A presentation at Conf42: Golang 2021 by Lorna Jane Mitchell

Go Big With Apache Kafka Lorna Mitchell, Aiven
Apache Kafka “Apache Kafka is an open-source distributed event streaming platform” - https://kafka.apache.org • Designed for data streaming • Real-time data for finance and industry • Very scalable to handle large datasets @lornajane
Modern, scalable, and fast …. remind you of anything? @lornajane
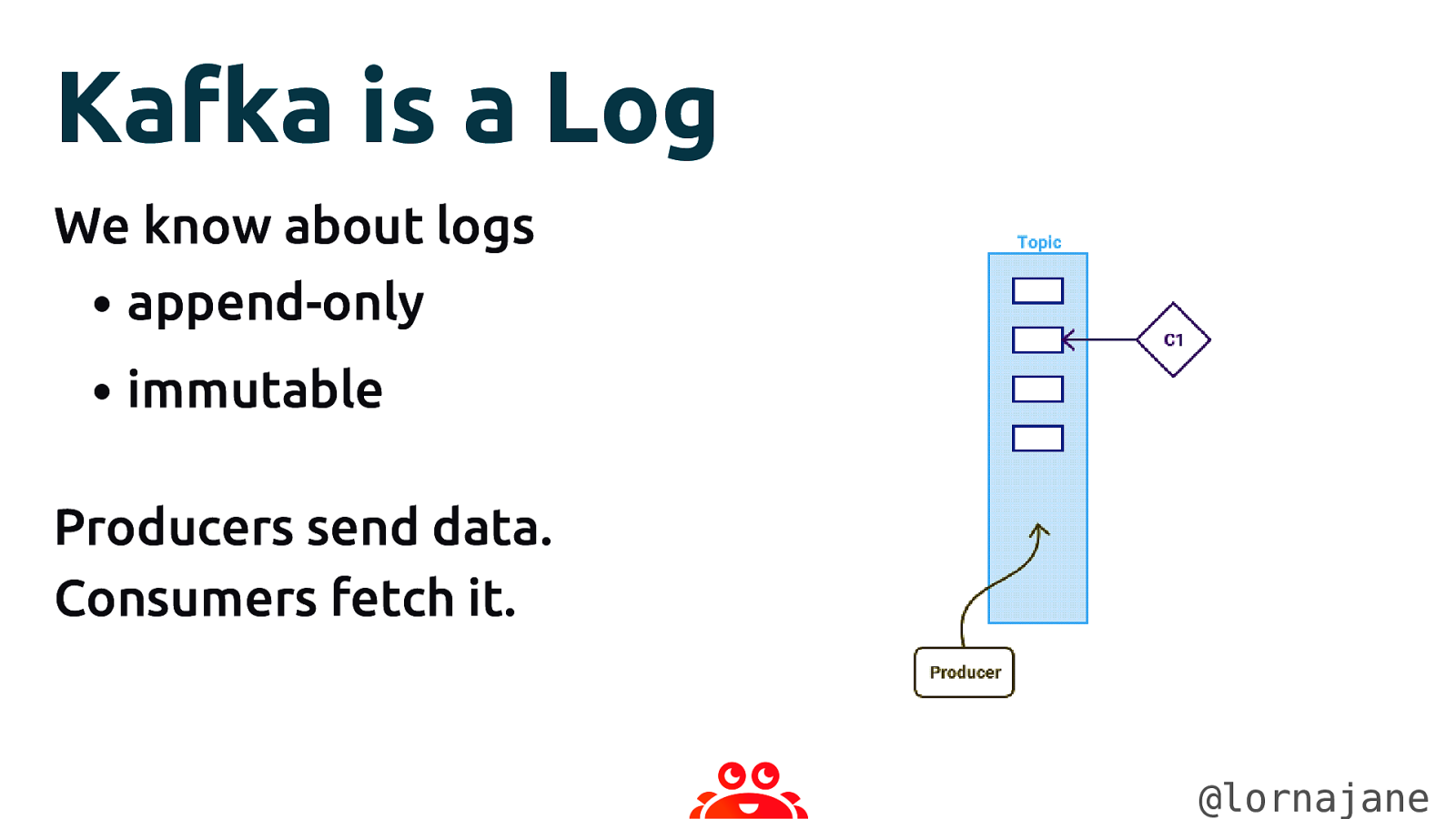
Kafka is a Log We know about logs • append-only • immutable Producers send data. Consumers fetch it. @lornajane
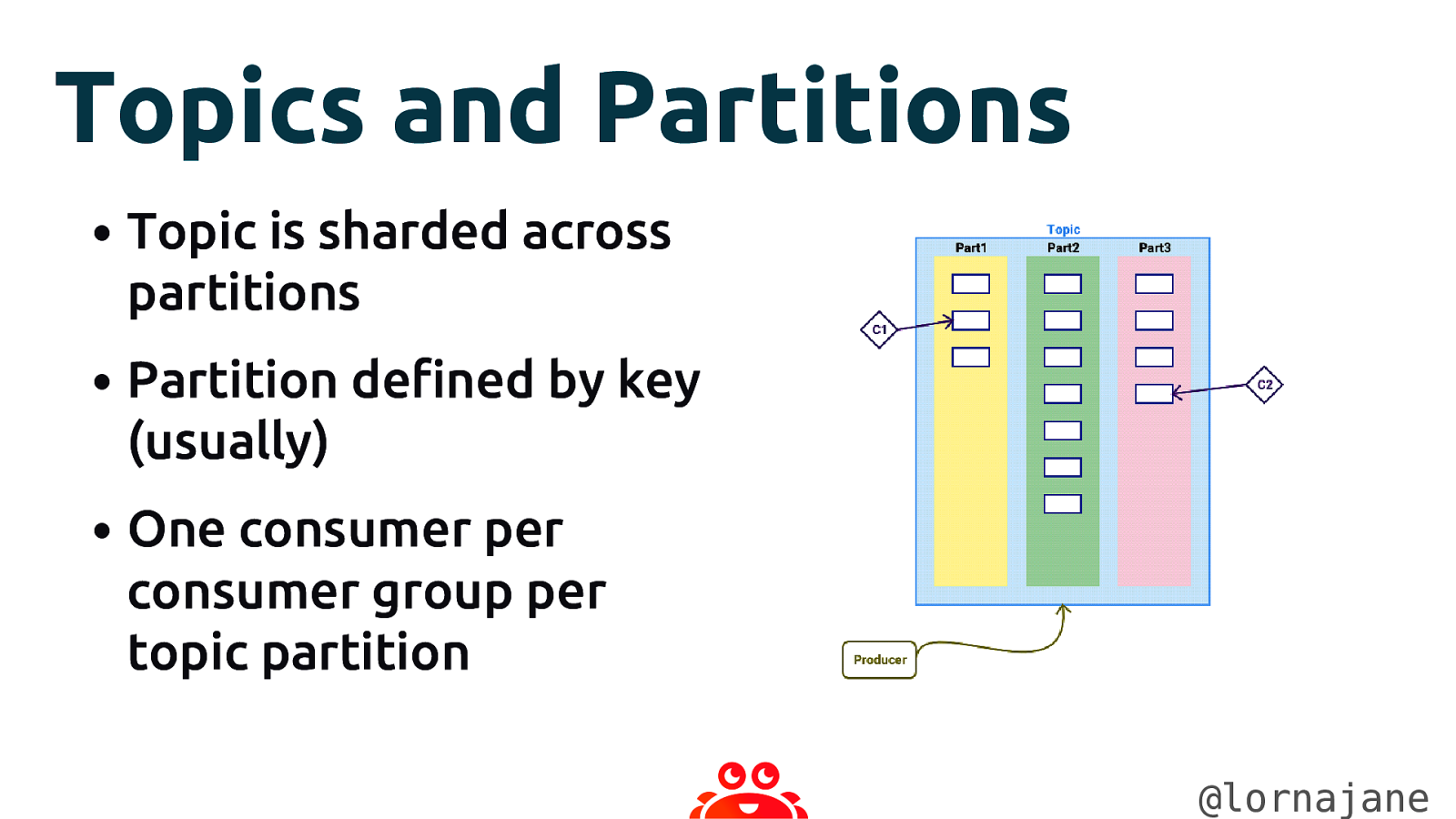
Topics and Partitions • Topic is sharded across partitions • Partition defined by key (usually) • One consumer per consumer group per topic partition @lornajane
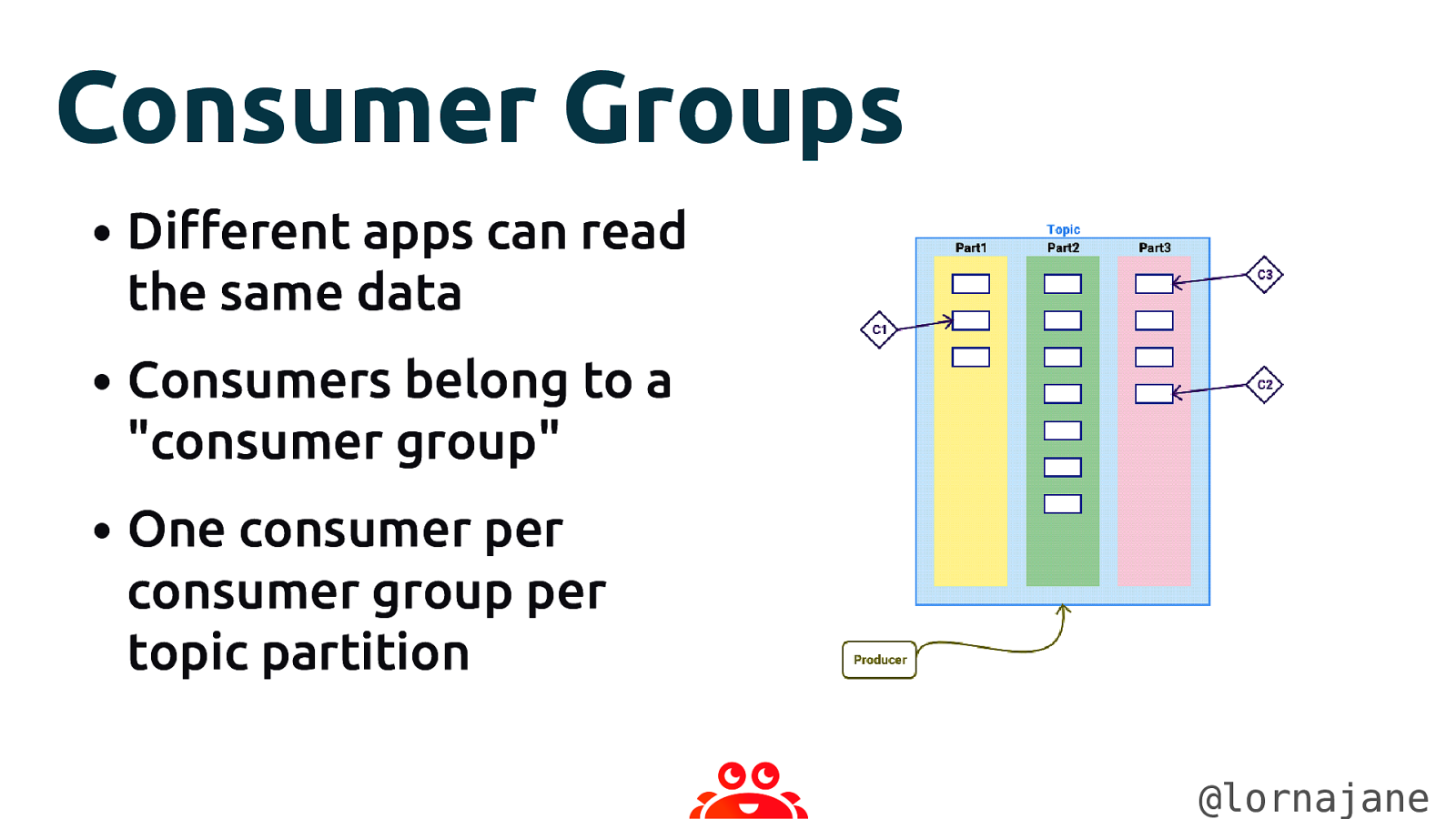
Consumer Groups • Different apps can read the same data • Consumers belong to a “consumer group” • One consumer per consumer group per topic partition @lornajane
Replication Factors • A topic has a “replication factor”, this is how many copies of it will exist. • Replication works at the partition level. @lornajane
Let’s Go https://github.com/aiven/thingum-industries/
Let’s Go Three libraries in today’s examples: • confluentinc/confluent-kafka-go • riferrei/srclient • actgardner/gogen-avro @lornajane
Example: Factory Sensors Imaginary IoT application “Thingum Industries” Which machine? What reading? { “machine”: “MagicMaker3000”, “sensor”: “oven_temp”, “value”: 231, “units”: “C” } @lornajane
Example: Producer Connect to the broker 1 2 3 4 5 6 7 8 9 10 11 p, err := kafka.NewProducer(&kafka.ConfigMap{ “bootstrap.servers”: os.Getenv(“BROKER_URI”), “security.protocol”: “SSL”, “ssl.ca.location”: “../ca.pem”, “ssl.certificate.location”: “../service.cert”, “ssl.key.location”: “../service.key”, }) if err != nil { panic(err) } defer p.Close() @lornajane
Example: Producer Send a record to a topic 1 2 3 4 5 6 7 8 9 10 11 12 mySensorReading := avro.MachineSensor{ Machine: “MagicMaker4000”, Sensor: “oven_temp”, Value: (100*rand.Float32() + 150), Units: “C”, } reading, _ := json.Marshal(mySensorReading) p.Produce(&kafka.Message{ TopicPartition: kafka.TopicPartition{ Topic: &topic, Partition: kafka.PartitionAny}, Value: reading}, nil) @lornajane
Example: Consumer Read from a topic 1 2 3 4 5 6 7 8 9 10 11 12 13 c, err := kafka.NewConsumer(&kafka.ConfigMap{ “bootstrap.servers”: os.Getenv(“BROKER_URI”), “group.id”: “CG1”, “auto.offset.reset”: “earliest”, }) c.SubscribeTopics([]string{topic}, nil) for { msg, _ := c.ReadMessage(-1) fmt.Printf(“Message on %s: %s\n”, msg.TopicPartition, string(msg.Value)) } c.Close() @lornajane
Kafka Tooling Kafka itself ships with some useful shell scripts
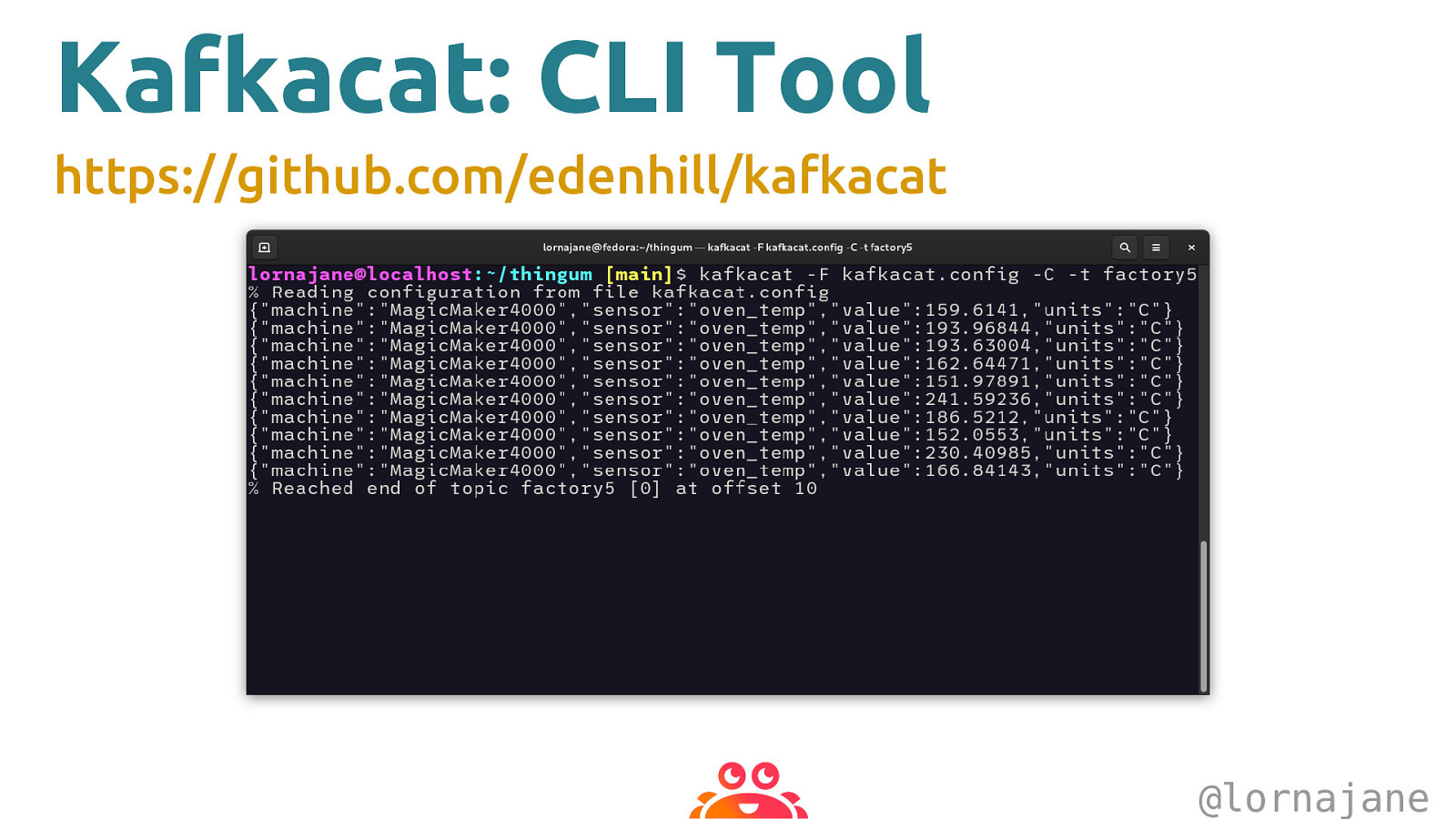
Kafkacat: CLI Tool https://github.com/edenhill/kafkacat @lornajane
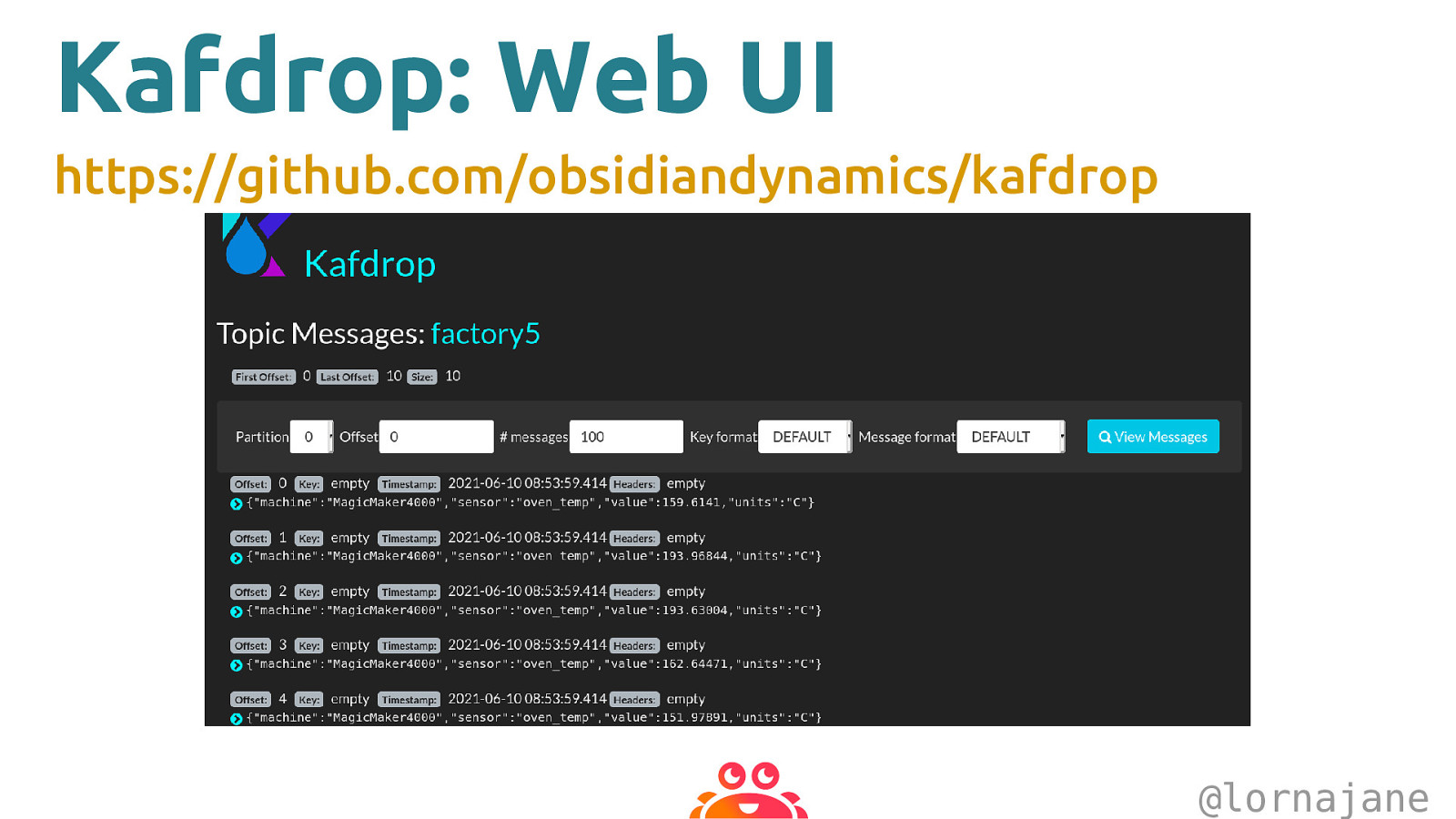
Kafdrop: Web UI https://github.com/obsidiandynamics/kafdrop @lornajane
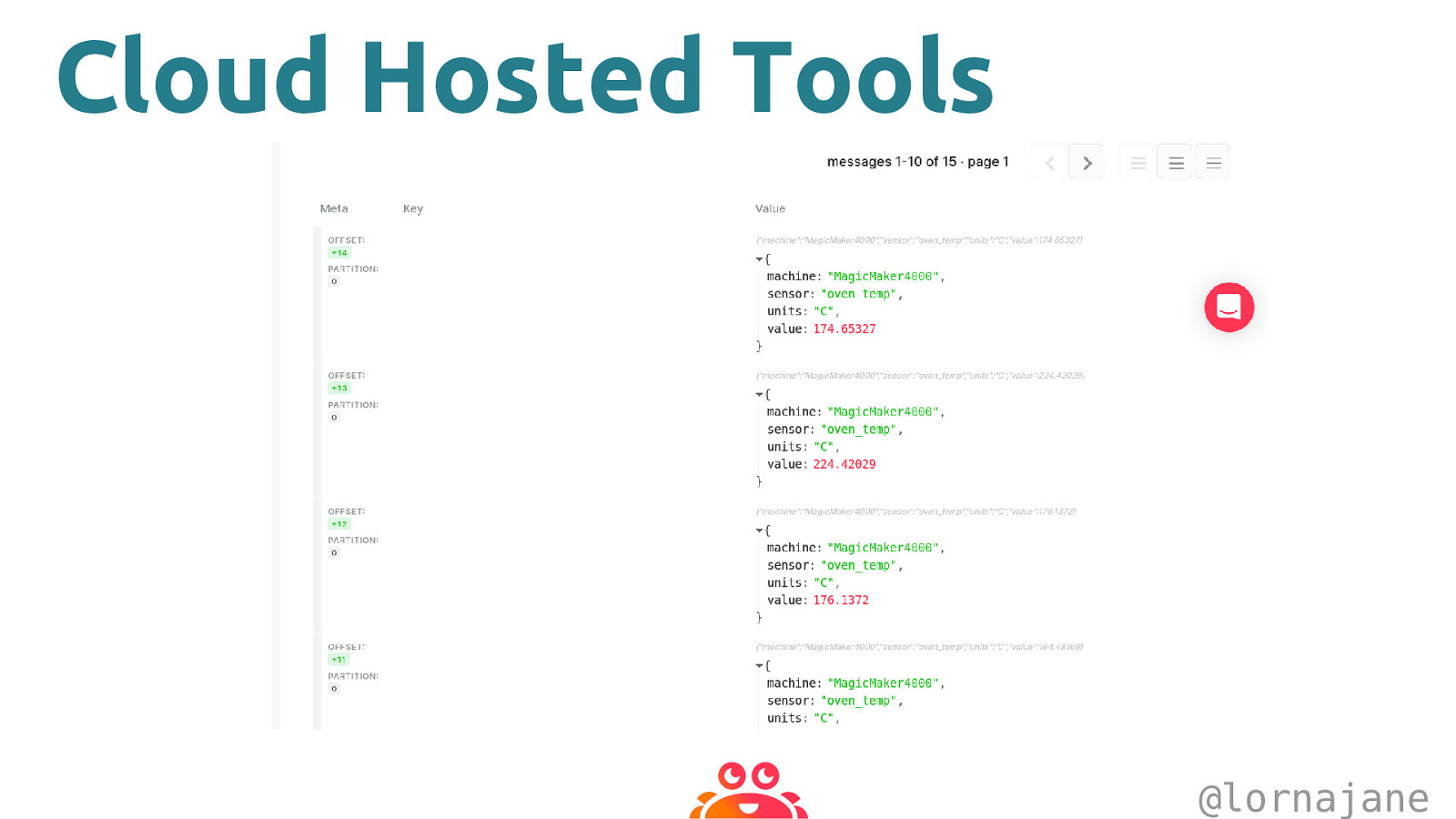
Cloud Hosted Tools @lornajane
Kafka and Schemas
Schemas Schemas are great! • specify and enforce data format • required by compression formats, e.g. Protobuf, Avro Our favourite strongly-typed language really likes schemas @lornajane
Avro Schemas • Avro format requires a schema • message has schema version information • used to look up fieldnames and reconstruct payload • Schema Registry holds the schema versions for each topic @lornajane
Evolving Schemas • Aim for backwards-compatible changes • to rename: add the new field, keep the old one • safe to add optional fields • Each change is a new version • Avro supports aliases and default values @lornajane
Example: Avro Schema Avro schema example for sensor data { “namespace”: “io.aiven.example”, “type”: “record”, “name”: “MachineSensor”, “fields”: [ {“name”: “machine”, “type”: “string”, “doc”: “The machine whose sensor this is”}, {“name”: “sensor”, “type”: “string”, “doc”: “Which sensor was read”}, {“name”: “value”, “type”: “float”, “doc”: “Sensor reading”}, {“name”: “units”, “type”: “string”, “doc”: “Measurement units”} ] } @lornajane
GoGen makes Avro Structs gogen-avro avro machine_sensor.avsc type MachineSensor struct { // The machine whose sensor this is Machine string json:"machine" // Which sensor was read Sensor string json:"sensor" // Sensor reading Value float32 json:"value" // Measurement units Units string json:"units" }
@lornajane
Example: Avro Producer Add awareness of the schema registry, and turn the struct into bytes to add into the payload… 1 2 3 4 5 6 7 8 9 10 11 12 schemaRegistryClient := srclient.CreateSchemaRegistryClient(uri) schema, err := schemaRegistryClient.GetLatestSchema(topic, false) mySensorReading := avro.MachineSensor{ Machine: “MagicMaker4000”, Sensor: “oven_temp”, Value: (100*rand.Float32() + 150), Units: “C”,} var valueBytesBuffer bytes.Buffer mySensorReading.Serialize(&valueBytesBuffer) valueBytes := valueBytesBuffer.Bytes() @lornajane
Example: Avro Producer … then add the schema info, assemble and send. 1 2 3 4 5 6 7 8 9 10 11 12 schemaIDBytes := make([]byte, 4) binary.BigEndian.PutUint32(schemaIDBytes, uint32(schema.ID())) var recordValue []byte recordValue = append(recordValue, byte(0)) recordValue = append(recordValue, schemaIDBytes…) recordValue = append(recordValue, valueBytes…) p.Produce(&kafka.Message{ TopicPartition: kafka.TopicPartition{ Topic: &topic, Partition: kafka.PartitionAny}, Value: recordValue}, nil) @lornajane
Describing Payloads
AsyncAPI for Apache Kafka AsyncAPI describes event-driven architectures https://www.asyncapi.com We can describe the: • brokers and auth • topics • payloads @lornajane
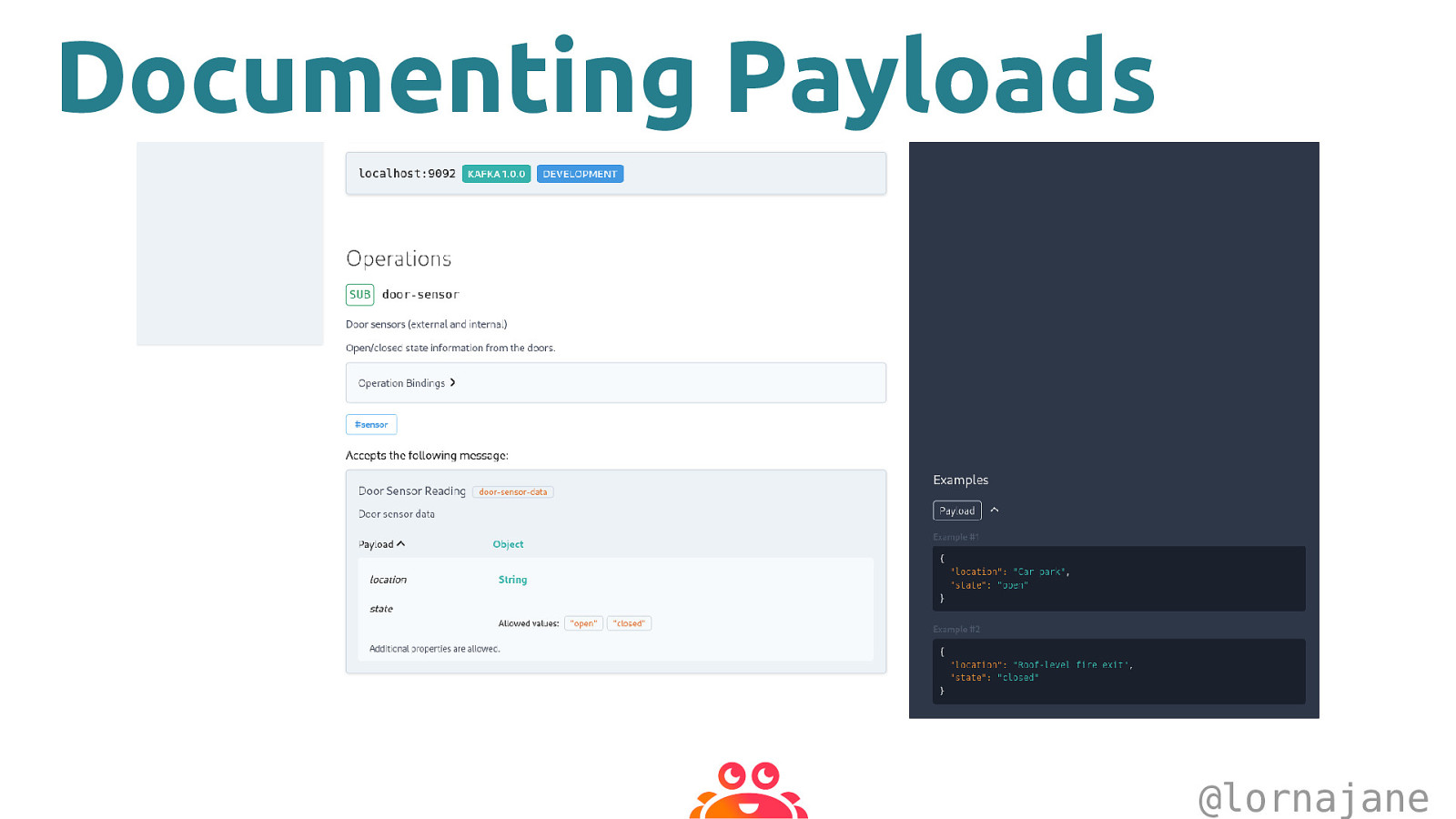
Describing Payloads The channels section of the AsyncAPI document factorysensor: subscribe: operationId: MachineSensor summary: Data from the in-machine sensors bindings: kafka: clientId: type: string message: name: sensor-reading title: Sensor Reading schemaFormat: “application/vnd.apache.avro;version=1.9.0” payload: $ref: machine_sensor.avsc @lornajane
Documenting Payloads @lornajane
Go with Apache Kafka
Resources • Repo: https://github.com/aiven/thingum-industries • Aiven: https://aiven.io (free trial!) • Karapace: https://karapace.io • AsyncAPI: https://asyncapi.com • Me: https://lornajane.net @lornajane
When your data needs outgrow the traditional setup, spend some time getting to know Apache Kafka, an open-source, distributed event streaming platform. With high performance and epic scalability, Apache Kafka can get the data flowing between your applications, components, and other systems with the minimum of fuss. This session will show you around the basics of Kafka, explain the problems it is best suited to solve, and introduce some of the tools that make dealing with it so delightful. We’ll also show how you can use Kafka from your Go applications, and showcase the integrations such as Kafka Connect that can really take your systems to the next level. This session is recommended for engineers, data specialists and tech leaders alike.