
A presentation at MongoDB World 2019 in in New York, NY, USA by Hans-Peter Grahsl

Streaming ETL on the Shoulders of Giants Scott L’Hommedieu, MongoDB llamadew Hans-Peter Grahsl, NETCONOMY hpgrahsl
Streaming ETL on the Shoulders of Giants Why ETL is important How we can “ETL better” Let’s see (some use cases) + a DEMO!
Speed & Agility A Top 5 Tech Risk* For businesses to stay relevant they must deliver value at a breakneck pace and be constantly seeking new sources of value. *google ”top tech risks”
Managing, Processing and Analyzing Data We use Data To unlock insights And drive value
But, historic ETL is painful An antipattern for Speed and Agility ETL = Batch( Error Prone , Brittle, Slow )
Solving the pain of ETL through Streaming Data Speed and Agility ETL = DataStream ( Resilient, Loosely Coupled, Realtime)
Streaming ETL on the Shoulders of Giants Why ETL is important How we can “ETL” better Let’s see (some use cases) + a DEMO!
Architecture of a Modern Data Platform
Architecture of a Modern Data Platform Streaming Data Platform
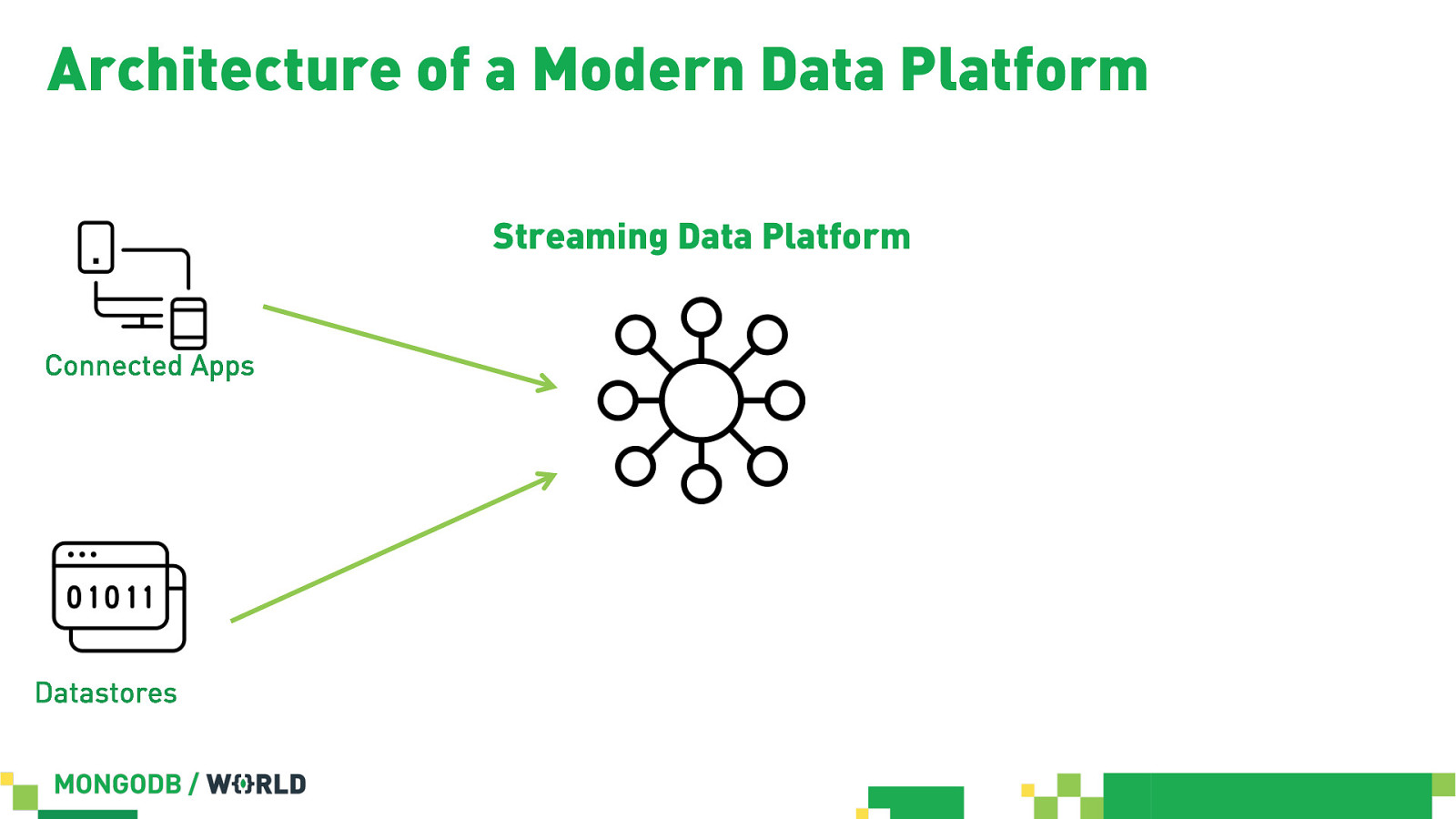
Architecture of a Modern Data Platform Streaming Data Platform Connected Apps Datastores
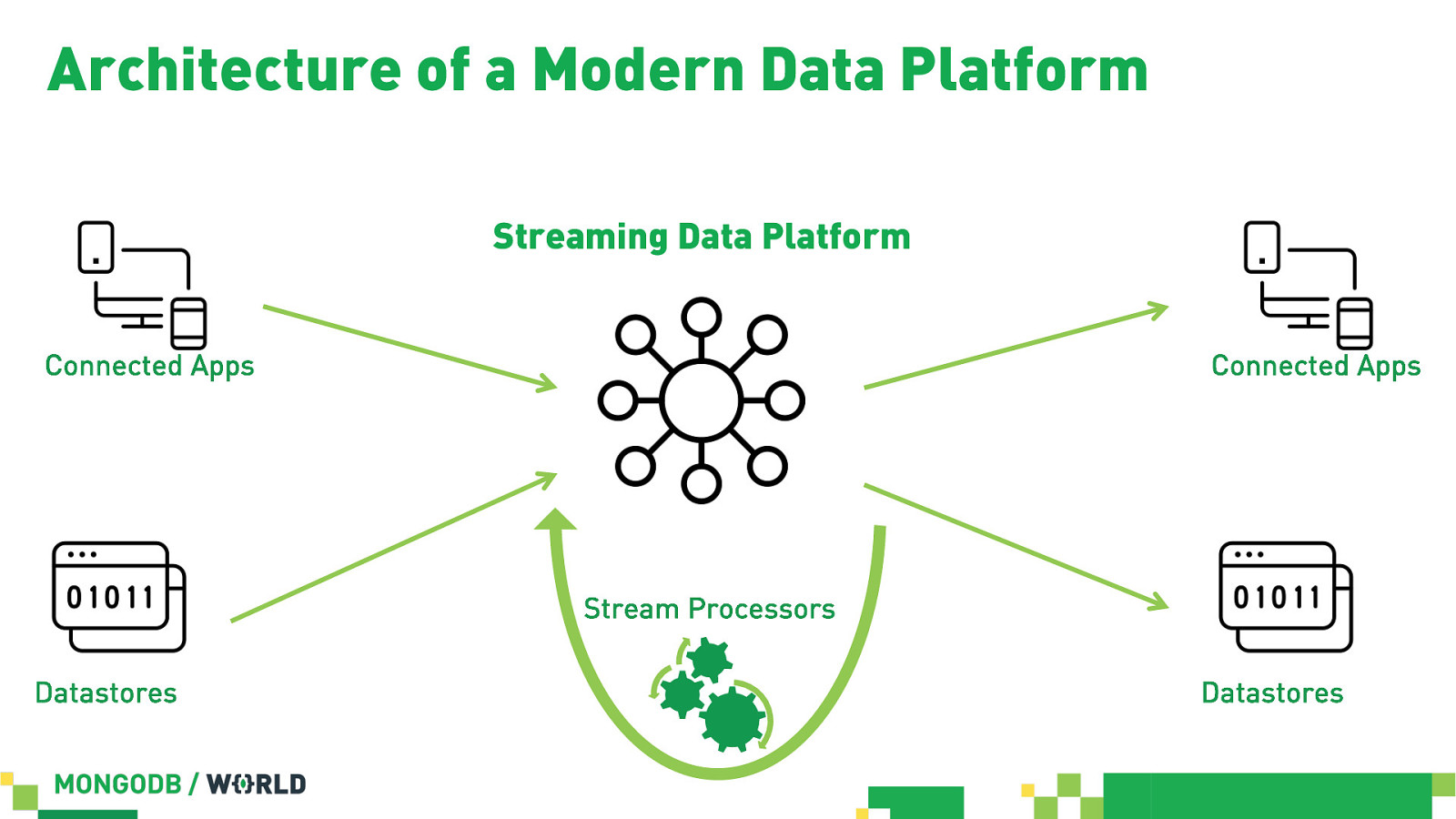
Architecture of a Modern Data Platform Streaming Data Platform Connected Apps Connected Apps Stream Processors Datastores Datastores
On the shoulders of Giants MongoDB Kafka
Modern Data Platform
Modern Data Platform Doc Model Run Anywhere Distributed and Scalable Resilient and Performant
Apache Kafka 101
Streaming Platform
Streaming Platform • distributed • horizontally scalable • highly fault-tolerant
What is Streaming? “a type of data processing that is designed with infinite data sets in mind” –Tyler Akidau
“…everything that happens in a company – every customer interaction, every API request, every database change – can be represented as real-time stream that anything else can tap into, process or react to.”
“…Kafka and the whole category of stream processing represents a fundamental paradigm shift in how the digital part of a company is built, how data is used, and how applications are built. This is actually a pretty rare thing…” – Jay Kreps
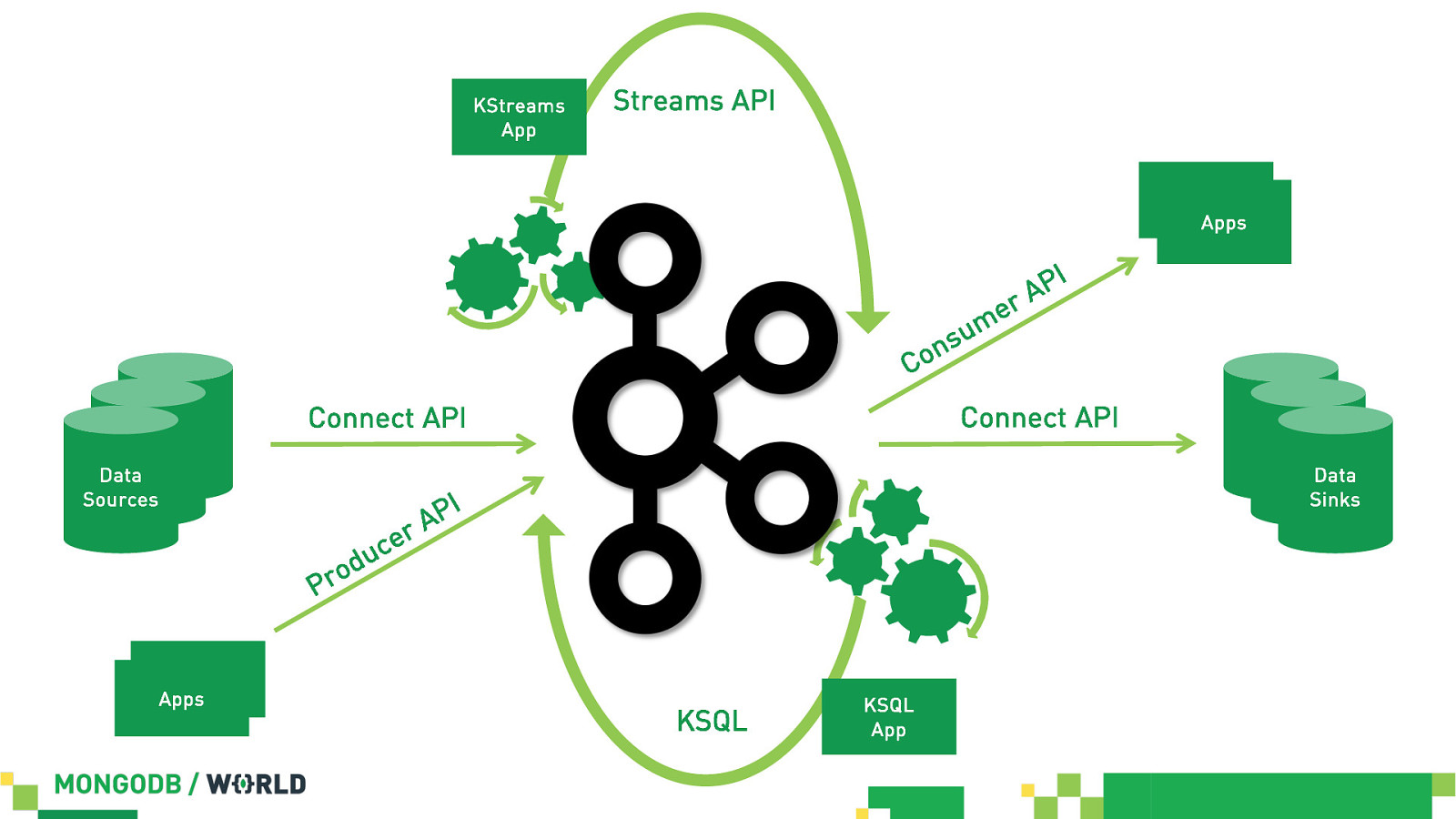
KStreams App Streams API App Apps n Co Pr App Apps o c du e P rA I Connect API Connect API Data Sources s e m u P rA Data Sinks I KSQL KSQL App
Kafka APIs in a Nutshell… § Producer & Consumer API à publish-subscribe scenarios § Connect API à streaming data integration scenarios § Streams API & KSQL à code or SQL-based streaming scenarios
A bit more about Kafka Connect …
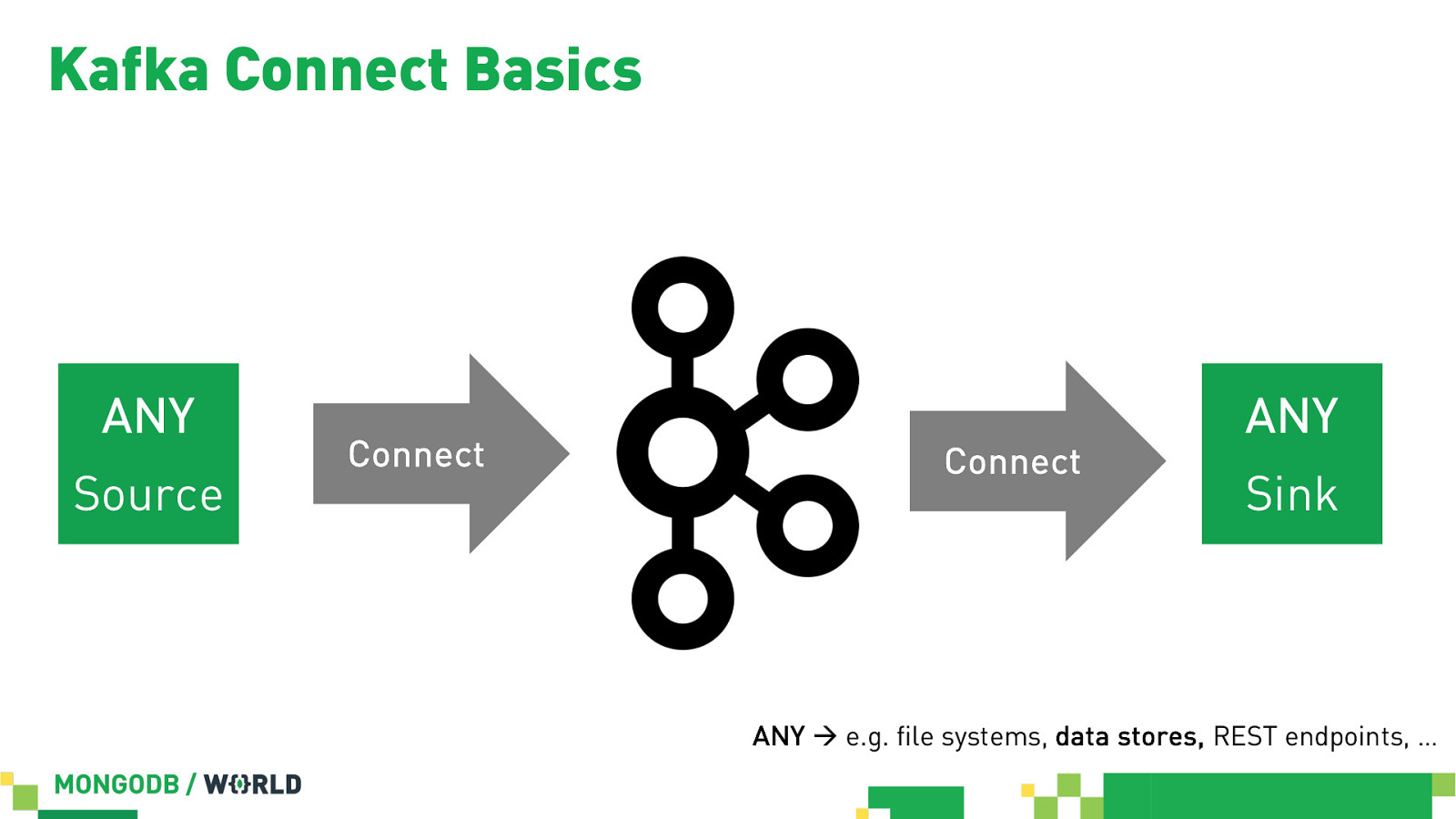
Kafka Connect Basics ANY Source Connect Connect ANY Sink ANY à e.g. file systems, data stores, REST endpoints, …
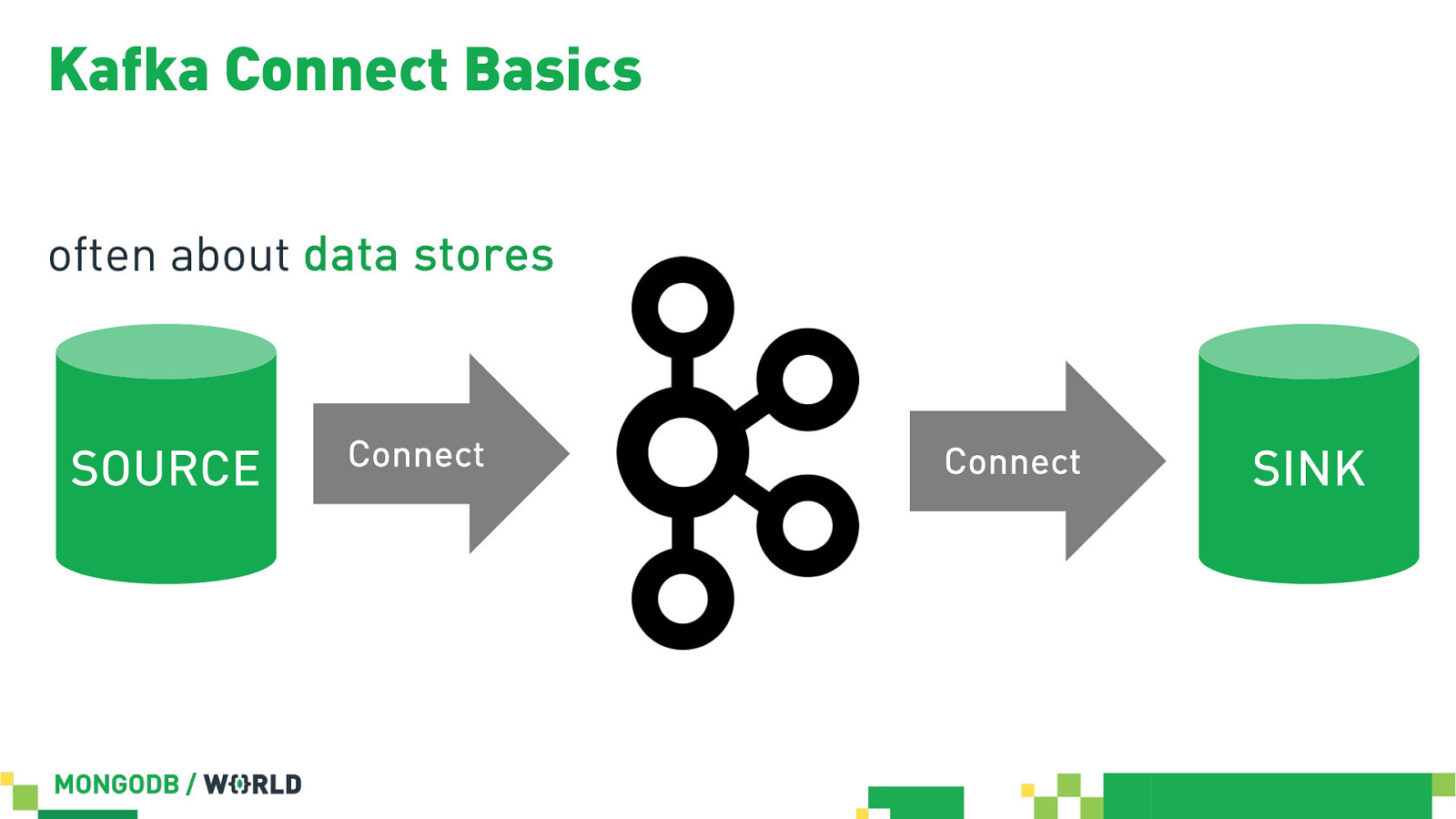
Kafka Connect Basics often about data stores SOURCE Connect Connect SINK
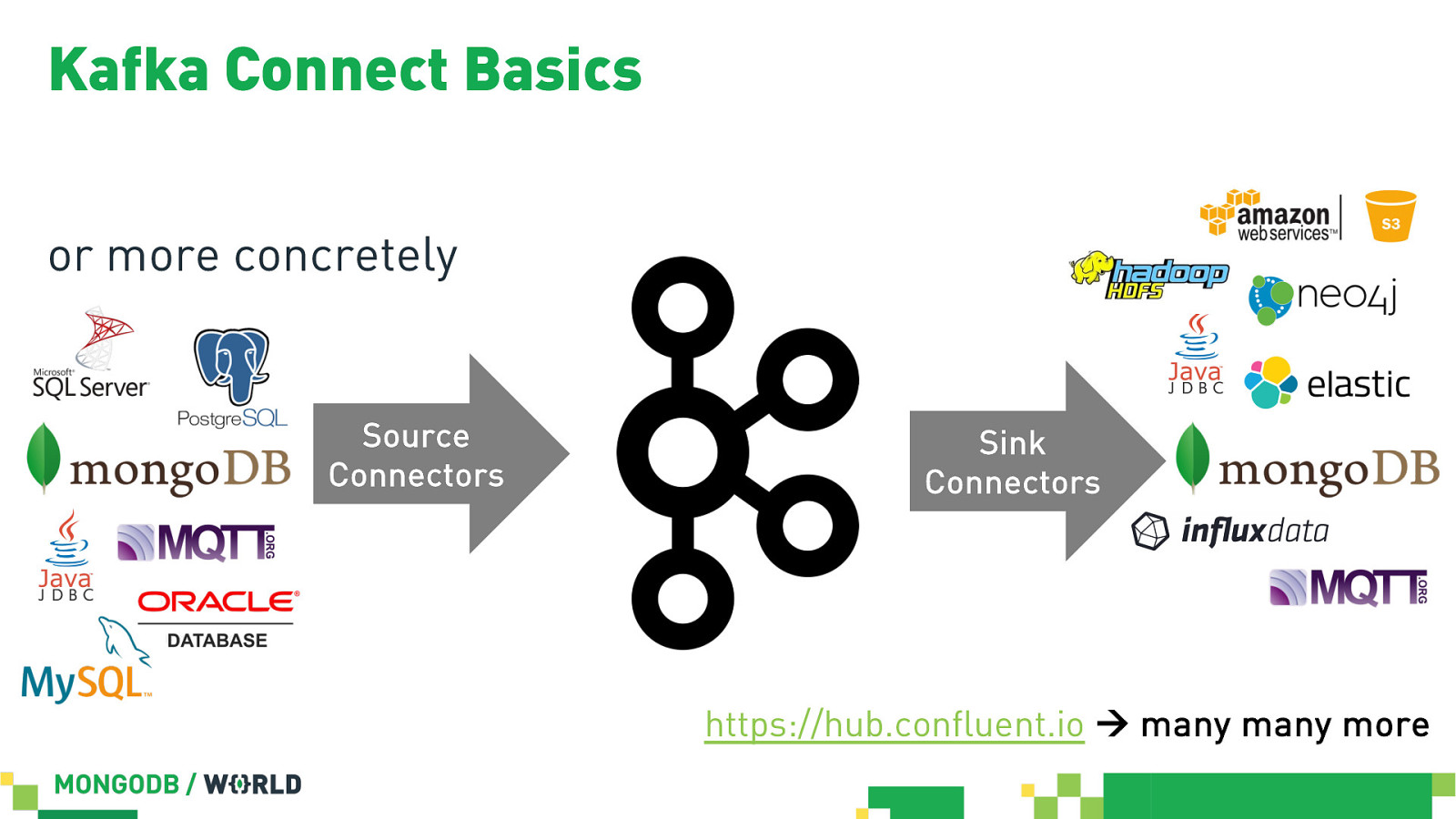
Kafka Connect Basics or more concretely Source Connectors Sink Connectors https://hub.confluent.io à many many more
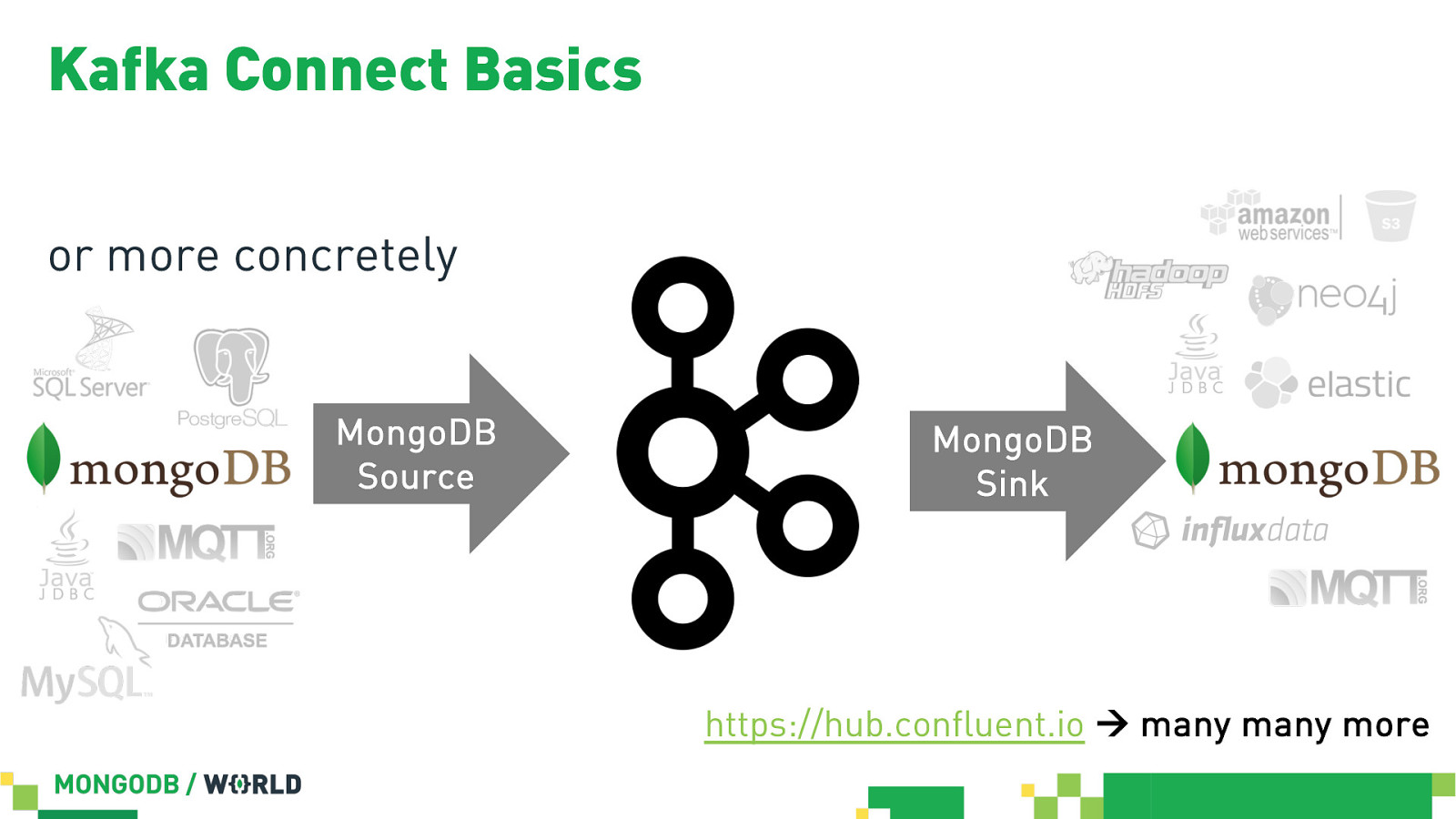
Kafka Connect Basics or more concretely MongoDB Source MongoDB Sink https://hub.confluent.io à many many more
How do connectors operate?
Kafka Source Connectors Source Connector S M T … S M T Converter Serialize 1…N Single Message Transforms for basic in-flight manipulations
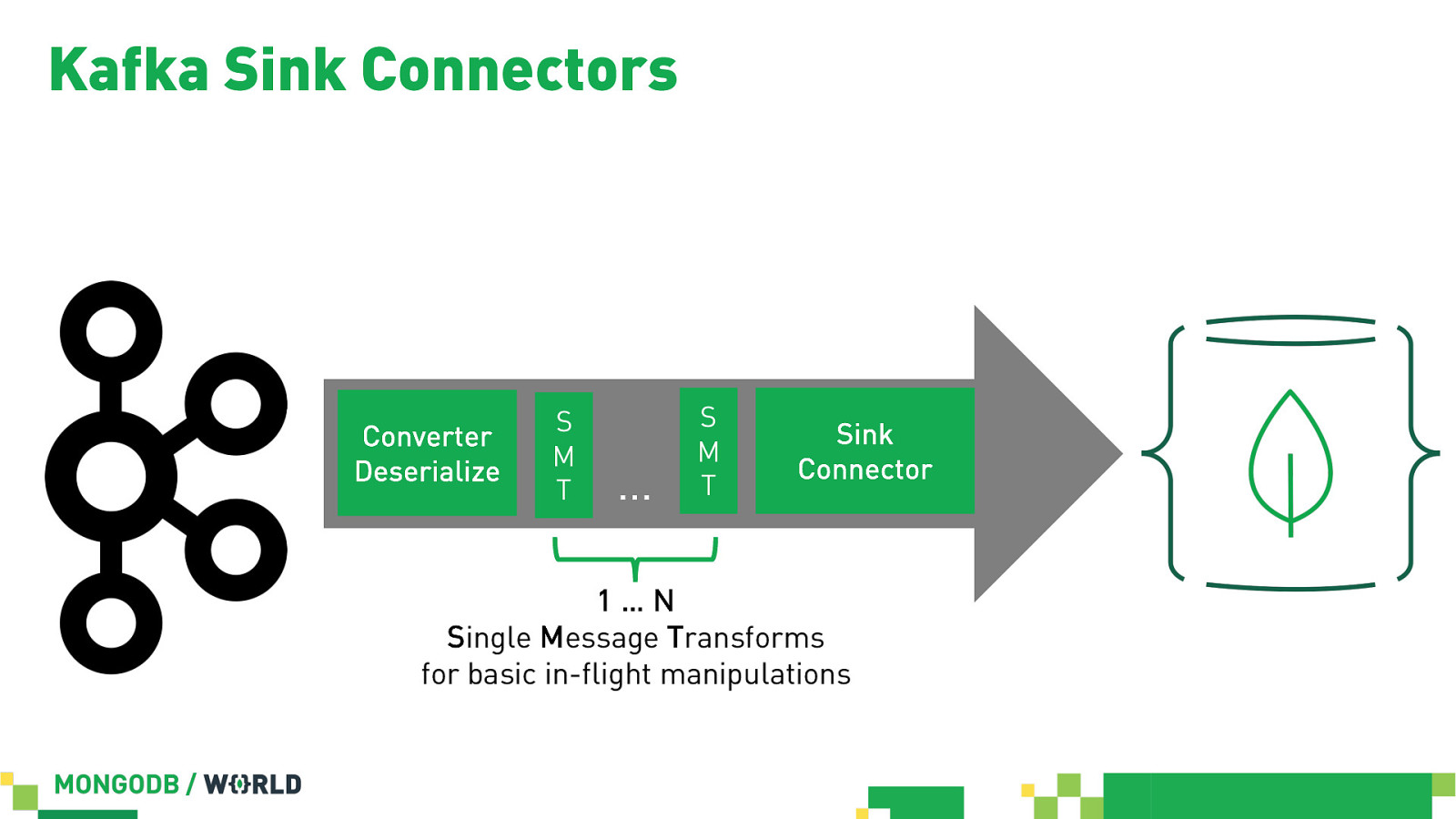
Kafka Sink Connectors Converter Deserialize S M T … S M T Sink Connector 1…N Single Message Transforms for basic in-flight manipulations
Announcing …
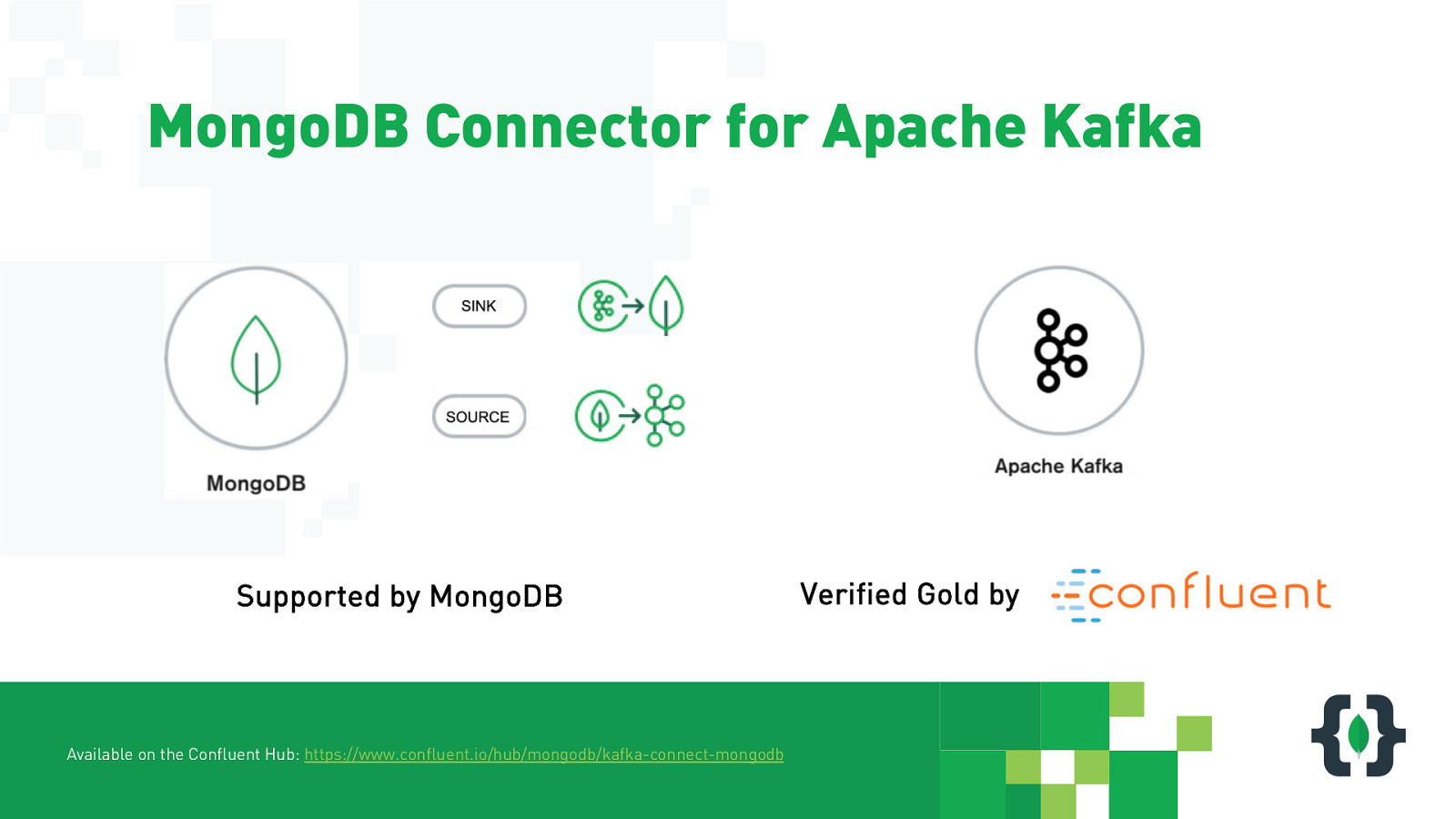
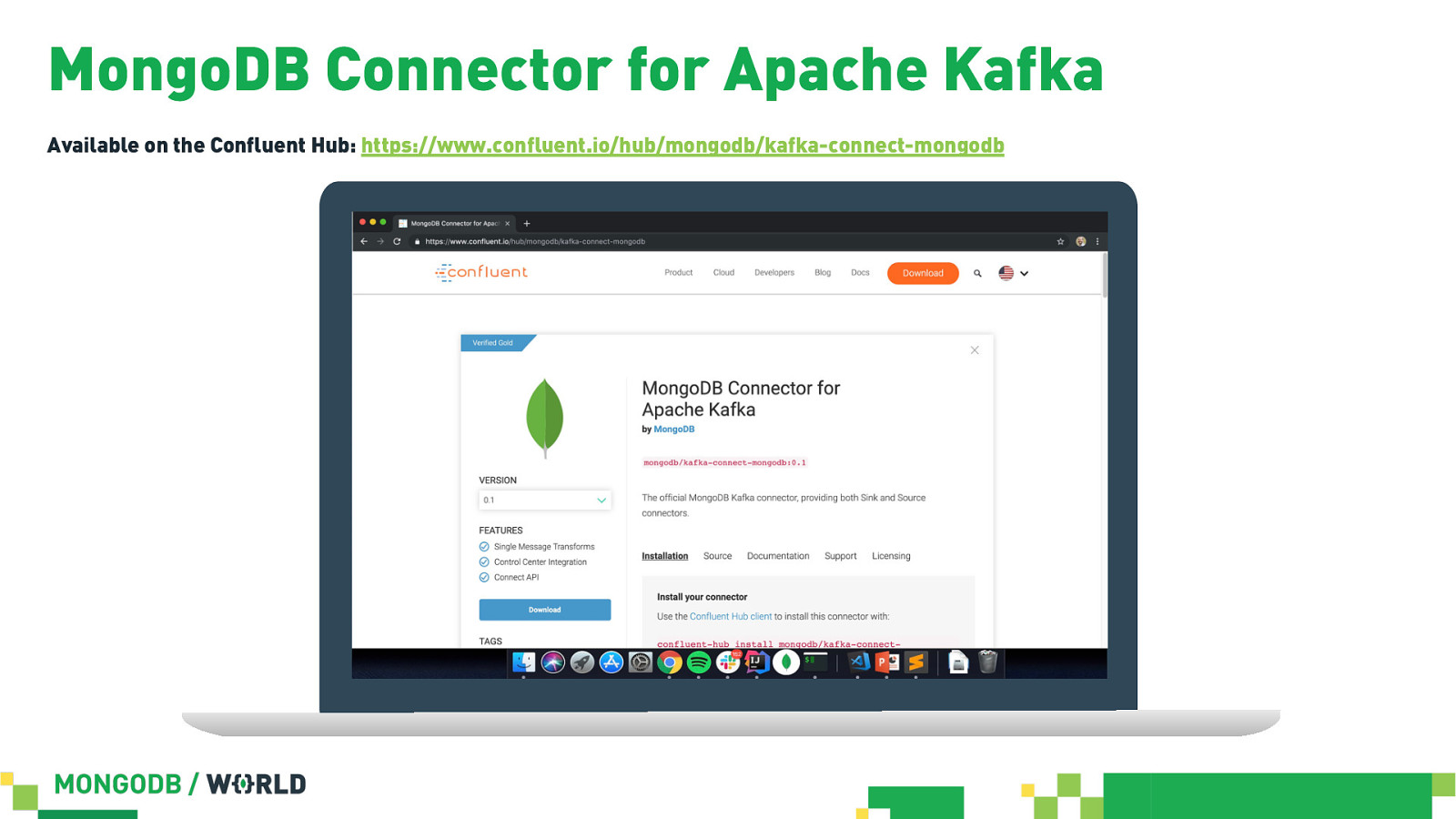
MongoDB Connector for Apache Kafka Supported by MongoDB Available on the Confluent Hub: https://www.confluent.io/hub/mongodb/kafka-connect-mongodb Verified Gold by
MongoDB Connector for Apache Kafka Available on the Confluent Hub: https://www.confluent.io/hub/mongodb/kafka-connect-mongodb
Streaming ETL on the Shoulders of Giants Why ETL is important How we can “ETL better” Let’s see (some use cases) + a DEMO!
Streaming ETL Use Cases
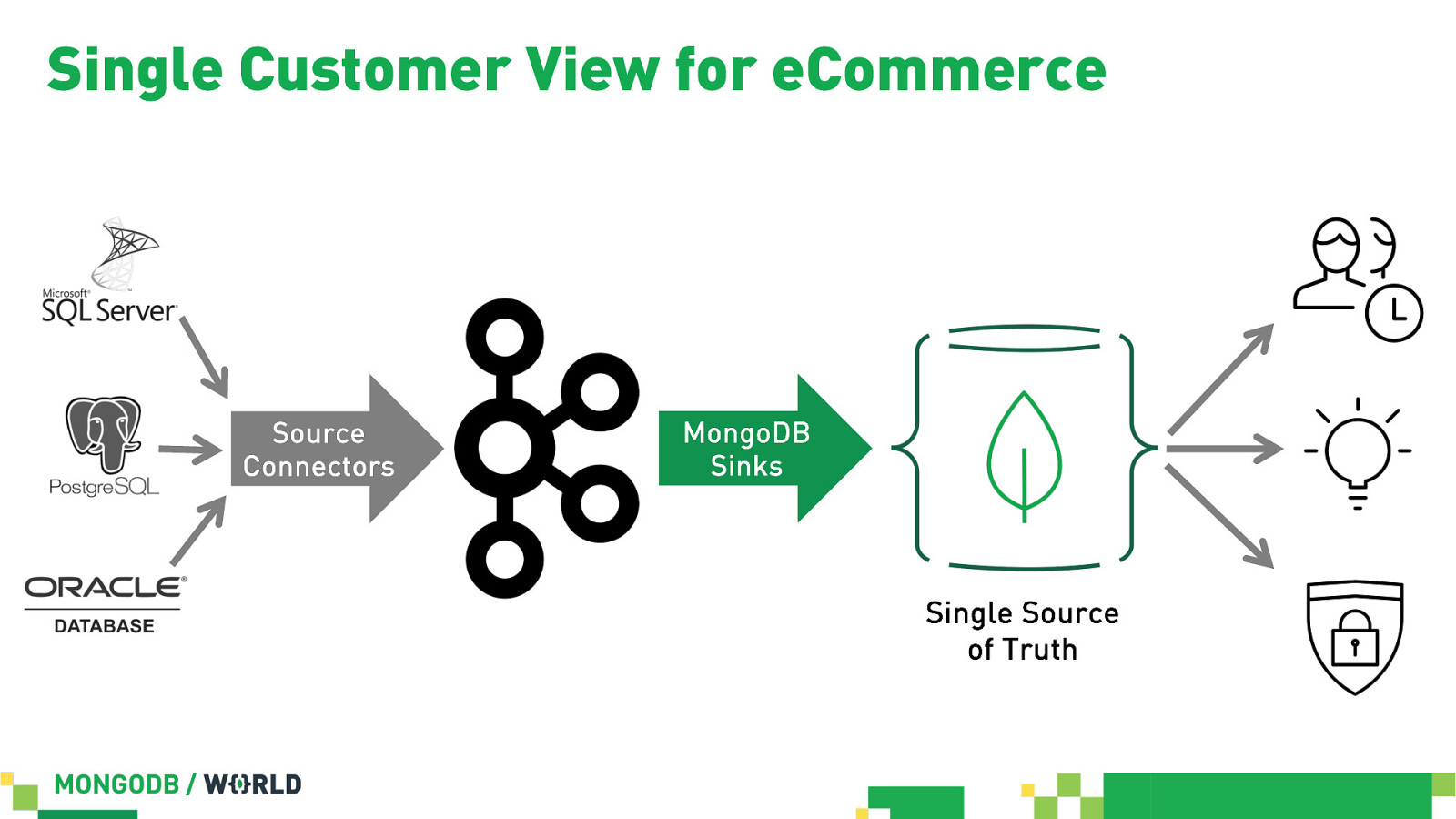
Single Customer View for eCommerce Source Connectors MongoDB Sinks Single Source of Truth
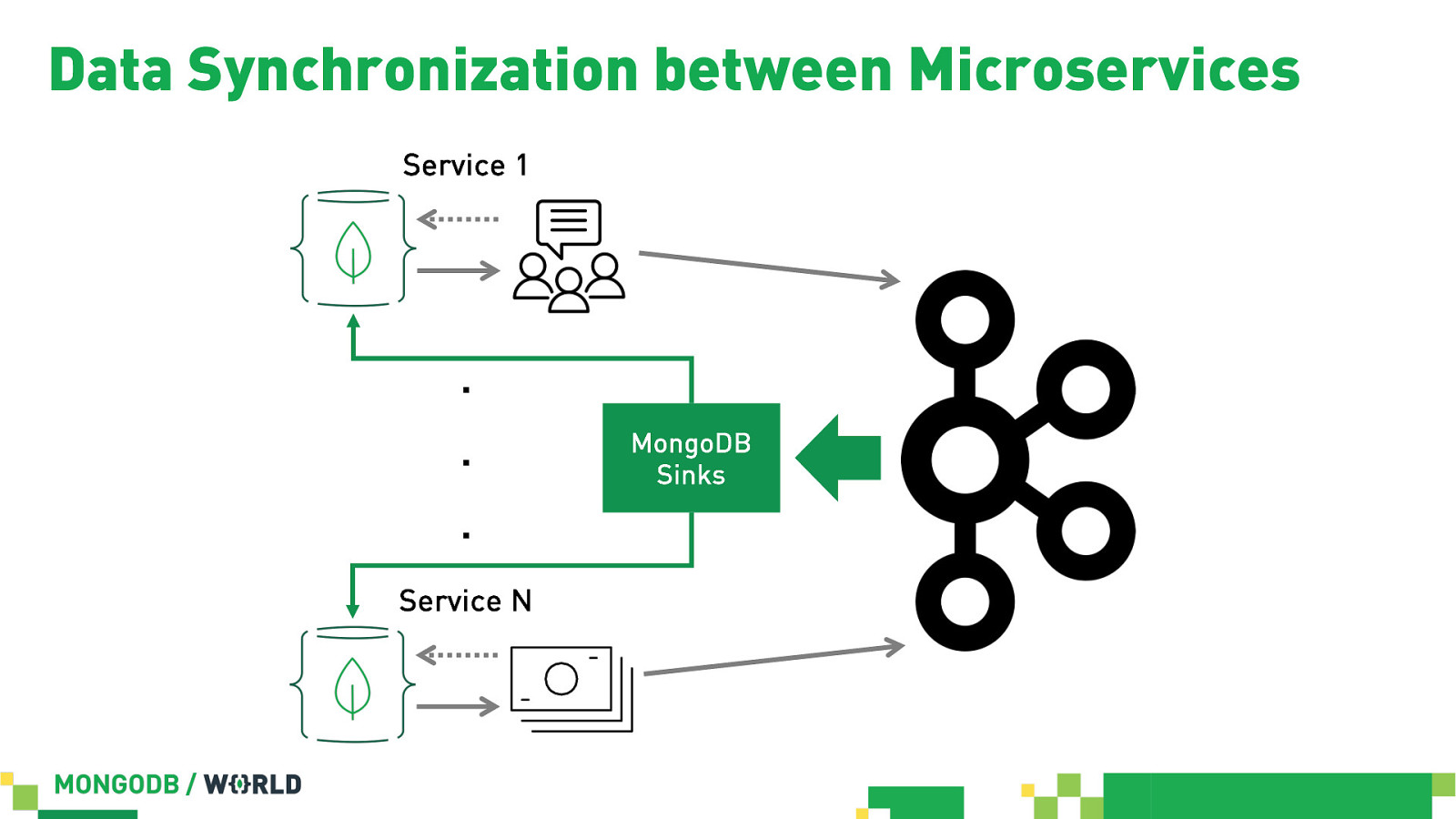
Data Synchronization between Microservices Service 1 … Service N MongoDB Sinks
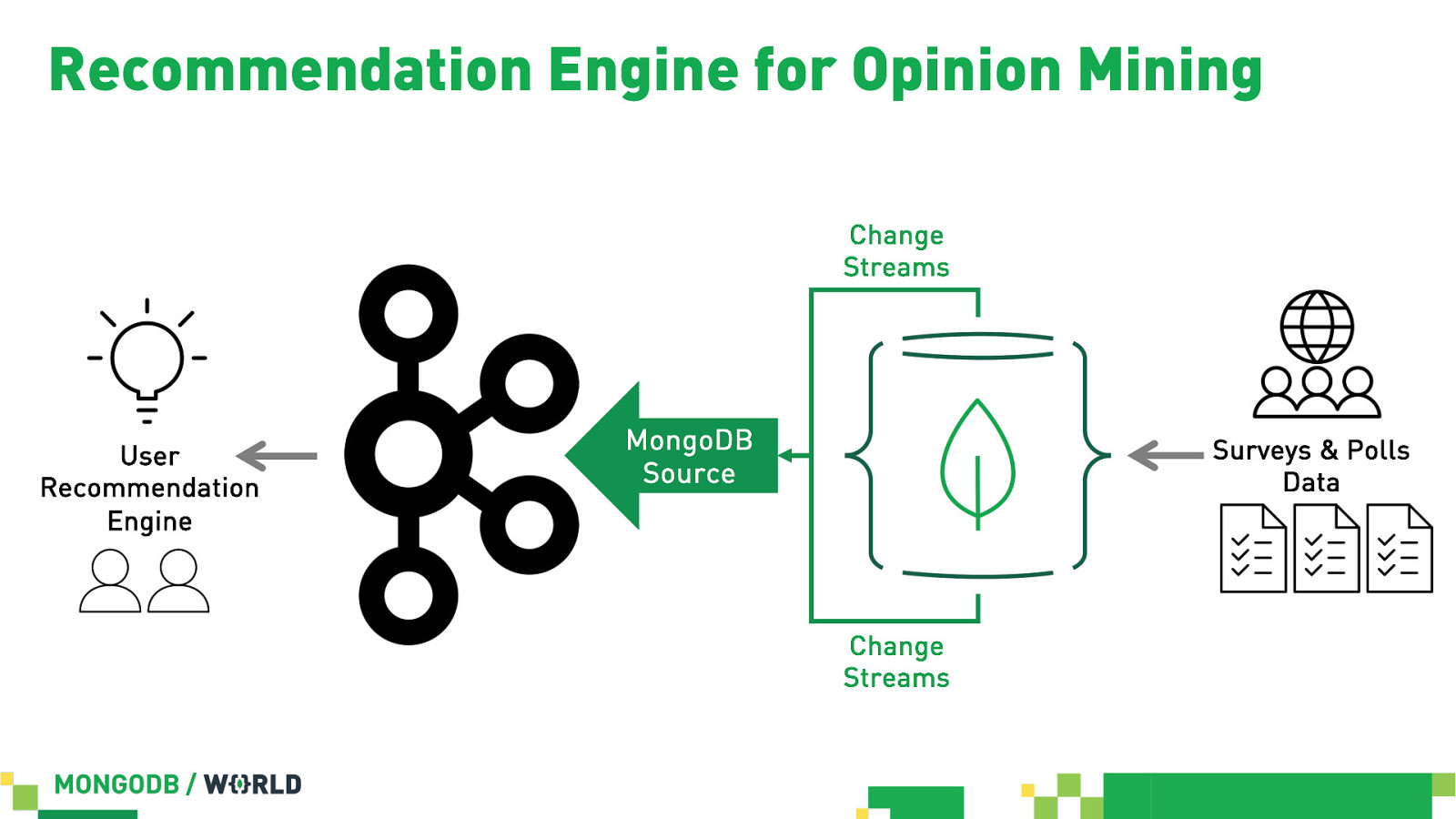
Recommendation Engine for Opinion Mining Change Streams User Recommendation Engine MongoDB Source Surveys & Polls Data Change Streams
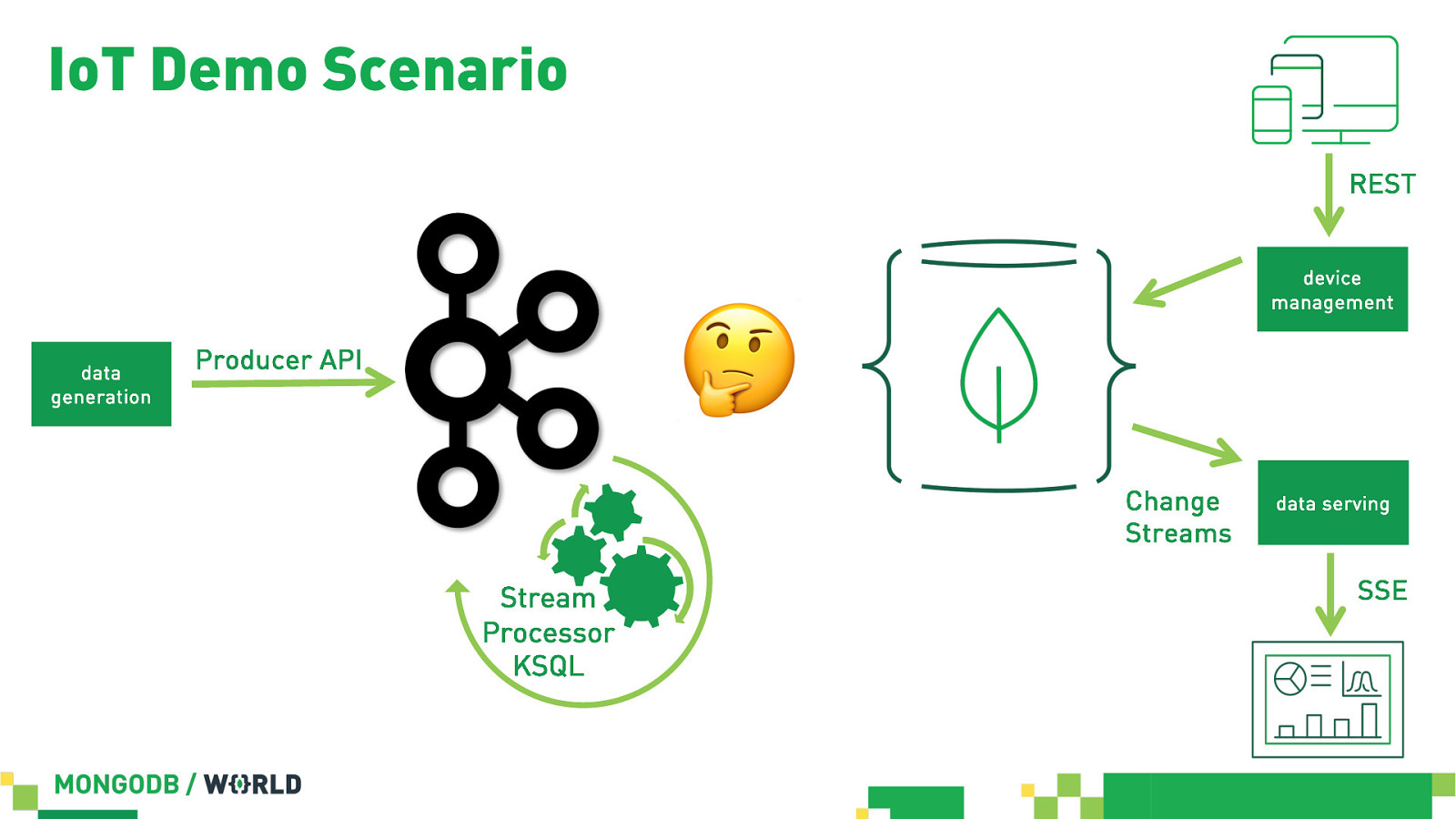
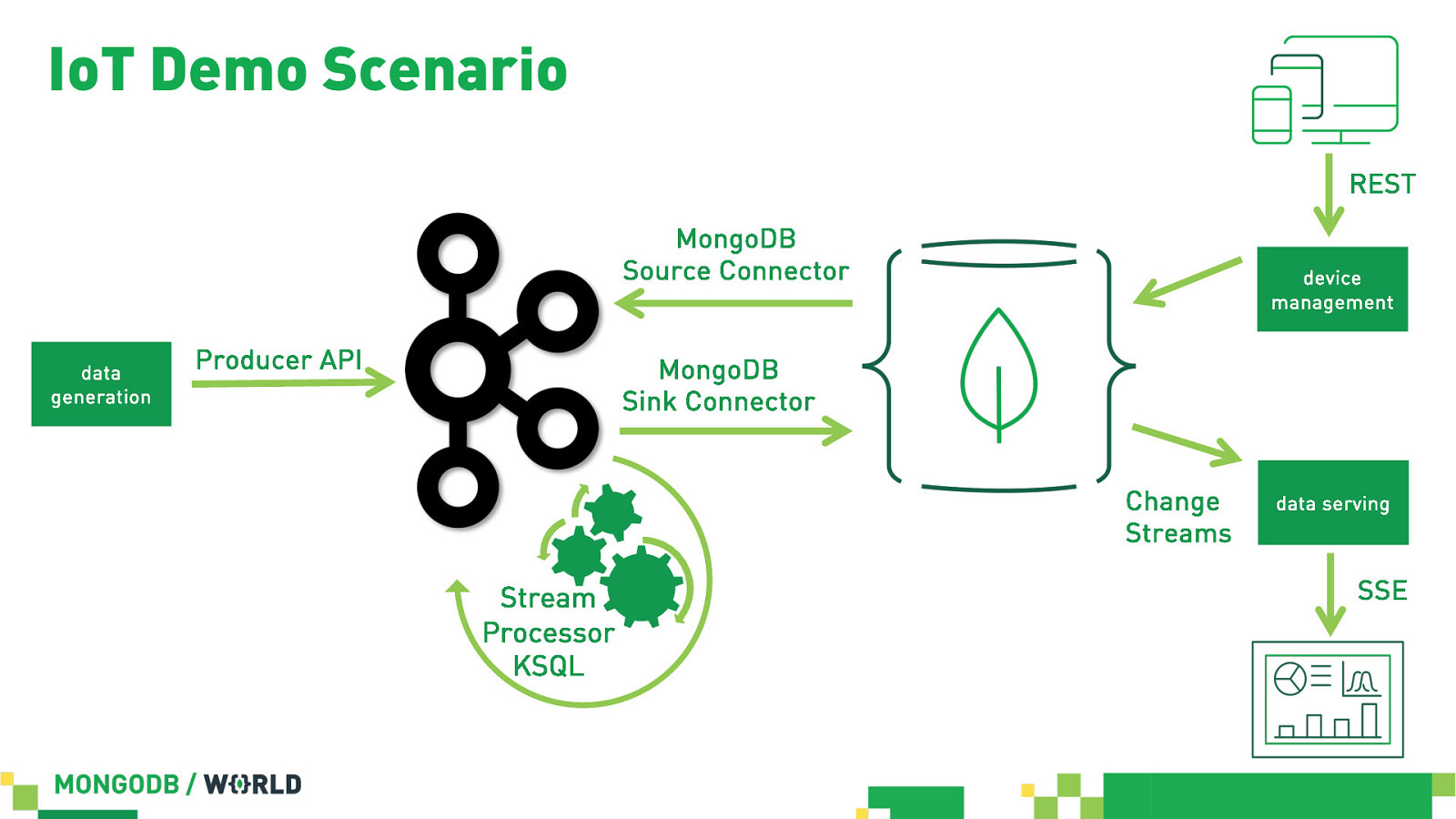
IoT Demo Scenario in Action
IoT Demo Scenario REST data generation device management ! Producer API Change Streams Stream Processor KSQL data serving SSE
IoT Demo Scenario REST MongoDB Source Connector data generation Producer API device management MongoDB Sink Connector Change Streams Stream Processor KSQL data serving SSE
That’s all folks! THANK YOU

Without doubt stream processing is a big deal these days and oftentimes we find Apache Kafka as the central nervous system of company-wide data architectures. However, many real-world uses cases simply need an operational data store which is flexible, robust and scalable enough to live up to diverse application-related requirements and challenges. This session discusses different options in order to build solid data integration pipelines between MongoDB and Apache Kafka. The focus lies on configuration-based data in motion scenarios leveraging the Kafka Connect framework in order to lay out streaming ETL pipeline examples without writing a single line of code.
Here’s what was said about this presentation on social media.
























 for free. You
can too.
for free. You
can too.