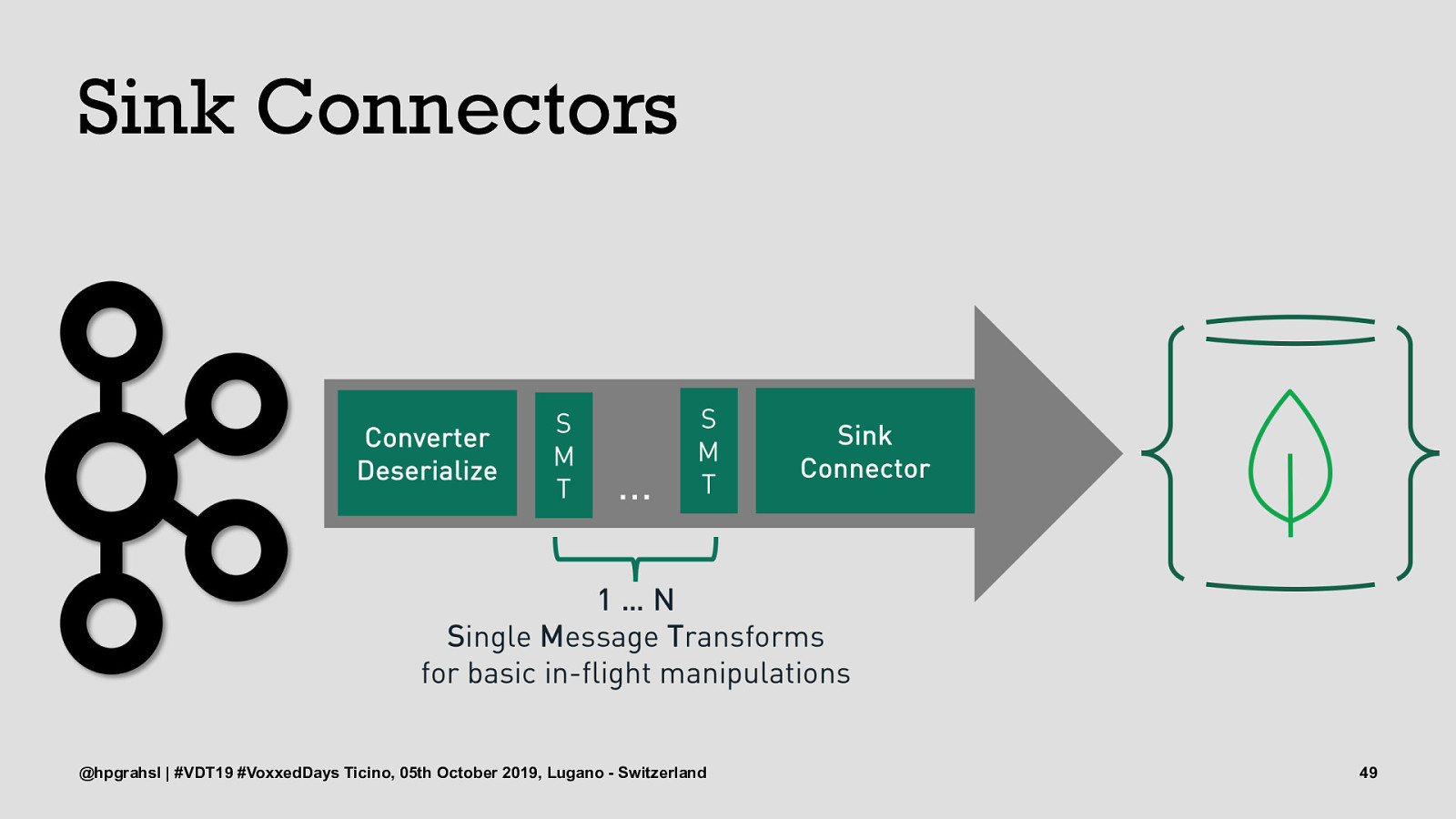
Sink Connectors @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 46
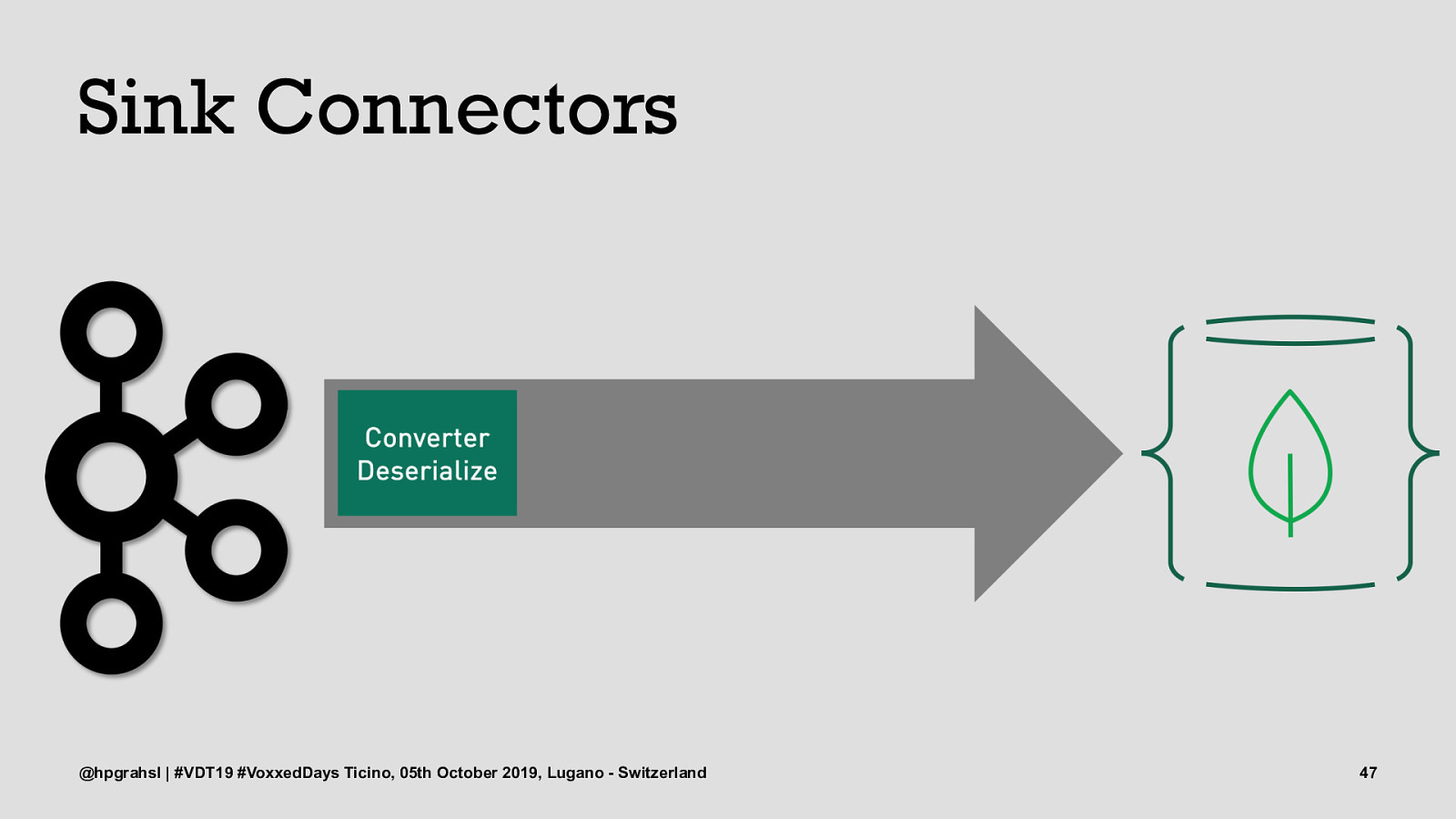
Sink Connectors @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 47
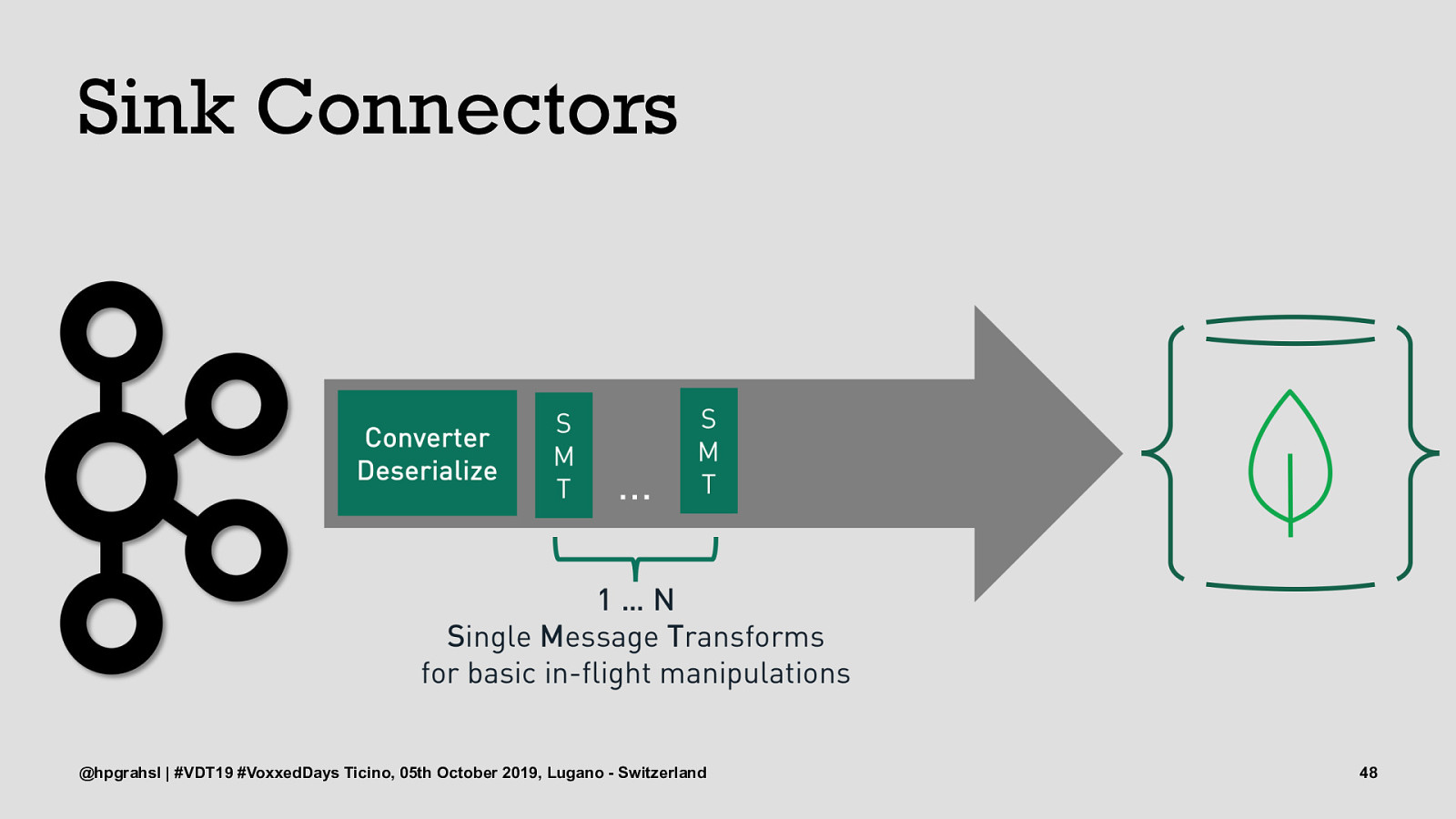
Sink Connectors @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 48
Sink Connectors @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 49
@hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 50
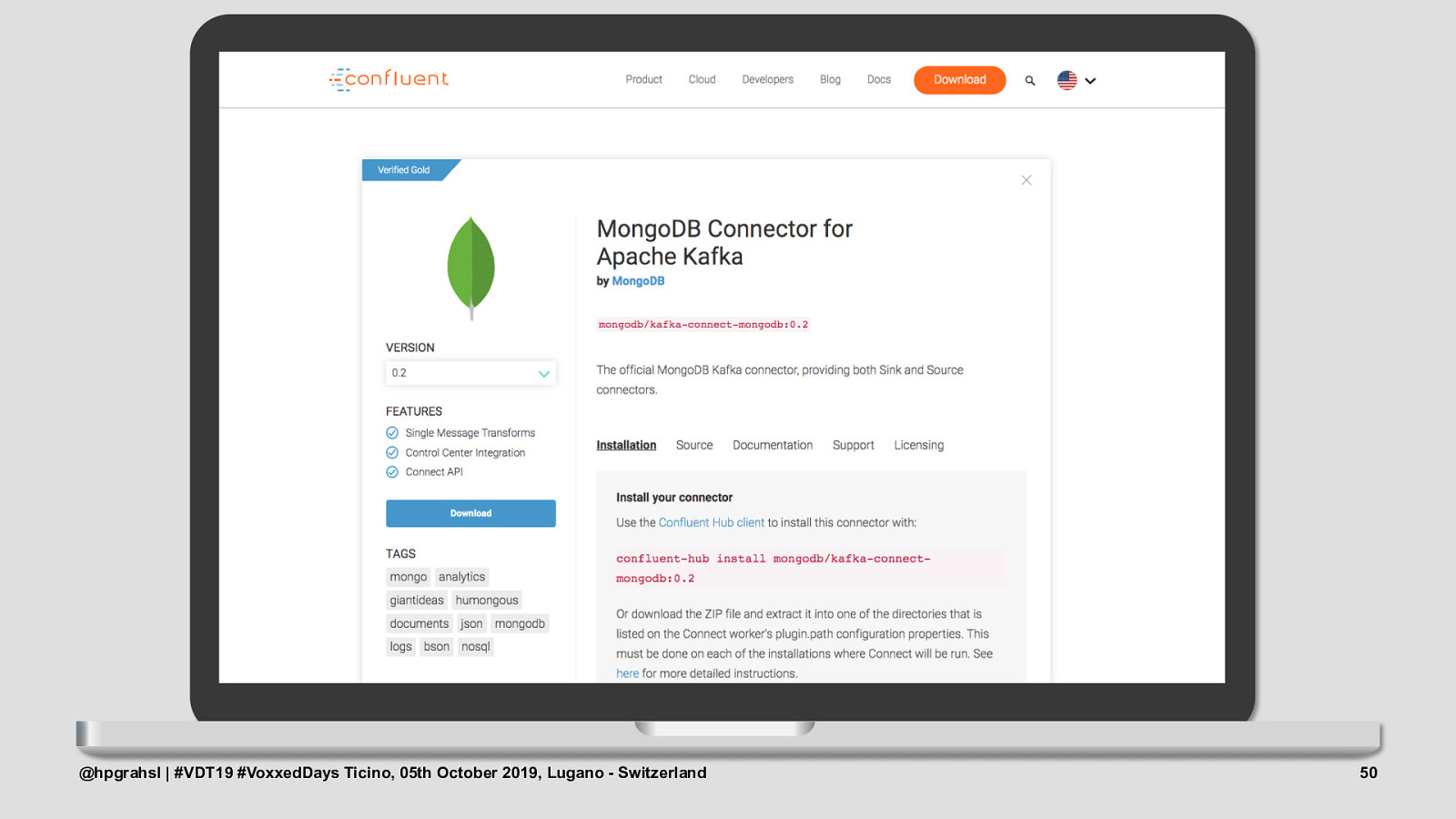
MongoDB Connector • officially supported by MongoDB • developed open-source on GitHub • verified Gold by Confluent @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 51
Exemplary Use Cases @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 52
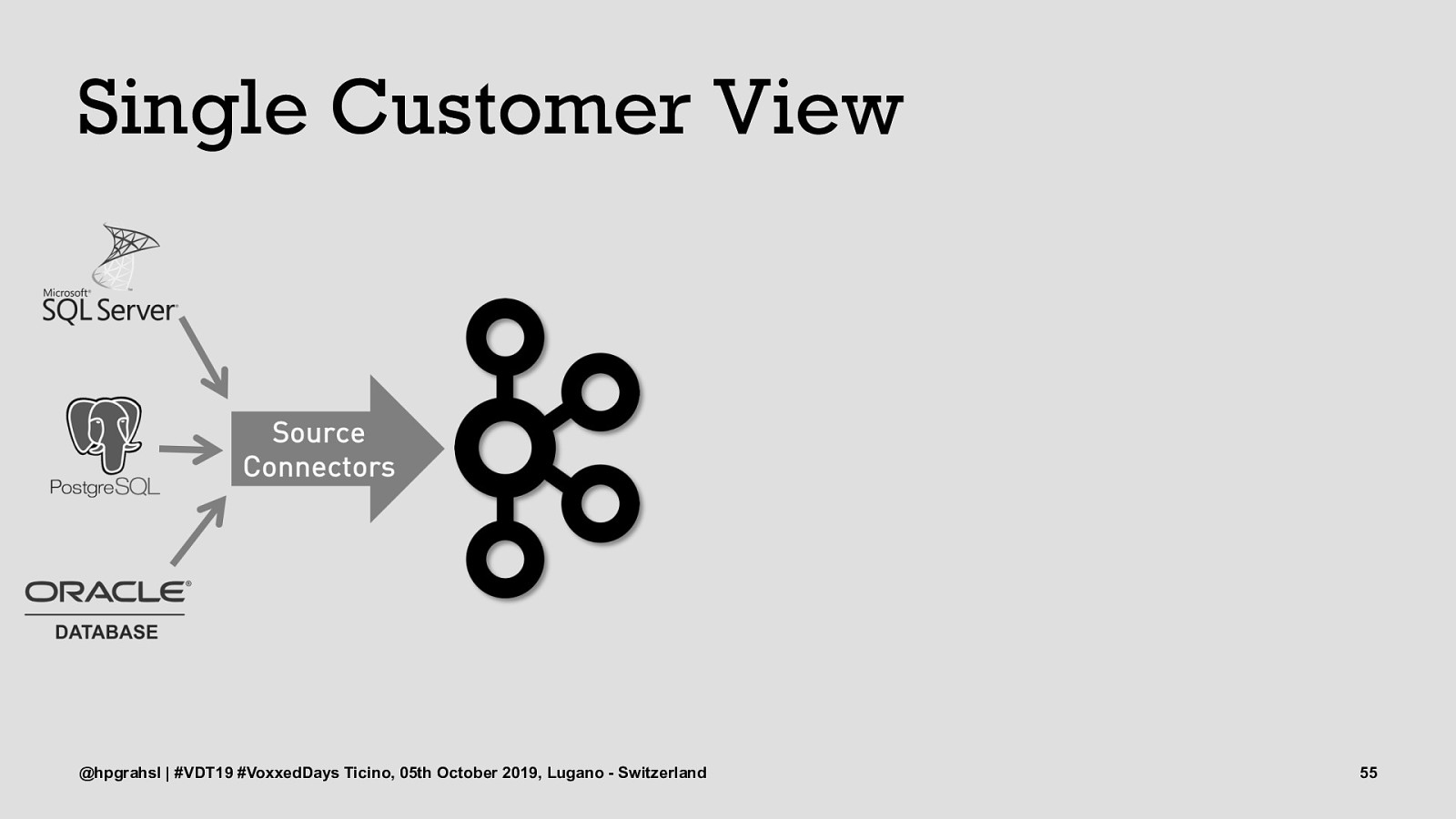
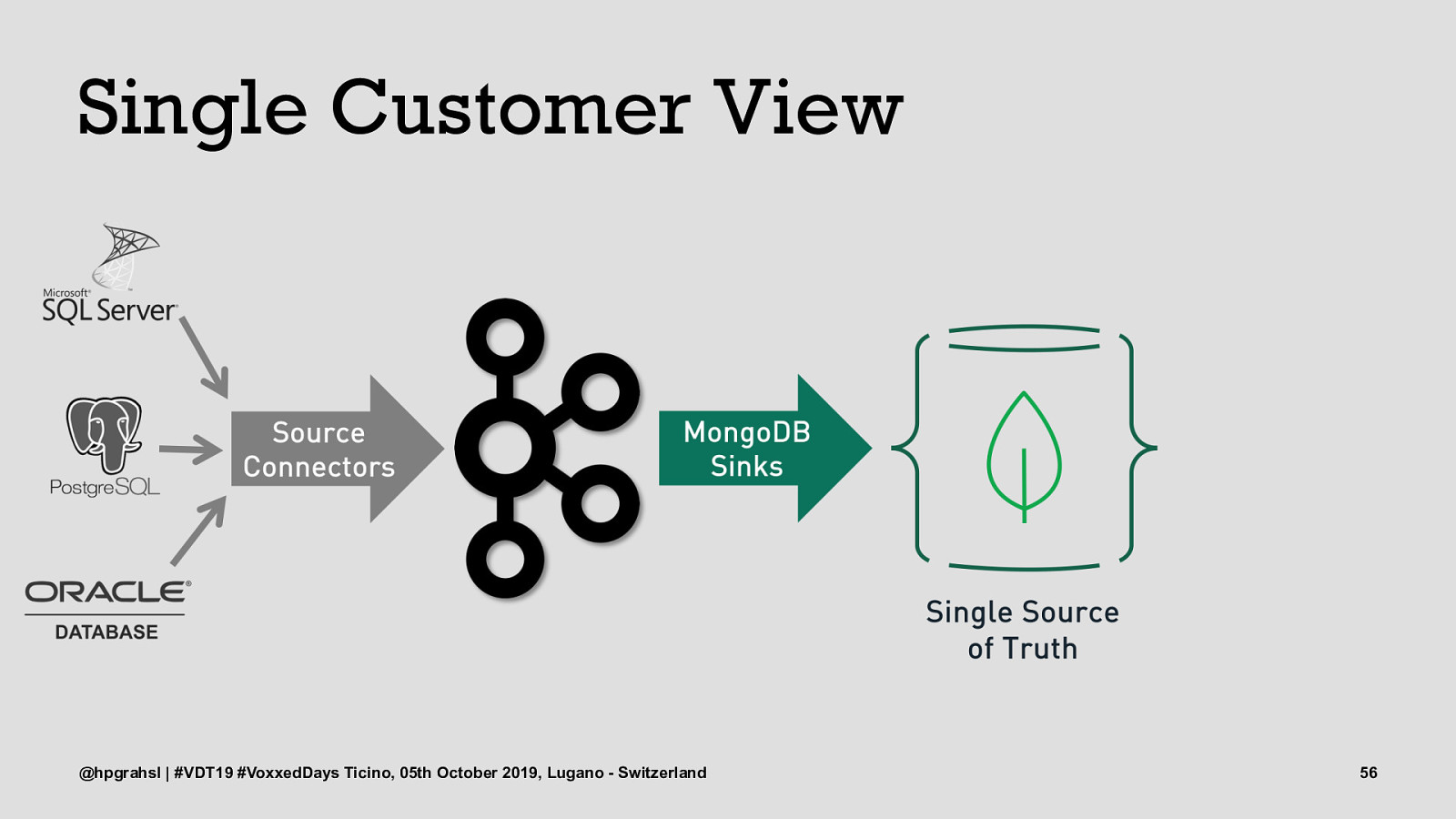
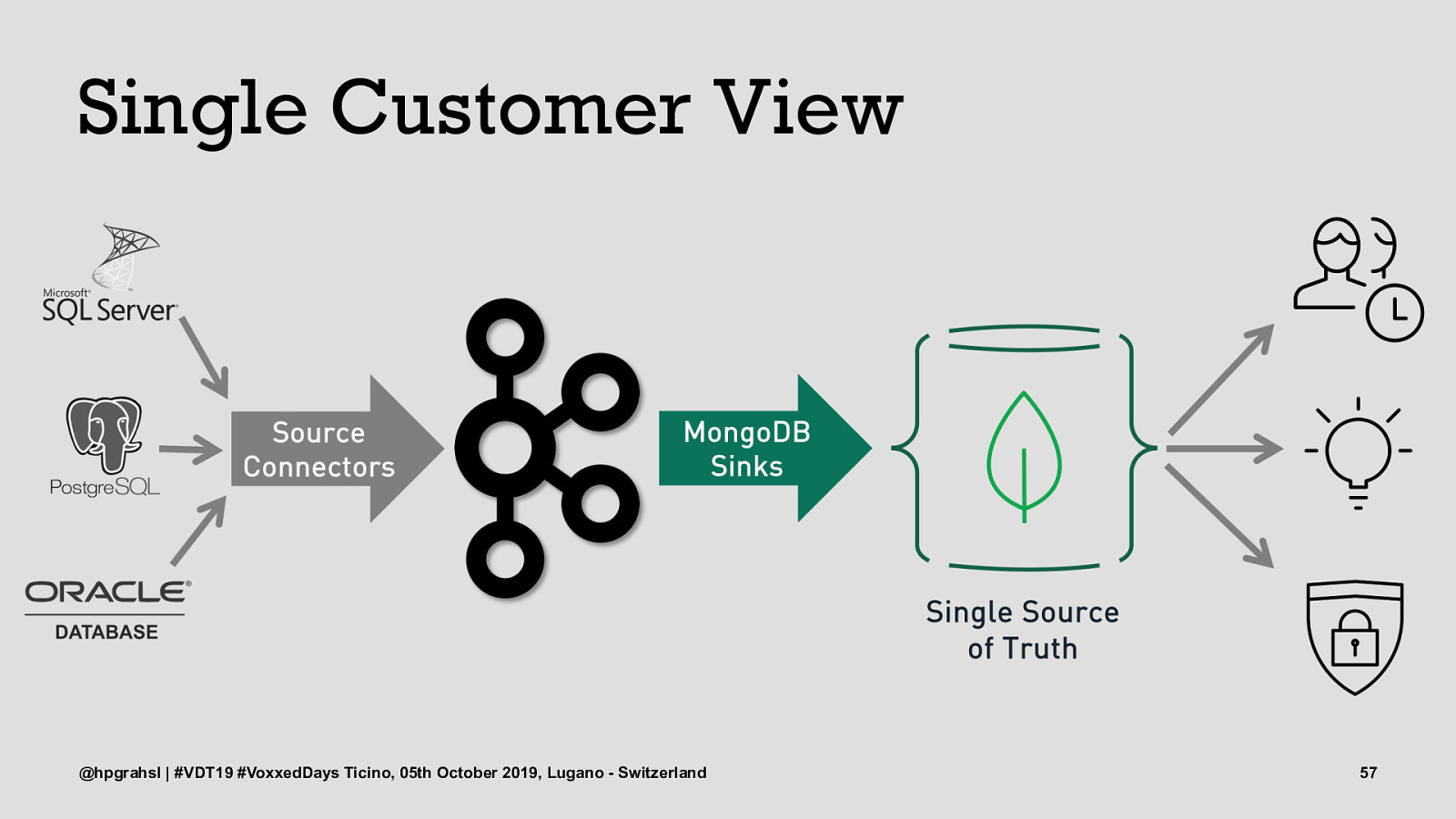
Single Customer View @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 53
Single Customer View @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 54
Single Customer View @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 55
Single Customer View @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 56
Single Customer View @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 57
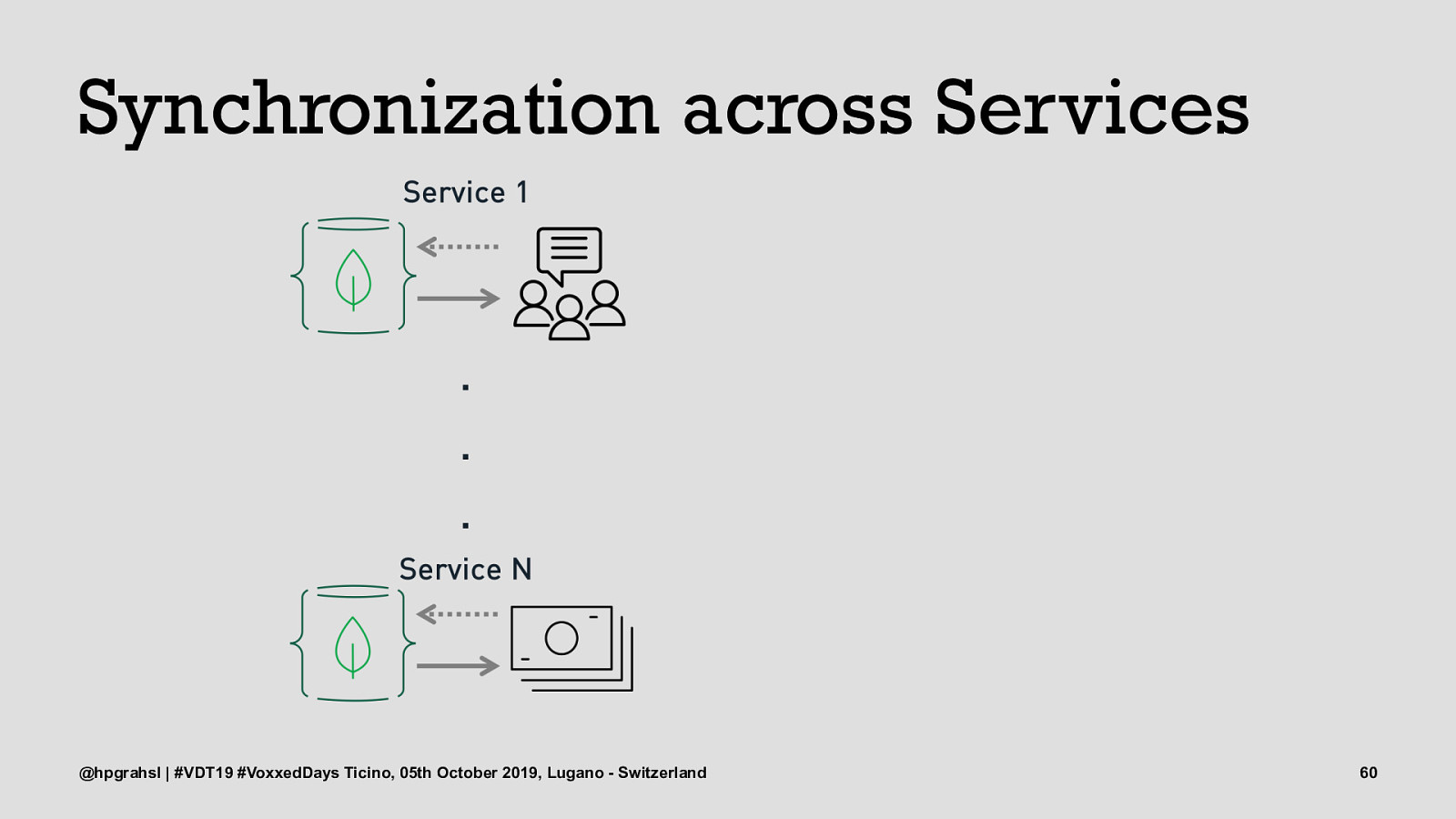
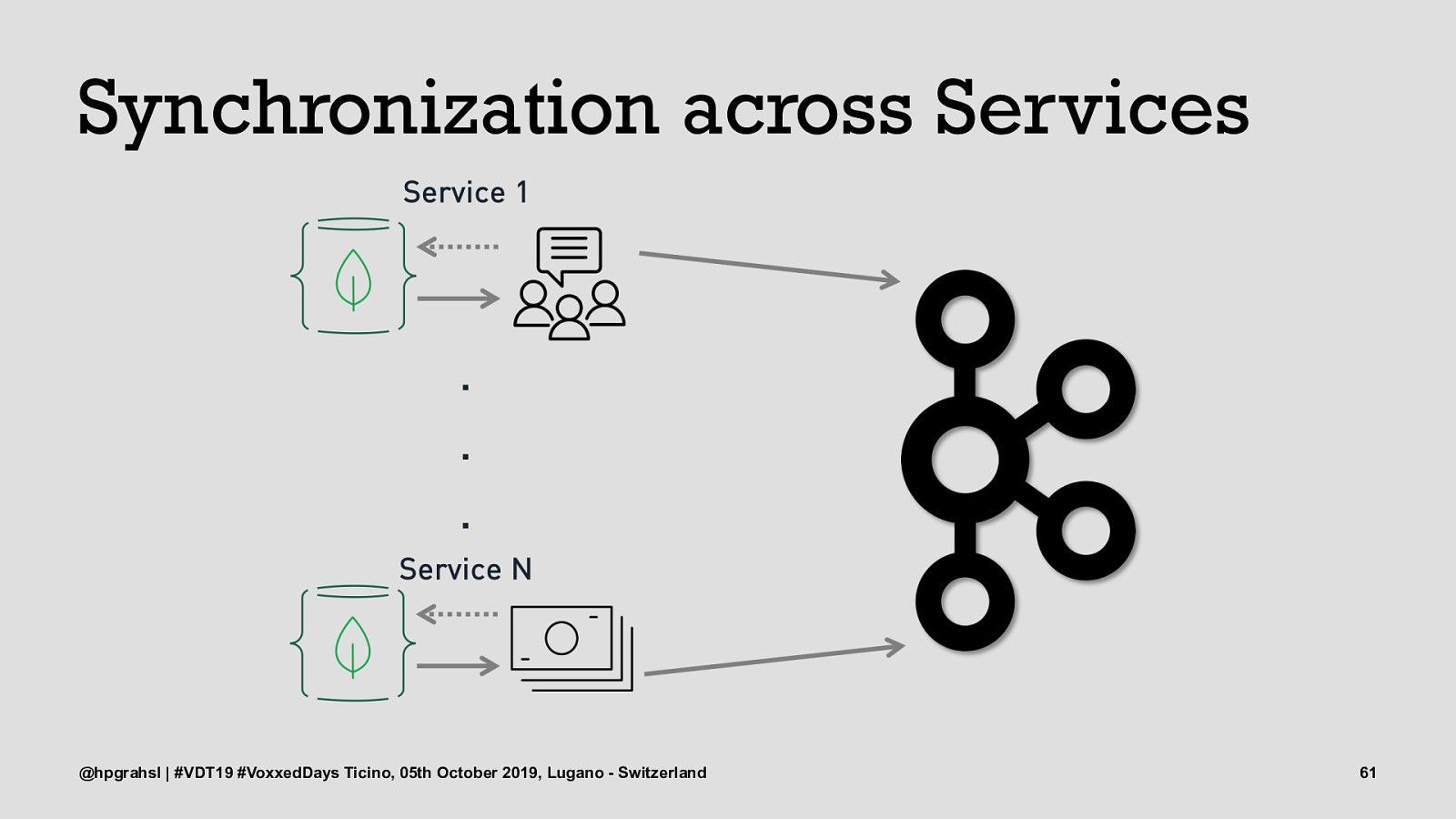
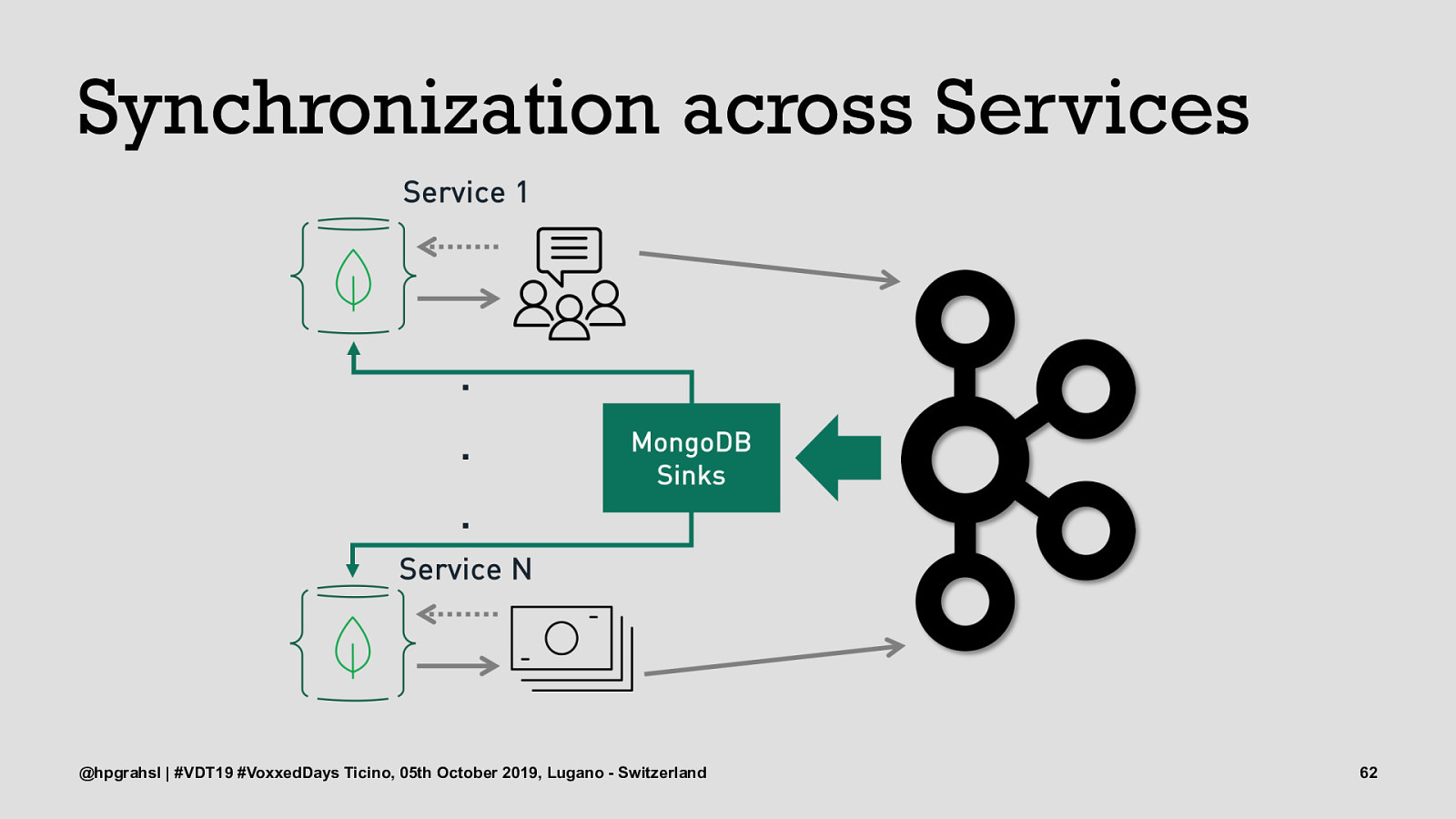
Synchronization across Services @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 58
Synchronization across Services @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 59
Synchronization across Services @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 60
Synchronization across Services @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 61
Synchronization across Services @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 62
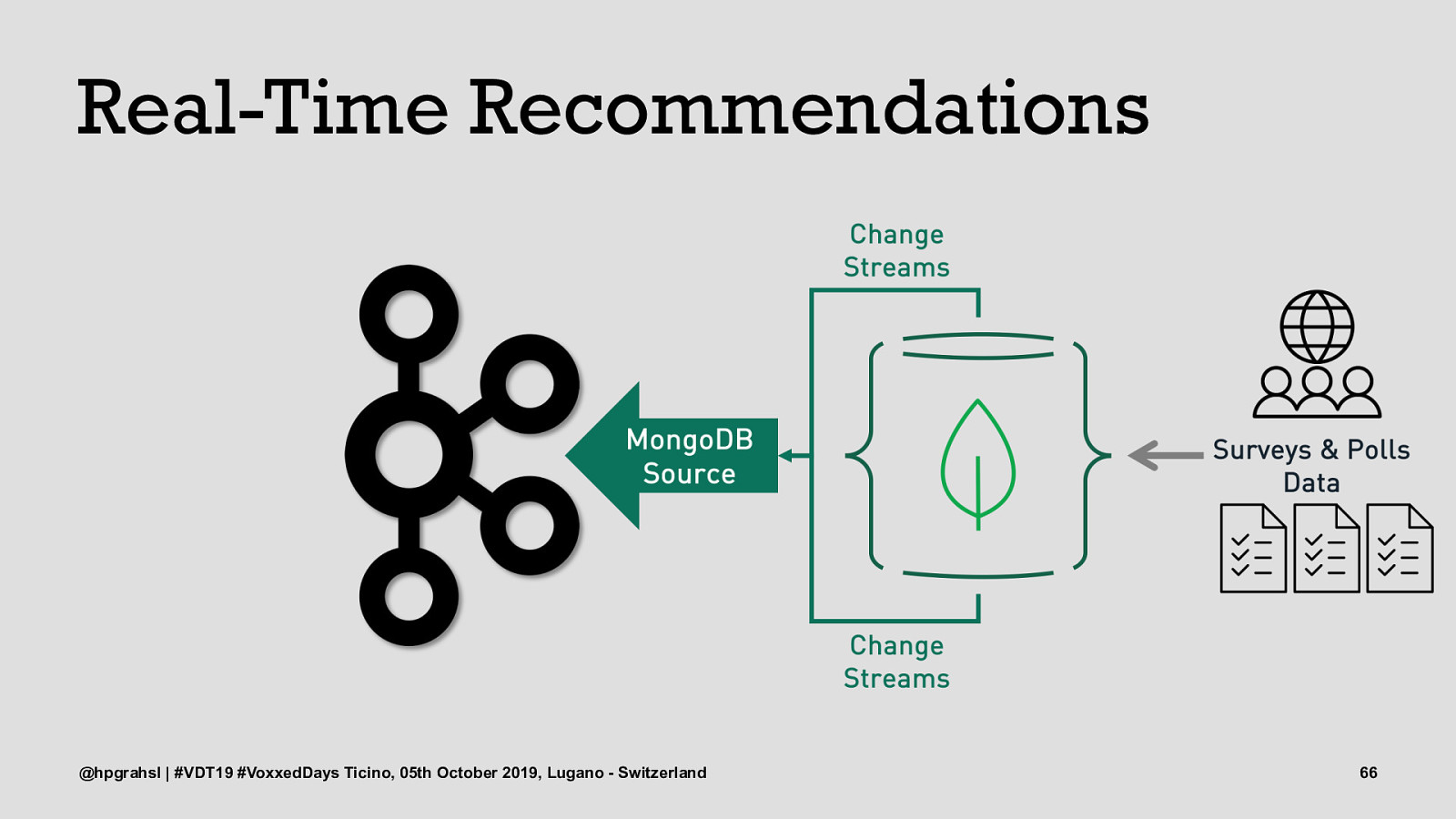
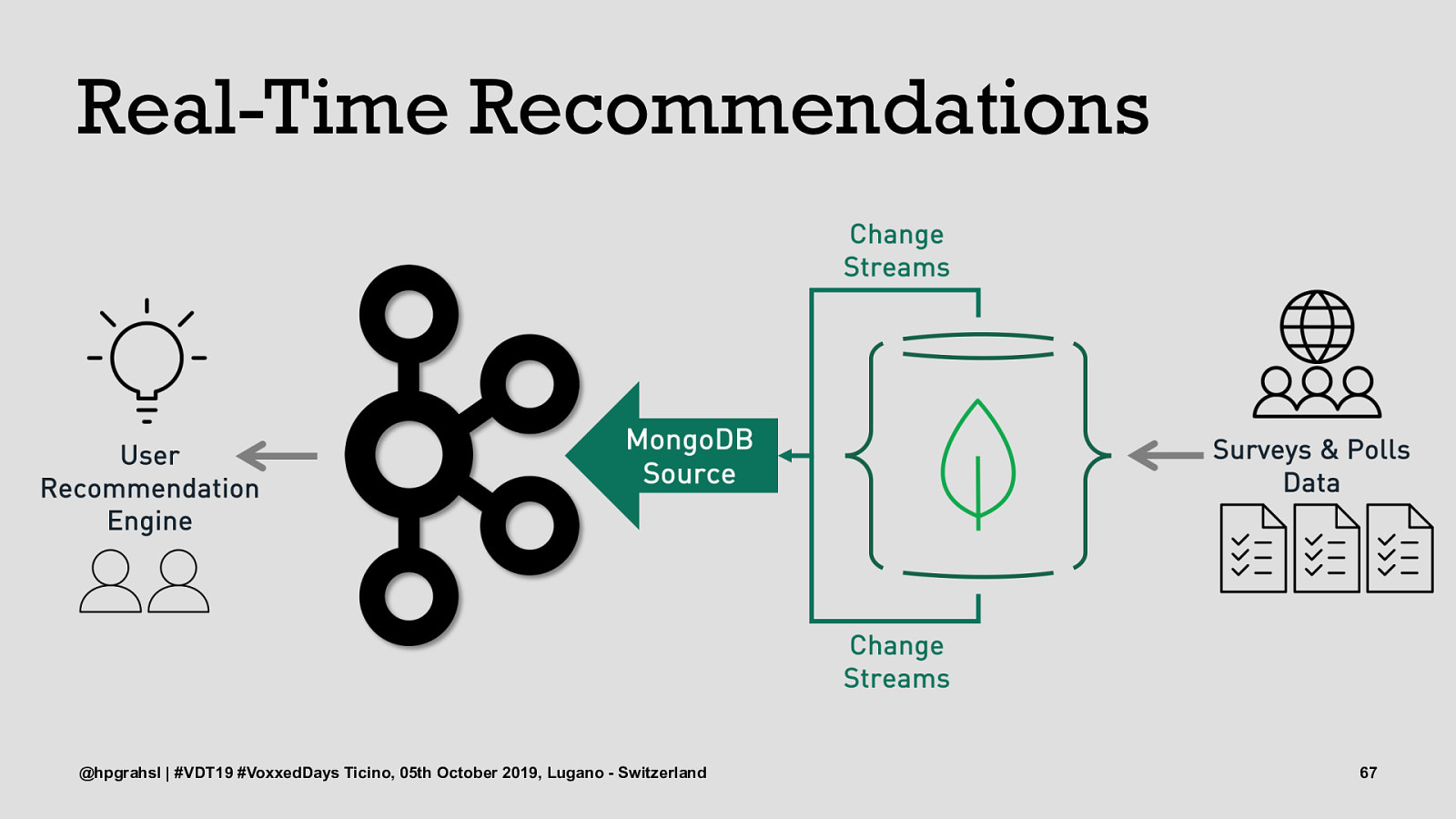
Real-Time Recommendations @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 63
Real-Time Recommendations @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 64
Real-Time Recommendations @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 65
Real-Time Recommendations @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 66
Real-Time Recommendations @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 67
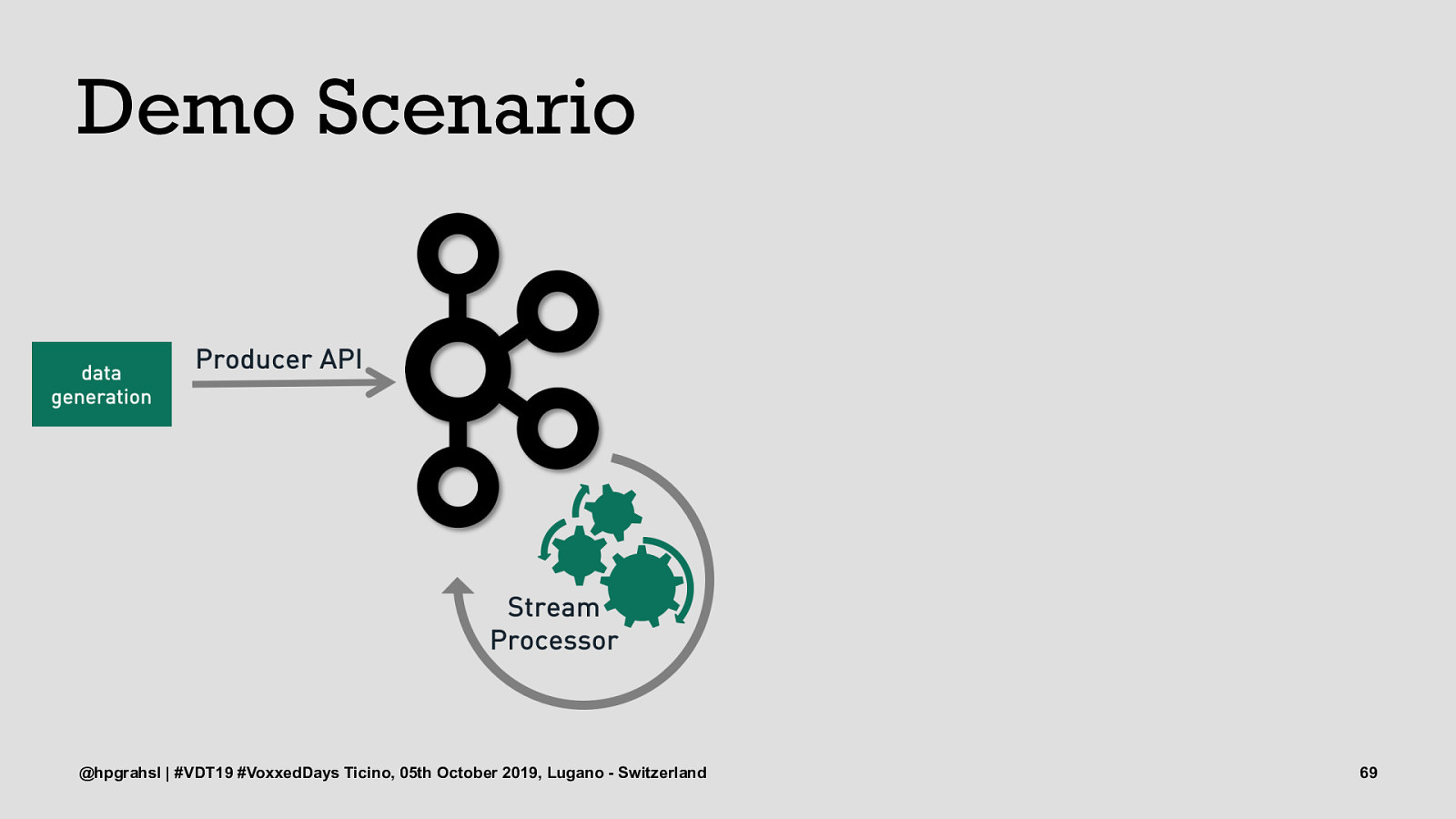
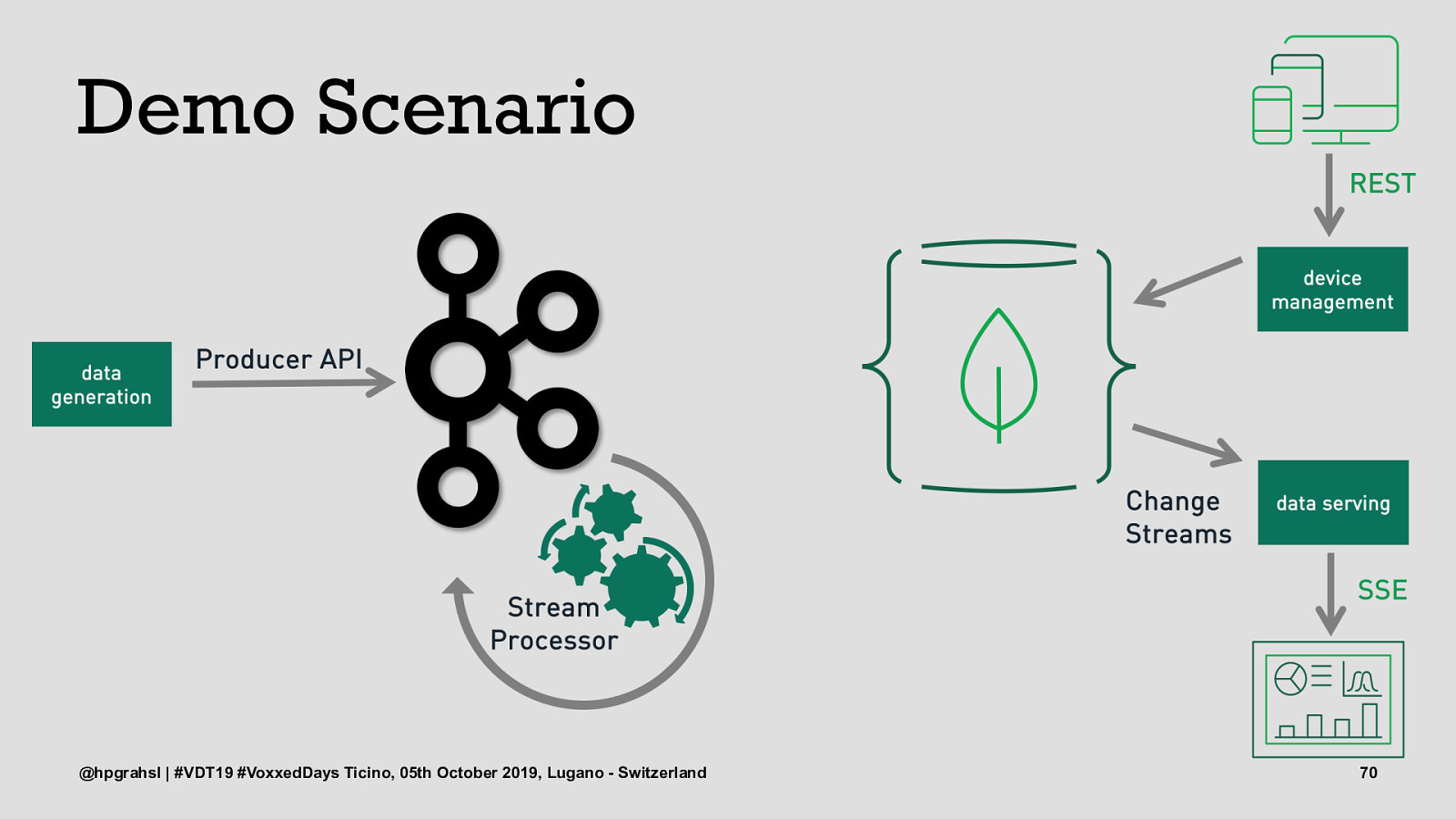
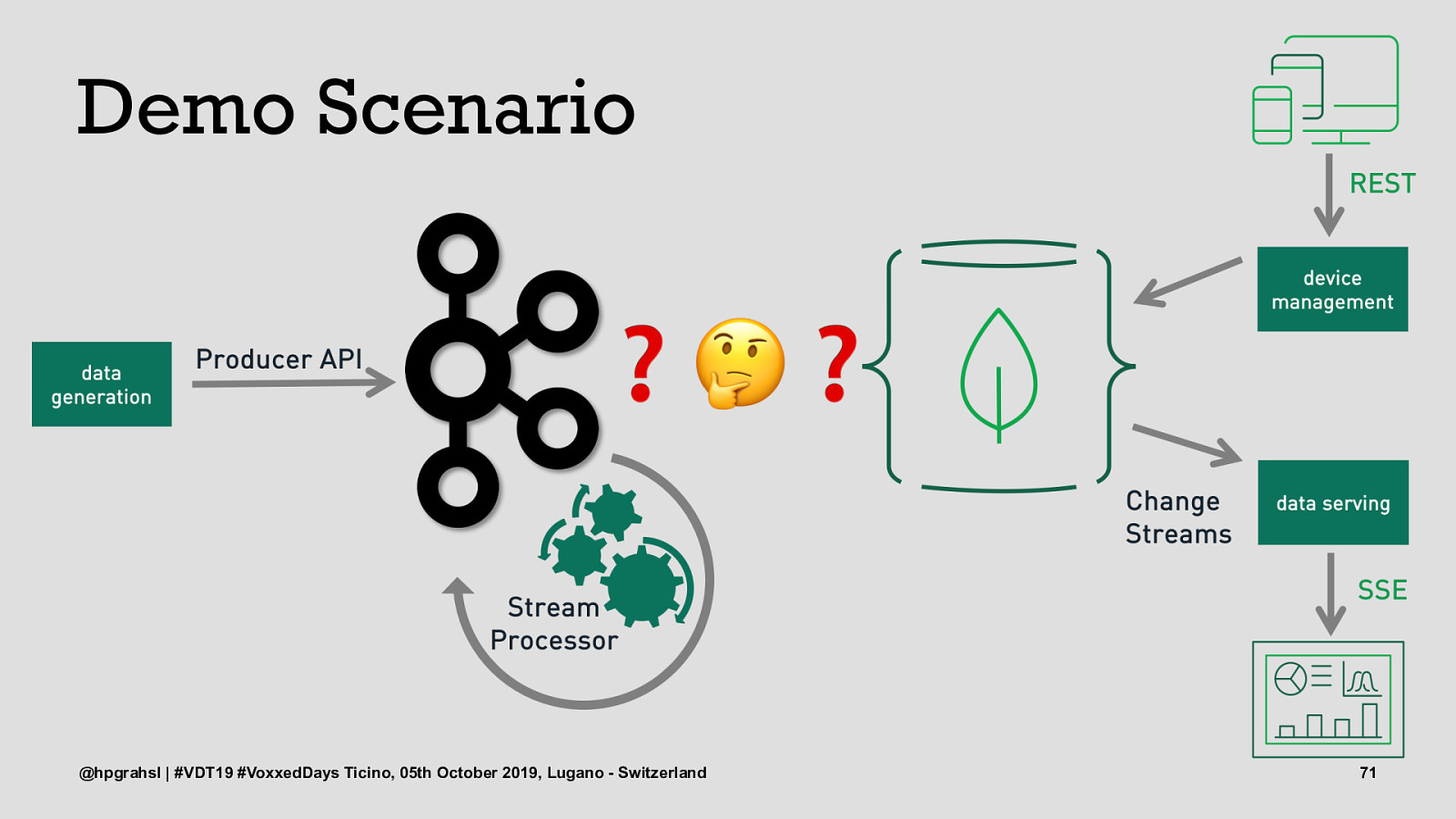
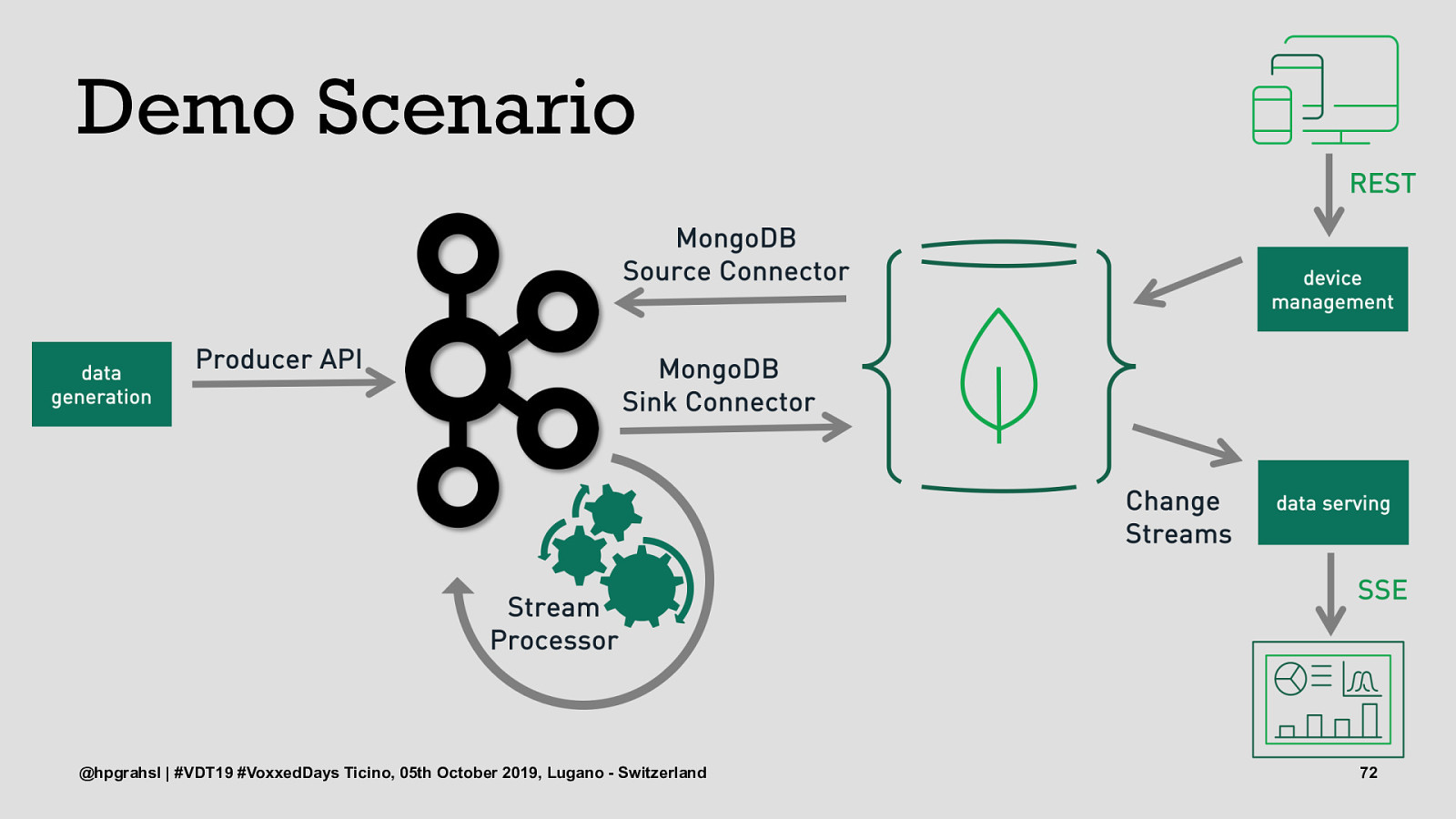
Demo Scenario @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 68
Demo Scenario @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 69
Demo Scenario @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 70
Demo Scenario @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 71
Demo Scenario @hpgrahsl | #VDT19 #VoxxedDays Ticino, 05th October 2019, Lugano - Switzerland 72

Life doesn’t happen in batch mode which is why application engineers and data architects need to closely cooperate to get the best out of streaming platforms like Apache Kafka and operational NoSQL data stores such as MongoDB. This session explores ways and means to integrate both worlds in a streaming fashion.
Without doubt stream processing is a big deal these days and oftentimes we find Apache Kafka as the central nervous system of company-wide data architectures. However, many real-world uses cases simply need an operational data store which is flexible, robust and scalable enough to live up to diverse application-related requirements and challenges. This session discusses different options in order to build solid data integration pipelines between MongoDB and Apache Kafka. The focus lies on configuration-based data in motion scenarios leveraging the Kafka Connect framework in order to lay out streaming ETL pipeline examples without writing a single line of code.


































 for free. You
can too.
for free. You
can too.