Machine-enabled noun foraging for OOUX a a f a a a a Rik Willi ms, UX Architect, Moor ields Eye Hospit l rikwilli ms.net/t lks/m chine-noun-for ging/

A presentation at OOUX Happy Hour in April 2022 in Atlanta, GA, USA by Rik Williams

Machine-enabled noun foraging for OOUX a a f a a a a Rik Willi ms, UX Architect, Moor ields Eye Hospit l rikwilli ms.net/t lks/m chine-noun-for ging/
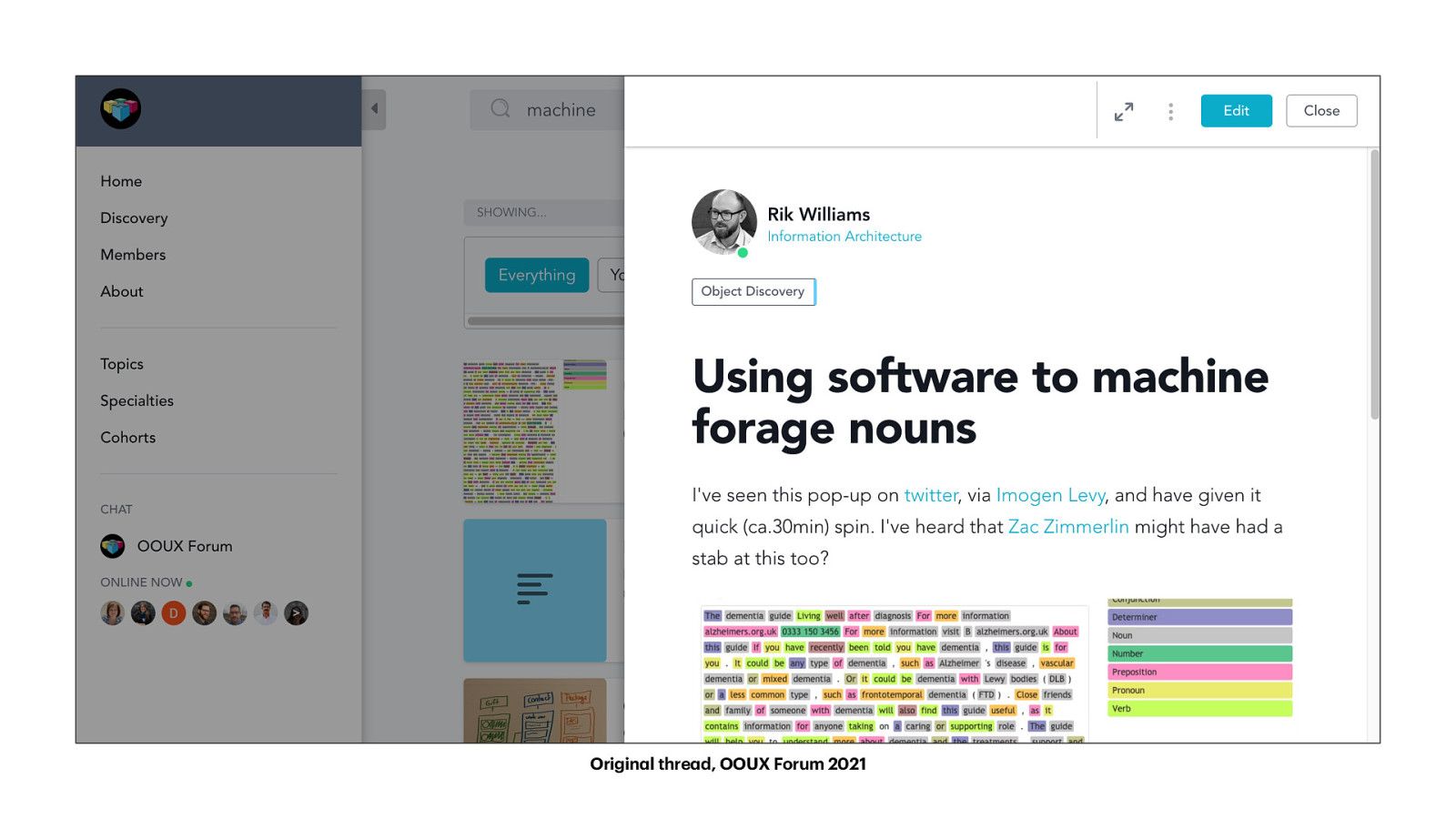
a a Origin l thre d, OOUX Forum 2021

Used in two organisations, so far… 2021 2022

Structure Parts of Speech tagging Noun sources When machine foraging is most useful Practical — my work low, so far… Merits Limits f Discussion

Parts of Speech Tagging
…or ‘grammatical tagging’

“The process of marking-up a word in a text (corpus) as it corresponds to a particular part of speech, based on both its de nition and its context.” fi a Wikipedi

“Automatically nding + tagging nouns in textbased data using computational linguistic algorithms.” fi a a a Me, on PoS T gging s pplied to OOUX

a Source: https://p rts-of-speech.info/

a Source: https://p rts-of-speech.info/

Noun sources

…‘text-based data’… 🧐🤔
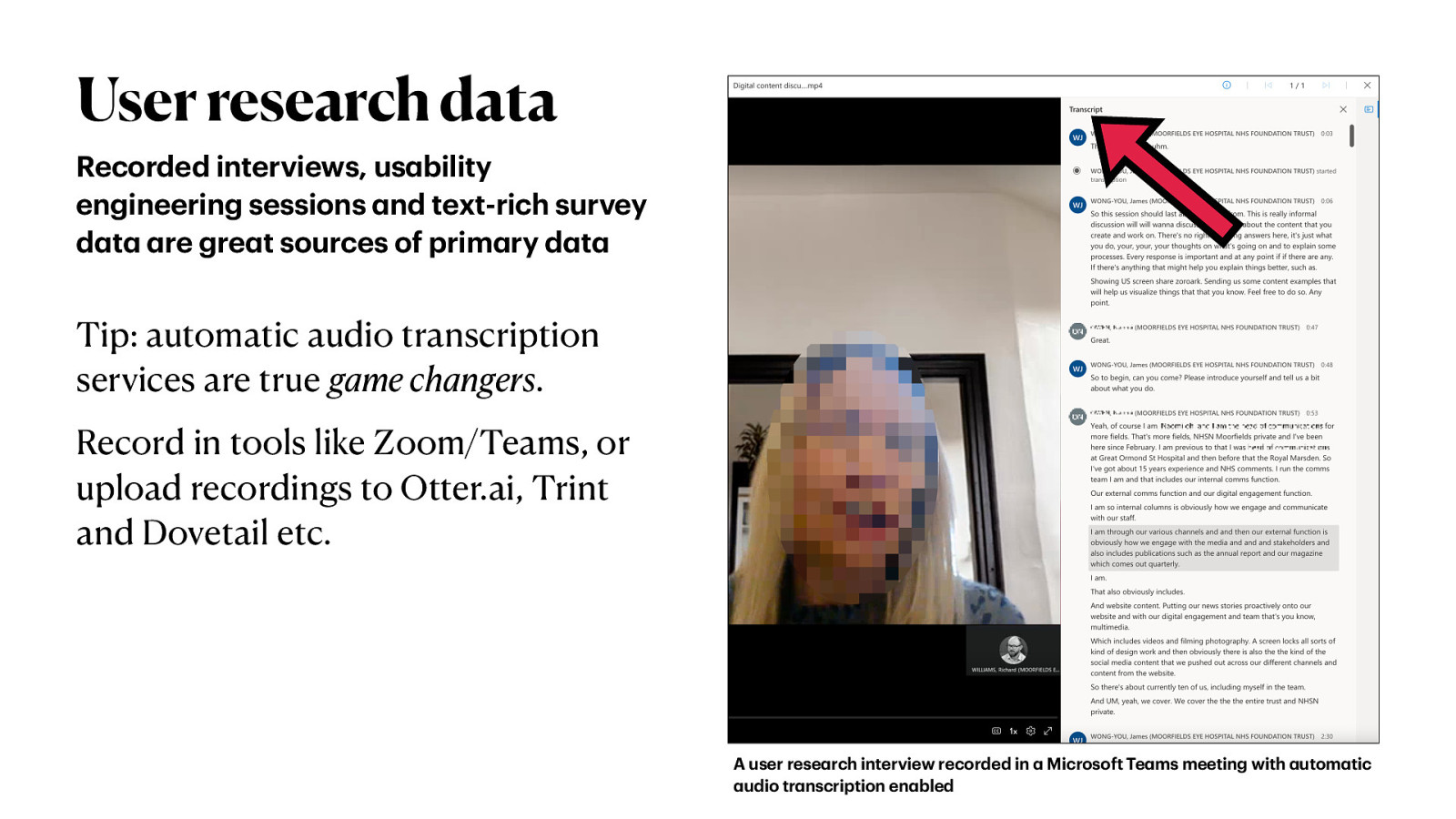
Recorded interviews, us bility engineering sessions nd text-rich survey d t re gre t sources of prim ry d t Tip: automatic audio transcription services are true game changers. Record in tools like Zoom/Teams, or upload recordings to Otter.ai, Trint and Dovetail etc. a a a a a a a a a a a a a a a A user rese rch interview recorded in udio tr nscription en bled a a User research data Microsoft Te ms meeting with utom tic

PDF A justly m ligned form t, but still strong source of text-b sed nouns Tip: look for domain de nitive PDFs, both from your own organisation, competitors and the world, like: • • • • annual reports user manuals factual advice for users 5-year strategies … a a a a a a a fi f a a a a a An ex mple of vi PDF single dom in de initive d t source, of type typic lly served

Social conversations Use soci l listening d t , or mine d t b se t ble exports from user forums Tip: consider partnering with a social listening agency/partner to get the social data, at the greatest scale from the best mix of sources. a a a a a a a a a a a a a a a Soci l listening d t from 1 million re l convers tions bout termin l dise se
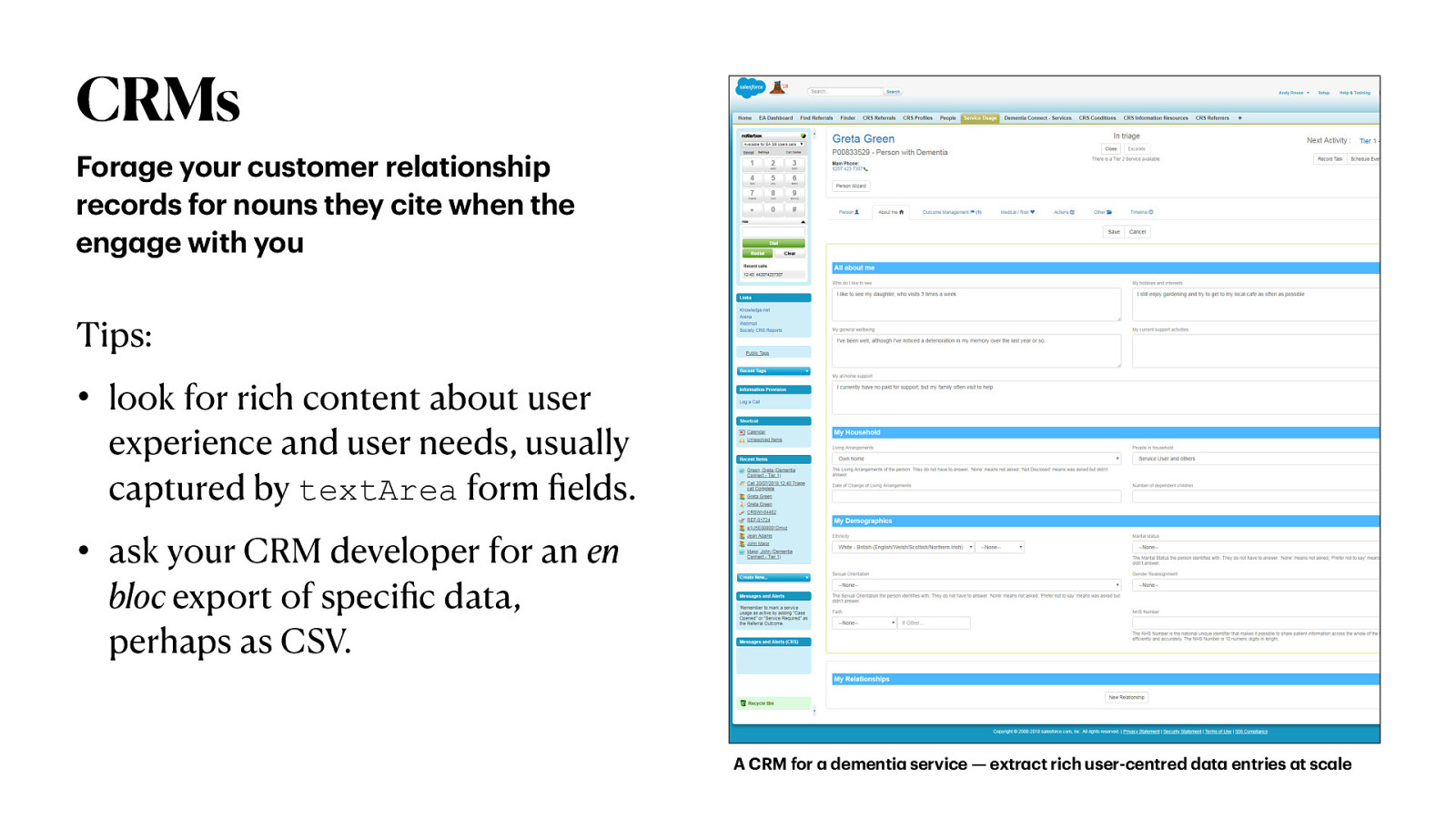
CRMs For ge your customer rel tionship records for nouns they cite when the eng ge with you Tips: • • look for rich content about user experience and user needs, usually captured by textArea form elds. ask your CRM developer for an en bloc export of speci c data, perhaps as CSV. a a a a fi a fi a a a a a A CRM for dementi service — extr ct rich user-centred d t entries t sc le

Content inventories Well formed titles, he dings, met descriptions nd URLs re ll noun sources Tips: look beyond your own website. a a a a a a a An inventory gener ted in 10-mins for Cr te & B rrel using Scre mingFrog Spider a • use machine-built inventories for their speed, scale, accuracy and (meta)data types. I use ScreamingFrog SEO Spider. a •

Project documents P rticul rly useful so th t ‘intern l only’ d t c n be included Tip: a good start point if you’re joining, or specifying, a project at its outset. But note that these are secondary and non user verbatim sources. a a a a f a a a a a a a a f f a A speci ic tion brief for public tender process to ind/select n gency p rtner for Moor ields Eye Hospit l.

Webpages At more th n 50 billion p ges, the WWW is n inexh ustible source! Tip: consider trialling Sketch Engine which can nd and fetch textual data via its automatic corpus builder. It can compile nouns at scale via its:… • • • web search, URLs list, website download (up to 10k pages) …functions. a a a a a a a a fi a a a Look for dom in relev nt sources, like blog posts, rticles, p pers, dvice. Both from your own org nis tion, competitors or the wider web.

Noun source considerations … s with history, be critic l of your sources Validity, bias • • are you using a primary (verbatim/user), or a secondary sources (corporate/marketing)? is the source truly relevant to your research domain? Quality • is the source data well-formed, designed? Size, spread • • how large is the corpus? how many sources are you using? Internationalisation can your tagging software work beyond English (and major European languages)? a a •

When is machine noun foraging most useful?

a a a Source: H v n Nguyen’s UX Process

a a a a Source: H v n Nguyen’s UX Process, with dded OOUX with ORCA
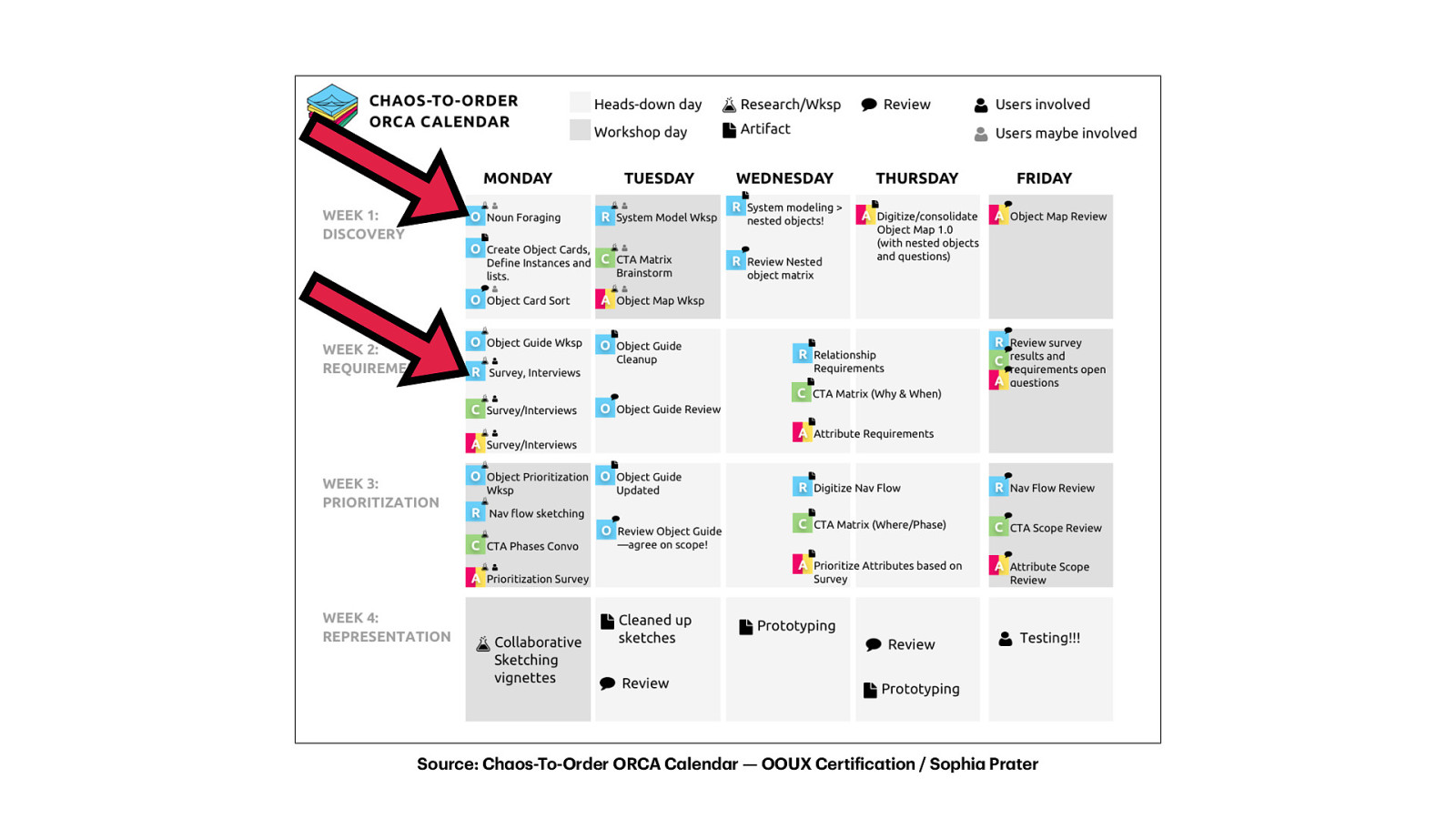
a a a f a a a Source: Ch os-To-Order ORCA C lend r — OOUX Certi ic tion / Sophi Pr ter
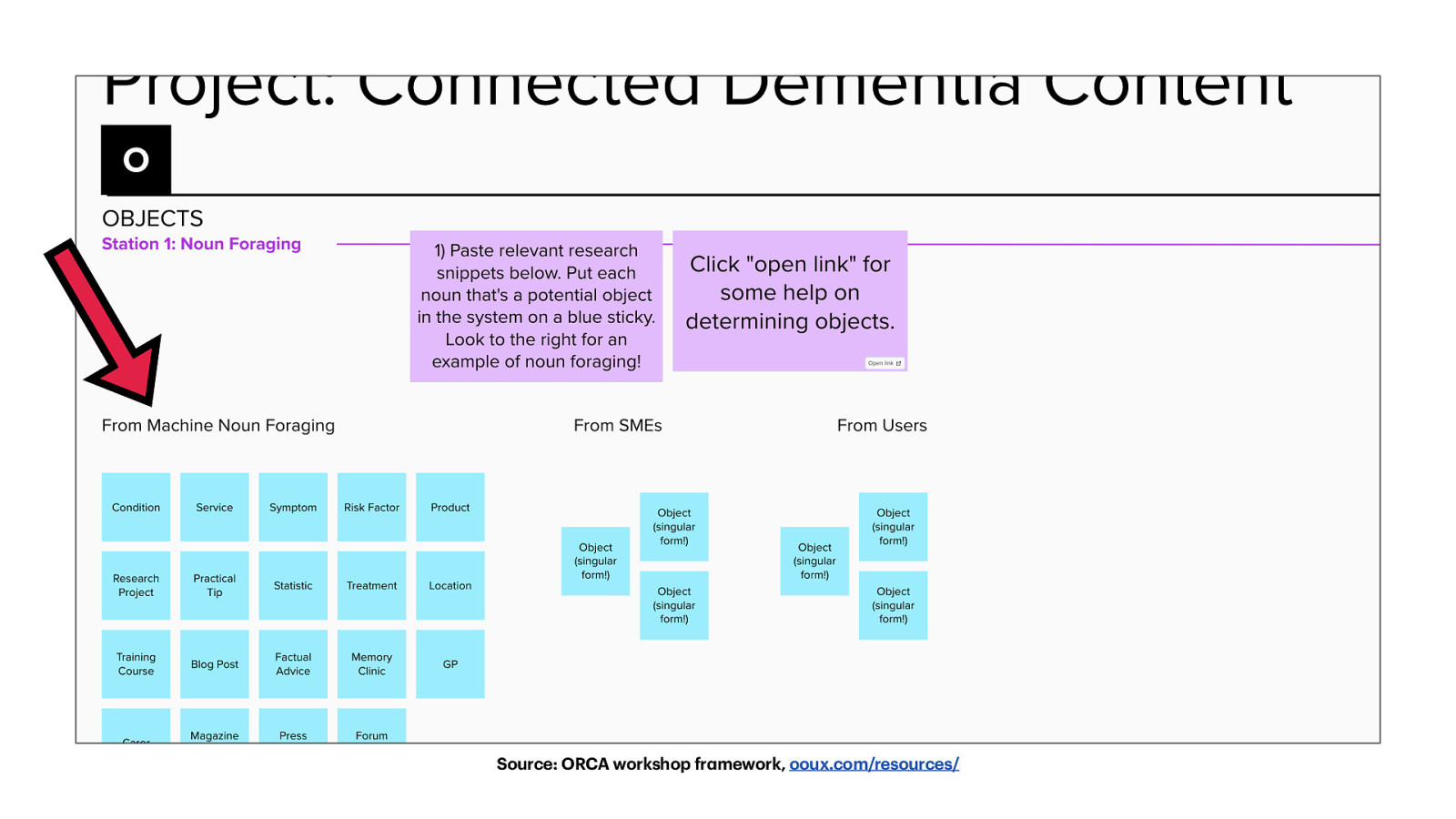
a Source: ORCA workshop fr mework, ooux.com/resources/

fl Practical — my work ow, so far…


Step 1 Choose your source text / d t We’ll be working through The Dementia Guide PDF. This is a good domain de nitive, large and noun-rich source (PDF) with which to experiment. a a a fi Source: https://bit.ly/dementi -guide-pdf

Step 2 Extr ct its corpus Select all, then copy and paste into… https://parts-of-speech.info/ …and run the tagger. a a a a T gged content from The Dementi Guide PDF in https://p rts-of-speech.info/
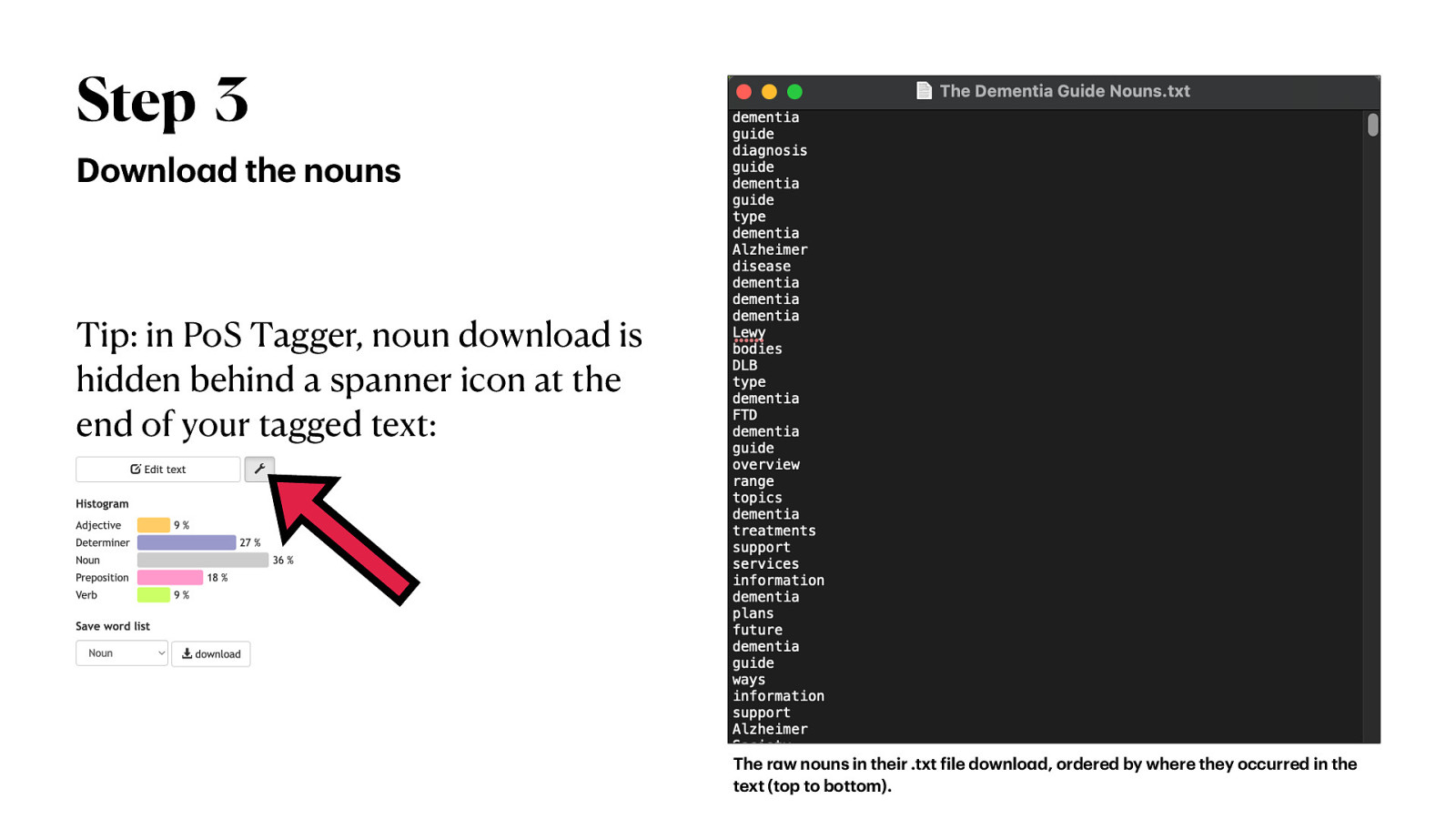
Step 3 Downlo d the nouns Tip: in PoS Tagger, noun download is hidden behind a spanner icon at the end of your tagged text: a f a a The r w nouns in their .txt ile downlo d, ordered by where they occurred in the text (top to bottom).

Step 4a S nitise nd norm lise the nouns Tips: sort by alphabet to reveal groupings. sort by noun count to reveal occurrences. look for plurals, these might mean instances, and instances might mean Objects. • a a a a a a a a remove junk content to increase signal and decrease noise in your data. a a a a • normalise plurals so that their noun count is accurate. a • • • Norm lising plur ls to their singul r form so th t their count (8+14) is ccur te. For ex mple, the noun ‘condition’ would occur 22 times fter norm lising plur ls.
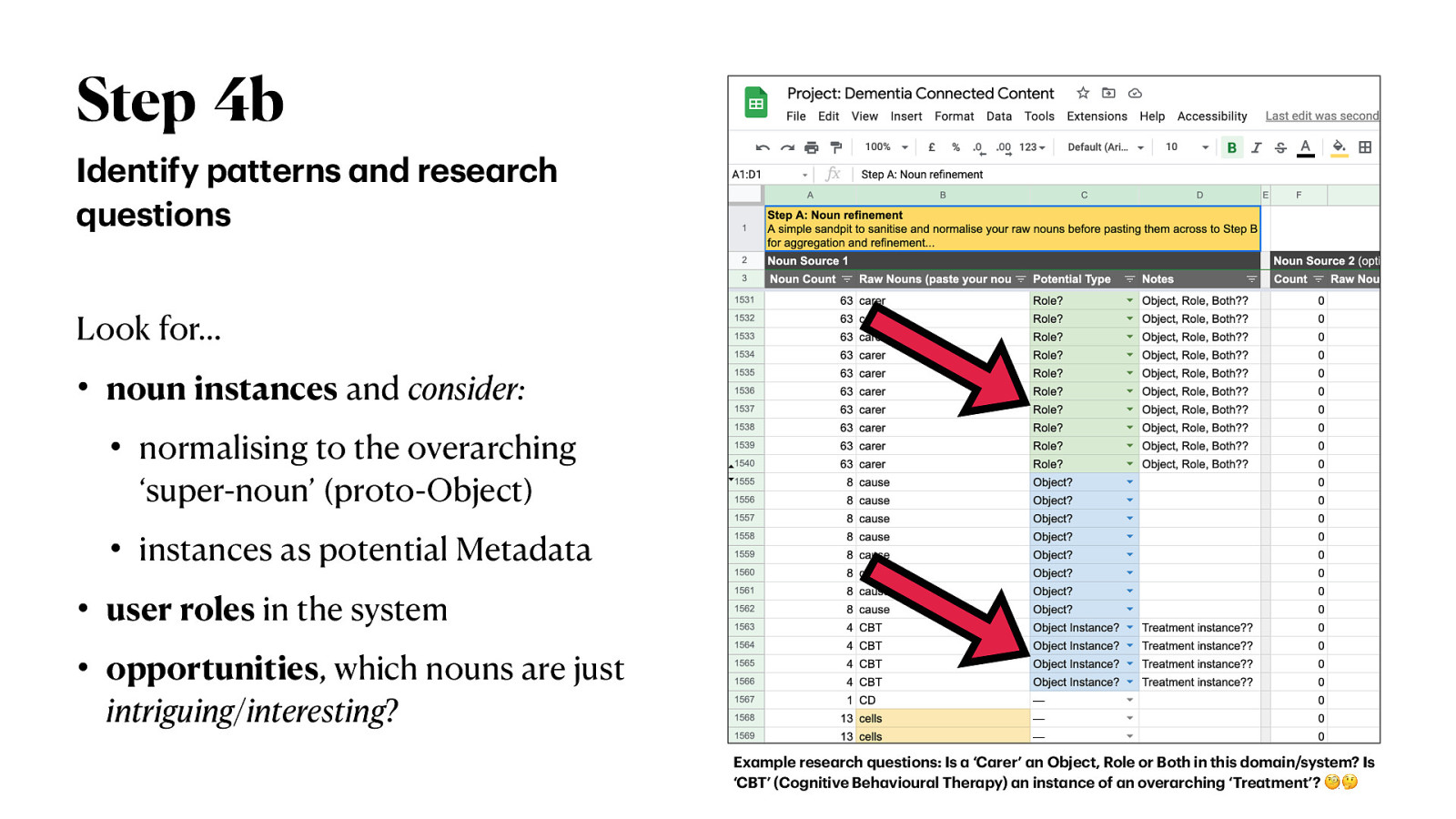
Step 4b Identify p tterns nd rese rch questions Look for… • noun instances and consider: • • • • normalising to the overarching ‘super-noun’ (proto-Object) instances as potential Metadata user roles in the system opportunities, which nouns are just intriguing/interesting? a a a a a a a a a a a a a a a a a Ex mple rese rch questions: Is ‘C rer’ n Object, Role or Both in this dom in/system? Is ‘CBT’ (Cognitive Beh viour l Ther py) n inst nce of n over rching ‘Tre tment’? 🧐 🤔

Step 5 (optional) Aggreg te nd tri ngul te Tips: use many content sources (both types and instances) so that your analysis is more robust. a a a a a a a a a a a a a Tri ngul ting nouns from m ny count sources nd ssessing their comp r tive frequency of occurrence. Source: https://bit.ly/m chine-noun-counting-templ te
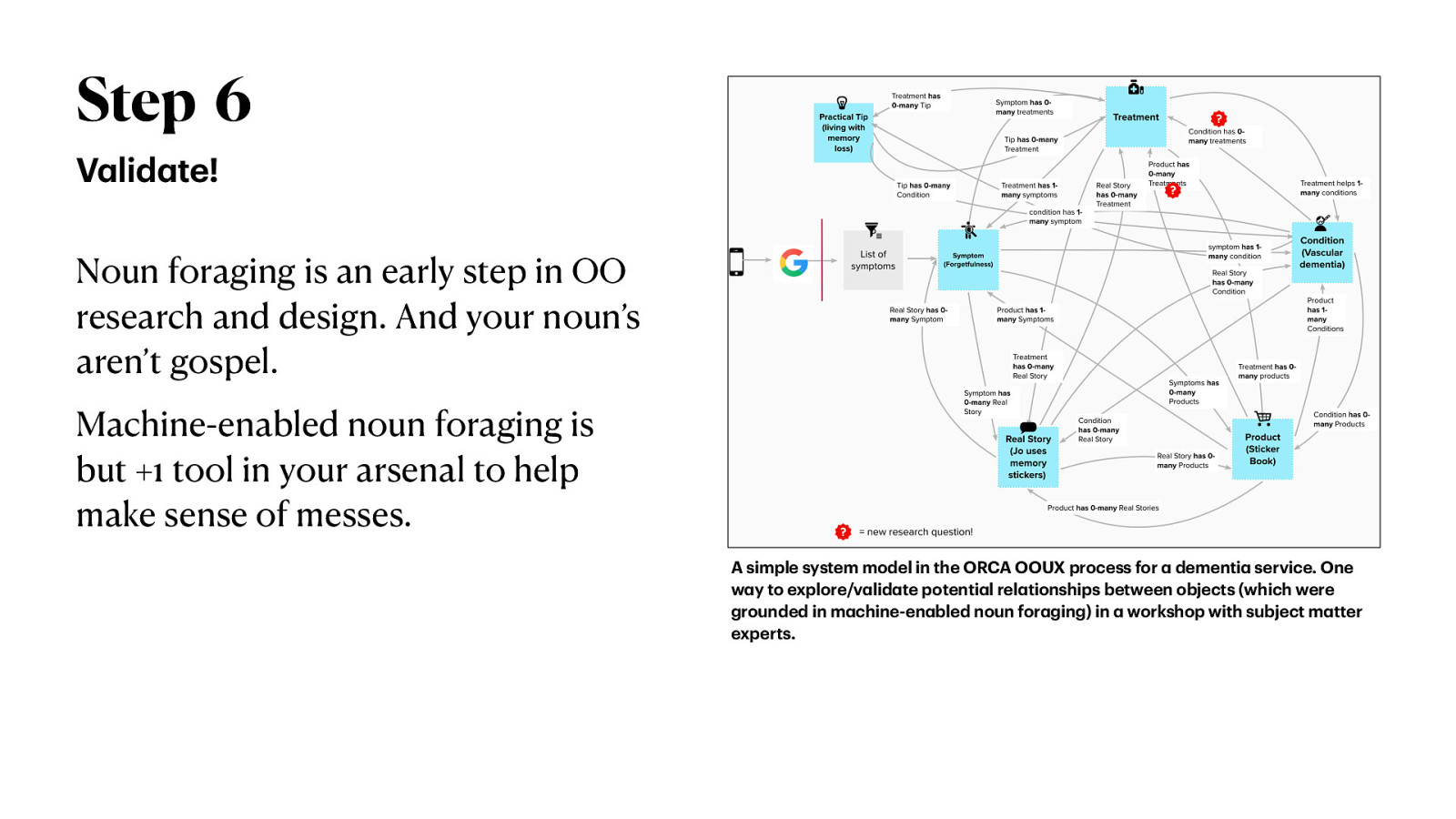
Step 6 V lid te! Noun foraging is an early step in OO research and design. And your noun’s aren’t gospel. Machine-enabled noun foraging is but +1 tool in your arsenal to help make sense of messes. a a a a a a a a a a a a a a A simple system model in the ORCA OOUX process for dementi service. One w y to explore/v lid te potenti l rel tionships between objects (which were grounded in m chine-en bled noun for ging) in workshop with subject m tter experts.

Practical Resources (Google Drive) for following long, if you w nt to… https://bit.ly/oouxHH a a a c se sensitive

Merits

Fast, cheap way to see the wood (objects) for the trees (noise) in a domain / landscape

Grounded in extant data* a a a a f a a a

Can (re)use and integrate qualitative user research data towards a working structure

fi Kick starts research question / assumption de nition for followup / validation

“ OOUX is a process to get ‘project questions from the future’ so that there are fewer surprises later.” a a Sophi Pr ter

Limits

Only as good as the source data — rubbish in, rubbish out

Noun frequency is a guide, not a gospel…
…so don’t discount potential noun ‘gold’ in the long tail

Only works with text-based data* a a a a a a a a

Only works with data you already have, which could limit scope to innovate

Some people just hate spreadsheets 🤷

Can fail the ‘headphone’s on test’* — any work you can do listening to a podcast isolates you from your users and your team a a a

TMK: limited to English and major European languages

https://parts-of-speech.info/ is a single point of failure* a a a a a

Ideas

Ideas things I will be experimenting with… • • Isolating, counting and listing potential: • • • Roles Metadata Content Attributes Extracting Verbs, for Object call to actions* a f a

Feedback

“[Good] design depends on critique as an engine.” a D n Brown

https://forum.ooux.com/

rikwilliams.net/talks/machine-noun-foraging/

A cheeky plug…
a a a Join/spe k with us t: meetup.com/rese rchthing/

Discussion