
A presentation at DevOps Days Birmingham in in Birmingham, UK by Matt Machell

Hi I’m Matt and I work for a trendy little startup you might have heard of called the Civil Service. More specifically I work in Birmingham with the Office of the Public Guardian who are part of the Ministry of Justice. We handle Lasting Powers of Attorney.
So this a presentation about being agile and adapting to devops ways of working. It’s also the story of how we improved our ability to deliver. It’s about how we went from 1 release every two weeks if we were lucky to 8 releases a day.
But also it’s about how a lot of that wasn’t about the cool toys like Terraform or GitHub (although we did use those) or buying a developer experience or micro-serviceing all the things!. It’s about the ways of working around the technology and how one facilitates the other. About the way work flows into a team and the way the team works together. Because making the devops work work involved addressing lots of the wider structural issues in teams and around the organisation. And that sometimes that’s hard.
There’s some lessons learned here. A lot of this comes from working with a big organisation that is trying to radically shift its technology. We’re 60 odd people across 6 or so product workstreams. Remember all organisations are different shapes, at different stages and broken in different ways. Ultimately they all contain people all struggling to make the best of their situation. So it’s more a playbook of things you might like to try, areas to focus on and how to measure if they work for you. It’s about looking at the systemic and communication flaws and harness the technology to aid fixing those.
First a bit of context. One of the things large organisations like to talk about at the moment is “Digital Transformation”. Which means getting out of legacy ways of doing things. Bringing your people and technology kicking and screaming into mid 2009. This doesn’t always go according to plan. Now it all starts with the best of intentions. Maybe you built an initial new product to prove you can deliver a user-centric web app with a multidisciplinary team. It’s deployed in “The Cloud”. Ticks all relevant buzzwords. But there’s a point where the shape of the work shifts and what was working, won’t any more.
Which, basically is not an agile environment. Oh sure, there were lots of ceremonies. But the fundamental feedback cycles and collaboration had started to break down. And importantly, it’s not the fault of the people in the team. The structures that had built up organically around the teams were hampering them. Which has led to…
We love talking about tech debt as architects. But the naming has consequences. It pushes the ownership onto the technical professions, it frames it in a way such that it isn’t anyone else’s issue and it neatly hides what it really is: stuff that stops us delivering a quality product fast.
Does that help shift how we see it? Does it help connect our list of symptoms and our underlying problem more? Help us with our conversations in a team? Everything you compromised on to get something out the door is slowing you down.
Sure there’s a bunch of usual suspects here. Not enough automated tests, code you didn’t make easy to change or clear to comprehend, layers of needless indirection you didn’t get rid of, dependencies written by someone in Virginia that hasn’t been updated in a decade, libraries you didn’t bother to keep up to date. Your b business people glaze over when you talk like that. A focus on measurable impact on speed of delivery is a powerful argument for justifying your work and the change you need to make.
This is, incidentally, where we were about 4 years ago. And, because the digital gods love to laugh at us, at around that point we were reaching end of life on core components chosen back at the start of the work. For us that was a reliance on Ubuntu 14.04, which was losing security support. And also had a deployment system based on hand rolled Docker orchestration with Salt, Ansible, Fabric, Duct Tape, String and optimism. How do you (did we) speed up delivery and get ourselves out of this situation? Well, never underestimate a good crisis to instigate change.
Speed was our selling point. So this is the first question to ask. What’s stopping you getting user stories out into the world? Is your code easy enough to modify that you can build a new feature in a few days? Hours? What ways of working do you have that are slowing you down? How can you change them? Agile manifesto, right? satisfy the customer through early and continuous delivery of valuable software.
Explaining what’s blocking you in terms of impacts not technical jargon. Showing the value of technical change as a force multiplier to everything else. Using real measurements. Do your product people understand that ever tiny change is waiting on 45 minutes of build time. Multiple times for each change. Your product or business people often think you’re arguing for new toys, rather than updates just to keep moving. We started breaking things down by security, maintainability, simplification, testability and sustainability.
The other thing preventing change was stacking up lots of interdependent change in releases. more unintended consequences from interacting code backing out an individual change is harder increases any manual test time increases the feedback cycle from users
It’s likely your product and business people think that by doing this they get better software. So this involves having hard conversations. Examining what value people think they are getting from their current process. And this drove our first rule:
Satisfy the customer through early and continuous delivery of valuable software. So I’m talking your main branch on GitHub. Yes that includes Friday afternoon. Does that scare you, your team or your business folk? Why is that? What can we do to our process to change that and give confidence?
That’s the look your product people give when you initially suggest releasing any time you like. You’re all devops adjacent people that probably doesn’t scare you, but “don’t release on a Friday” is literally a meme at this point for everyone else. It’s in the back of their minds.
But the act of deconstructing that fear can be a powerful one. Asking “Ok, WHY does that scare you?” And then follow up with “What’s the risk here? What can we change that will give you confidence?“ Then turning that into a roadmap of things to fix.
These are the things we needed to change to guarantee we can release main at any point.
It’s probably worth pointing out that while we were working on creating the todo list we were importing all our AWS Infrastructure into Terraform and stripping out the extraneous bits. We wanted to reduce the complexity of infrastructure and how we manage it. One tool for deploying both backing resources and containers. One tool to learn and maintain. One tool to bring them all and in the darkness, no wait…
Fundamentally the further the people who are building the software are from the users, the less effective they are at building the right thing. Your code, your interface, your tests, your observability. All of that relies on understanding who you are really building for and why. Some of this gets lost in organisational design as you move on from initial agile implementation. Agile manifesto: Business people and developers must work together daily throughout the project. When did your developers last talk to an actual user?
So understanding a piece of change involves looking at where it came from. If your process looks like users who talk to a researcher throwing over the fence to a PM throwing over to a Designer then throwing it to Developer who throws it to a QA to test who throws it to a Ops person to release, then well done, you’ve reinvented waterfall with sprint ceremonies.
The lines of communication in this process are fundamentally broken. Because the questions one person need answers to might not be being asked by somebody further up the chain and included in what they throw over the fence. This creates exactly the problem agile was designed to fix, which is that the people in each part of the process have no idea of the needs that drives the others work. Because comms down the chain is lossy at each step. Is the person at the start even providing what is needed by somebody down the chain?
You want lines of communication more like this. Looks like chaos right? (Joke for the Warhammer fans there). But ensures you don’t lose the signal in the communication. Each of those connections is probably a conversation you should consider having to understands each-others’ work and needs. How you hold kickoffs and refinement sessions, and who you choose to invite can change the amount of time you spend querying back.
Stop things being blocked by “we can’t build that” or “what do you mean?” Work across disciplines as early as possible. Break down silos. If your product people are talking to TAs they can avoid building symptomatic solutions and find alignment between the product work and technical work If designers know the outputs a developer needs to build a thing, then you don’t create long cycles of throwing back If devs know the way infrastructure works, they can build better for it.
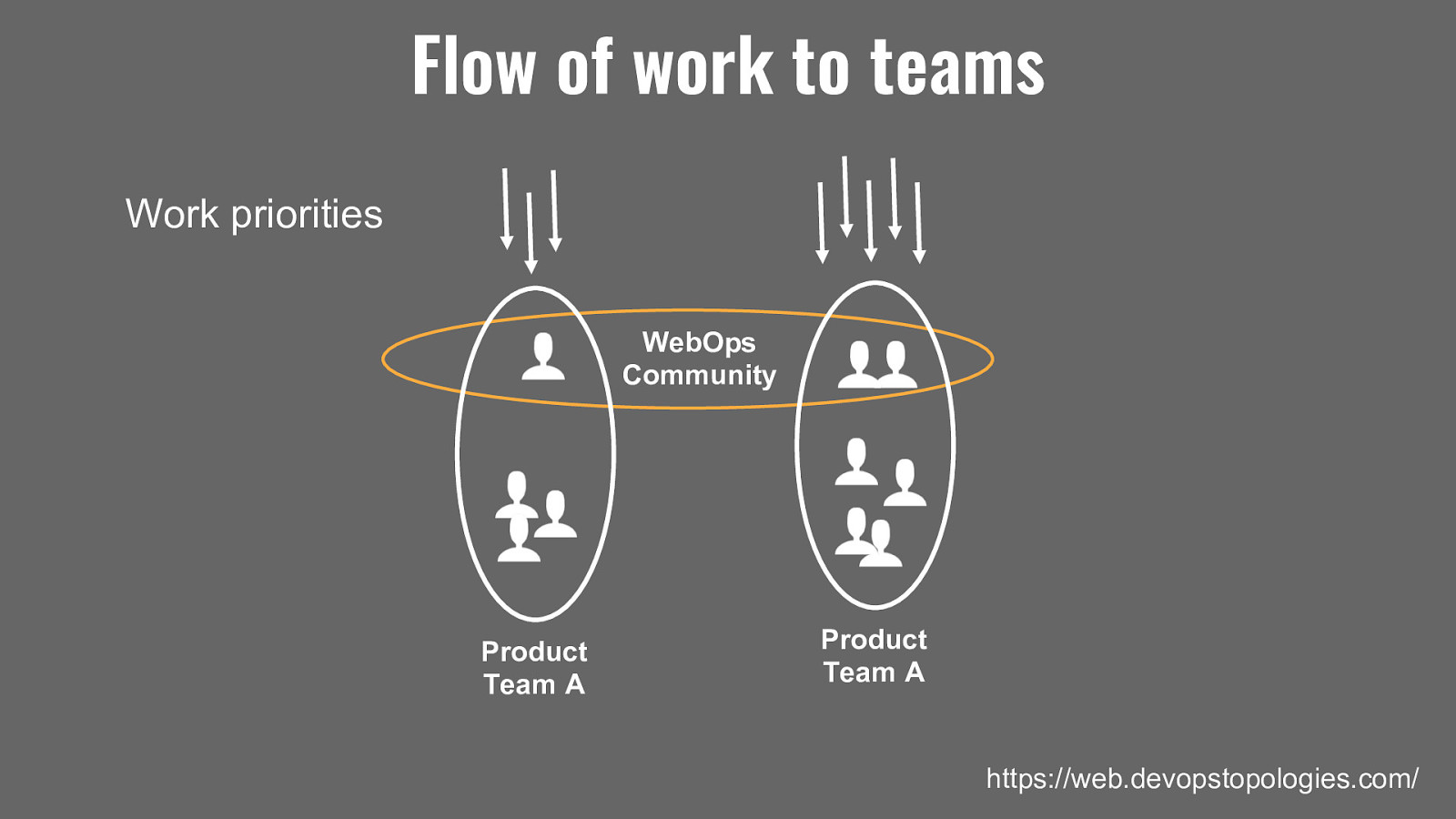
Speaking of breaking silos. What we had was a fairly classic WebOps team who looked after infrastructure and tried to prioritise their work alone, then try and do that work to the other teams. Which of course was a problem as it required both teams aligning their work, despite having different planning meetings, different product owners setting priorities and different working practices. So the communications overhead was greatly increased. People ended up being pulled different directions. And nobody was very happy because they couldn’t effectively do the work they needed to do.
So we moved our model to be more like this. Webops within teams, so the whole team owned the product app, infra, build pipelines. And we have a cross-cutting community of practice to share knowledge, agree standards, mentor and set best practice. If your infrastructure people are in the delivery team can ask questions like “how are we going to support this?” and “how do we get this live?” early. Understand the downstream impact of change early to stave of issues. But also it means you are prioritising the work together and keeping visibility of importance of infrastructure work in the team. It’s not somebody else’s problem.
Where you have cross-cutting concerns like infrastructure, security or testing. If you need to build awareness, capabilities and start to understand what good looks like build a community to own that from the ground up. They help build advocates for approaches who can take the learning back to their team. Give support so people don’t feel like lone voices in their teams. Help develop tactics for bringing everybody else along that work for your organsiation. Aside: You hear quite a lot how hiring people with devops skills is really hard. Turns out if you get them pairing with developers you basically breed your own. All your developers pick up Terraform by osmosis.
One of the anti-patterns we were keen to undo was a cycle where developers only cared about a ticket until they merge it. Change the mentality to “it’s only done when it’s with a real user”. Encourages pairing with WebOps so they know what happens next. Also encourages thinking about the value to a user once live. Part of that means changing how you prep tickets to talk about different issues:
Use your refinement sessions to shift the expectations here. Find the weird edge cases. Build a team culture of, if you don’t have that info to work a ticket, push the ticket back to refinement.
If you have to make a decision the more armed with context you are the better that decision will be. Better decisions mean fewer bugs. Undo the pattern of everybody is thinking in terms of throwing their preferred output to the next person. Not asking what that person really needs. This might mean some repeated and quite painful ways of working sessions where you thrash this out.
The next thing we worked on was this: How does a change go from idea to release? How does each step in that process give you confidence and what value is it giving? Asking the question “so how does a user story get to production?” Led to some really interesting stories about how things go forward, then back, then left, then north. Then get eaten by a grue. Oh, sorry path to live is blocked because somebody is testing a branch on pre-prod.
You’d probably never write code the way your release process works. Well maybe some of you would. ;) Look for the dead-ends, bottlenecks, the places where things get blocked or go backwards, the duplication, the manual interventions, the frustrations and the needless asking for information you already have. Refactor it.
Design this process with intent. With the entire delivery team. Who are your users? What are their problems? What value does each step really confer?
You path may look something like this. Ours did. What purpose do your environments serve? Who uses them and why? Who’s waiting to do their work because somebody else is using an environment? And do they don’t know the state of the data? Has somebody changed the data and forgot to tell them. Lots of person hours wasted because of that bottleneck and the associated communication burden.
Where are you double handling the app? Are you duplicating automated tests with manual tests? Are your devs, your QA, the business and product all doing the same tests multiple times to no additional benefit? Were you even aware of that? Are you manually testing the same set of changes multiple times because you are stacking them up on staging. Change 1 is tested 3 times more than it needs to be. That gets exponentially worse if you stack a sprints worth of stories.
With modern infrastructure as code - just build a new environment and tear it down when you are done demoing/testing/whatever. Or automatically after merge of a PR or 3 hours or at 6pm. Whatever works for your team. These ephemeral environments were one of our biggest process improvements. Terraform + Amazon Elastic Container Service + Fargate Spot + Aurora Serverless. Cheap feature environments for everyone!
What automated tests will help give you confidence at each stage? You want automated gates that allow good change out and block broken change. Because machines are good at doing repeatable drudgery fast. Focus your human tests on high risk areas. No more clicking about a bit. Now you could say, why aren’t you just pushing to direct main. And the point here is trust. By having isolated dev environments we allow our users and product people to fully explore and demo a new feature before it gets merged. We can also run a full test suite against real infrastructure so we can prove this version of the app works with this version of the infrastructure..
Remember it’s not fixed once and then done. Have a meeting to measure and iterate. That can bring a lot of improvement.. Which test suites or build steps are slow? What’s changed? Where can we optimise? What can we parallelise? What are your flakey tests and where did they come from? What’s pushing us above 10 minutes for a build? Which bits of infrastructure take a long time to come up?
Flow small changes out at pace and with comprehensive automated checks. Make it so that a release isn’t a big event. Once releasing is easy, solving your other problems is easier.
Aside: Lean UX approaches work by framing of things as experiments. Sometimes “as a user who wants a dashboard, I want a dashboard, so I can view things on the dashboard” might not be working for you. Framing as experiments helps focus on outcomes “ we believe that by implementing a dashboard users will act on a downturn in widget production and we’ll know this if they we see an increase of widget production query events”. This might focus the mind on “how do we know if this work is valuable and measure its success in live?”
It took about 6 months. But the important thing was that at every stage our users and colleagues had confidence in us and OK’d us moving to the next level. Because they trusted us and we worked with them, we went from users being scared of releases to not even noticing them. And the users and business now love us as we can get new features, big fixes and improvements out faster. And we can fix our out of date or insecure packages faster. Our cycle time for new work went from an average 8 days to an average 3 days.
Back to our todo list.
If you’re in a place where nobody trusts you to not be delivering buggy software. You can’t just say: “hey we’d like to deploy to production whenever we like!” You’ve got to earn that. You’ll need to have some conversations with your business folk. Fundamentally this is about trust. You end up with extensive manual testing cycles because people don’t trust your team not to deliver a buggy mess. And we’re DevOps folk, right? We’re aiming for minimal failing releases.
Demming did a lot of work on manufacturing in Japan in the 50s. He found that companies would throw a lot of person hours into testing products at the end of manufacturing, but got very little return on that effort. No matter how many people you add checking the widgets, you still got bad widgets. The issues creating the bad widgets were still upstream. The same applies to software. Throwing more more QAs on at the end doesn’t improve a product, building the quality in does. We found we had product people testing things, QA testers testing, BAs testing and business side training teams testing. We had lots of gatekeepers doing inspection. We still had lots of bugs.
This is a long term project in building trust. Cypress’s and other tools video export is great for this. Or just plain showing a user what an automated test is doing. Pairing, again. This is teaching your colleagues that: A machine can do it faster than you and more consistently. Why are you doing the boring work that WebDriver can do for you? Wouldn’t you rather work on measuring the tests and building a coherent test strategy?
This took about a year for our largest app. You might have to write more user journey level tests that drive the browser than you might normally do. Your test pyramid might get a bit wonky, but that’s OK because you are using it to build trust because it’s visible and comprehensible outside of engineering. Once it’s done you can push tests down from user journey, to integration to unit. The trust doesn’t go away once you have it.
This all requires a lot of test automation. You’ll need to get good at that. Embed it in the expectations of a user stories’ delivery. But also set some expectations of what good looks like. Definition of ready and definition of done are great tools for this. As with WebOps we built a community of practice around what good testing actually looks like. And going out of your way to hire developers who work in a Test Driven Development fashion.
Bugs don’t happen because you failed to test, their origins are much earlier on. At ticket writing, or during research or from a fundamentally faulty premise in discovery. They happen because of miscommunication, which goes back to our earlier talk about discipline collaboration early. “Oh you didn’t say the button had to work” - genuine quote from a contractor I once worked with. If you change the process that led to bugs, you get fewer bugs.
What are the common patterns? What aren’t we capturing early enough? Where is our code marked “here be dragons” and people are afraid to touch it? Feed that back into the cycle. What was the source of the issue? Bugs don’t just happen. They happen because your user story was unclear. Or an assumption was made. Or developers didn’t know how one area of code interacted with another. Every bug is a conversation that didn’t happen. Who finds most of your bugs. Track that. Like us you may find your developers are finding more than the gatekeepers. Which is evidence to go back to the business folk with.
Sources of bugs are the un-held conversations in this diagram. Getting good at test automation forces you to reassess your teams ways of sourcing work and writing user stories. What key pieces of information and at what fidelity do you need to work on a ticket? Who from? When?
Everything else in this pretty much relies on good automated tests. So make it clear that’s a key part of your work. Your future self will thank you for it. You definitely don’t want to have to migrate to an entirely new platform on a system with no end-to-end automated journeys. That annoys all concerned.
So, in summary
How applying devops principles and adjusting ways of working got us to continuous delivery.

















































 for free. You
can too.
for free. You
can too.