

The project I present is called boxes and glue and is named after TeXs model of joining rectangular areas together with flexible width.
This presentation is aimed at developers. But I hope that even if you are not a developer yourself, there are still some interesting slides for you.
Before I show the Why and the How in detail, I try to give a short overview of boxes and glue.
So, what is boxes and glue?
boxes and glue is a collection of software libraries therefore it is is not a ready to run program such as TeX.
The library is written in the Go programming language
The attempt to bring TEX’s superb typesetting quality to a modern environment and available under an Open source license
To explain the reasoning why I work on boxes and glue, I have to go back a bit. I am self employed and earn my money producing product catalogs, data sheets and other documents in an unattended workflow using my own software called the speedata Publisher that I have presented here I think It was two years ago.
The speedata Publisher is based on LuaTeX. LuaTeX is used a typesetting backend and my software arranges the visible elements on the pages depending on the provided data and layout instructions.
There are a few example here on this slide and also on my home page.
A PDF page consists of many little items such as glyphs, rules, images, coloured areas and other rectangle shaped things that can be joined together in a horizontal or a vertical box which themselves can be placed in boxes, until there is one big box that represents the page. All the things and rectangles are called nodes in TeX.
Now with LuaTeX you can jump into the Lua mode which allows you do to anything that could be done from the TeX side, just with a different interface.
So for example to create a glyph output from Lua you have to create a new node of the glyph type and fill in the fields. The font has to be loaded in advance to get the glyph dimensions.
Just as an example how to create a horizontal box from this glyph node, the code is shown here. The real code that has to be used is of course much more complicated.
This looks a bit tedious and compared to TeXs input, it really is. but with enough abstraction it is quite doable. This is the way you assemble pages in LuaTeX
Contrary to what many believe, LuaTeX is vey, very fast. On my rather new macBook with the Apple Silicon chip, LuaTeX creates about 500 pages per second.
LuaTeX has all features of TeX, but is better programmable. This of course is highly subjective, but I don’t like TeXs input language very much.
It is very flexible, you can create almost any PDF code you want to comply with a huge range of PDF standards
And LuaTeX comes with harfbuzz, a text shaping library. harfbuzz loads a font and turns a series of characters into a list of glyph ids from the font. This is trivial for a single letter such as A, but it comes in handy when you have complex ligatures, non-western scripts such as Arabic where glyph shape changes depending on the position of the character in a word and it also interprets OpenType features. So harfbuzz is a very valuable library.
The talk is not just about praising LuaTeX. LuaTeX has in my opinion a lot of shortcomings
These limitations hit my daily work more and more so I am thinking about re-implementing TeX for quite a long time now.
A good thing about TeX is being open source and well documented. You can download the documented source code or get Knuth’s book called Computers and typesetting B and study TeX’s source code.
There has been a re-implemation of TeX before called NTS, which was written in Java. But as far as I know, that has never taken off to be used in the real world. There was a project called extex which took the NTS code, but this also was abandoned.
I see three possibilities to re-implement TeX and bring it into a modern environment:
The first is to go from the pascal code in the book and translate it one by one into a modern environment. But this would still be TeX, output DVI and would not load OpenType fonts.
The second way would be to take the LuaTeX code and translate it or use some automated tool (a transpiler) to create code for example for the Go programming language. But there are still a lot of dependencies on C libraries and the code would not become modular automatically.
The last option is the one I take. It is to re implement the system by looking at what needs to be done and not how it is done. The footnote here is that I do limit myself to the application I have and I will just port a subset of the current implementation of LuaTeX.
Now when I think of re-implementing TeX, I have to take into account the compatibility with TeX. Take for example this function from the TeX source code to calculate the badness when for example a line of text in a paragraph has to be stretched to a given horizontal size.
It should be obvious what it does, right? Well, it wasn’t to me and I can show you the formula that it implements.
(formula)
In a modern programming language this could be written like the one line code.
So the question that I have to answer is how compatible I’d like to be with the original Knuth TeX. The code to the left computes only 1095 different values but is probably very fast but also entirely incomprehensible. Since my goal is to be only similar to TeX but not exactly alike, I will take the one-line calculation of the badness which will not give exactly the same results.
So when I write everything from scratch, I have to take a close look which parts of TeX, or which algorithms in TeX I re-implement
From my point of view the most important algorithms in TeX are
These algorithms are very well documented, very clever but not rocket science so it is possible to re-implement those.
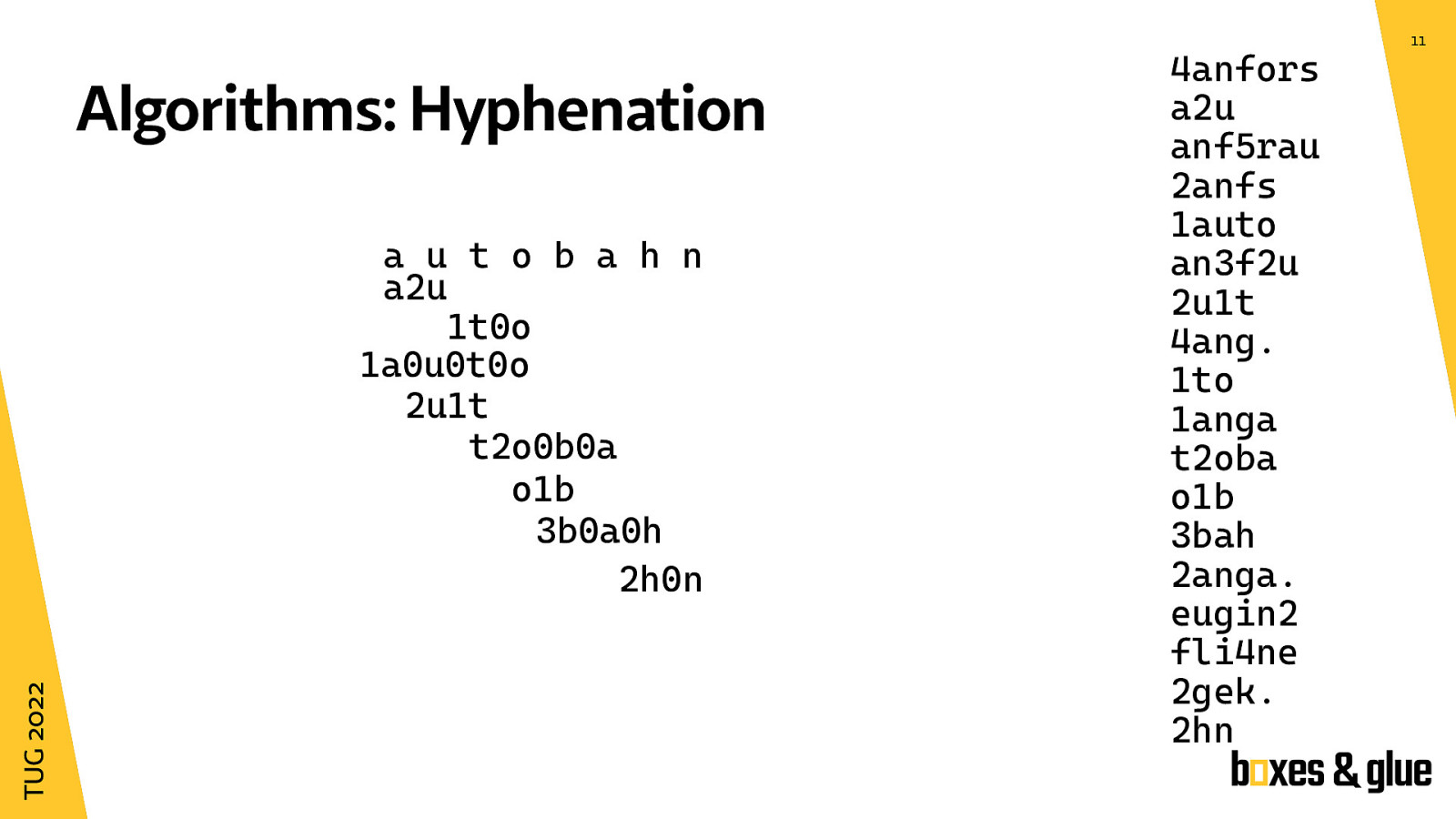
I’d like to show the cleverness of one of these algorithms, the hyphenation algorithm to split word into smaller parts. The starting point is a list of hyphenation patterns.
I am not going into detail how this list is created, but it is a mixture of automatic extraction from dictionaries and lots of manual labour.
On the right hand side there is a small excerpt of the german hyphenation pattern file which has about 25000 entries. Each entry consists of letters and numbers and dots wich match the start or end of a word.
Now we take a word to hyphenate and insert spaces. You will see why on the next slides.
We go through each entry in the pattern list and try to match each pattern to the word.
The second pattern in the list matches, because you can write it like this (next slide) below the word where each letter is in the correct position.
Here you can see how the algorithm decides how the pattern matches the input word.
When there is no number between two letters, like the pattern marked here, a zero is assumed to be there.
( A few slides skipped)
We need to go through the whole list and write down all patterns which match until there is none left.
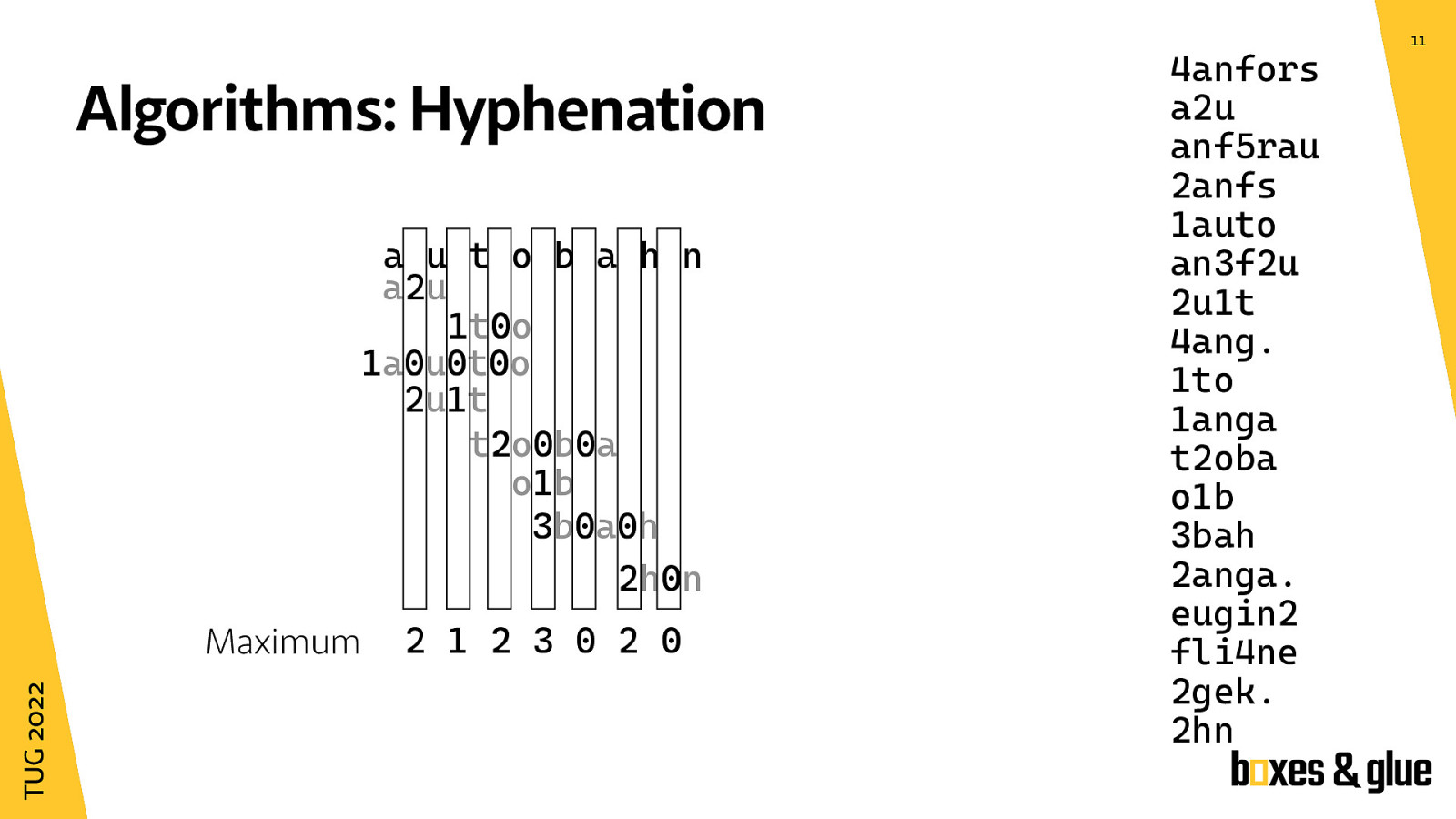
Now what is the next step? We are only interested in the numbers between the letters.
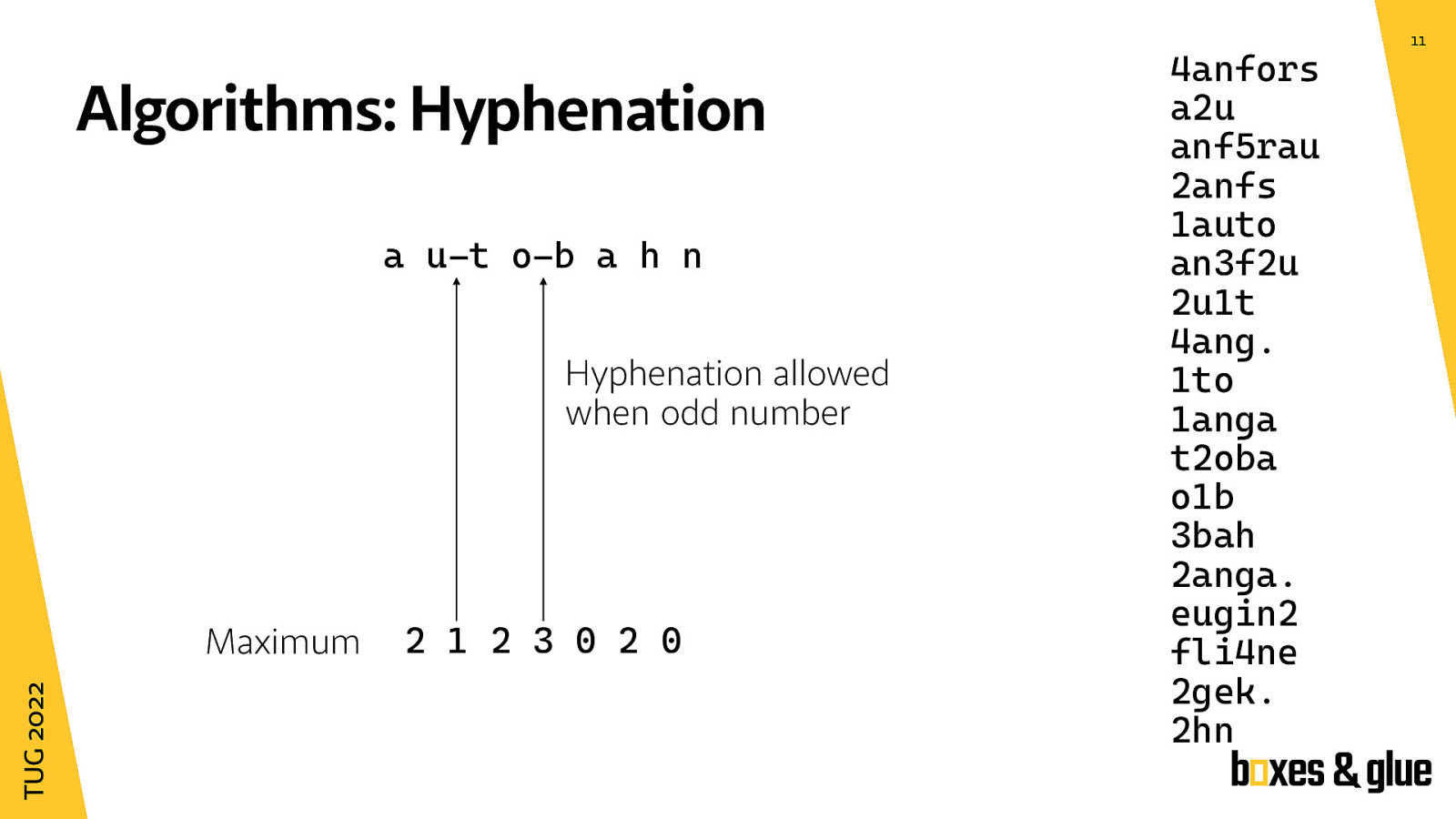
The idea is to get the highest number in each column. Between a and u the maximum is 2, between u and t the maximum is 1 and so on.
Now an odd number means a valid hyphenation point where as even numbers mark unbreakable parts of the word
So the algorithm is rather simple and can only return a signal where hyphenation is allowed or is not allowed but has no notation of a priority or a preference. I will come to this back at the end of the presentation.
The first one is obvious. I want similar output quality as TeX
Boxes and glue should be as fast as LuaTeX
TeXs internal data structures which I’ve mentioned before are a very good representation of typesetting items
With Arabic I mean non-western scripts in general, encoded with unicode and containing perhaps mixed left to right and right to left text
PDF standards such as accessibility should be supported
I also have some non-design goals.
Considering that I want to use the software as a replacement for my catalog software that I currently use,
I don’t need TeX compatibility , only the output should be similar
All 8 bit related stuff and DVI is not considered to be part of boxes and glue. I only need OpenType fonts and PDF
The input language is not needed for my purposes.
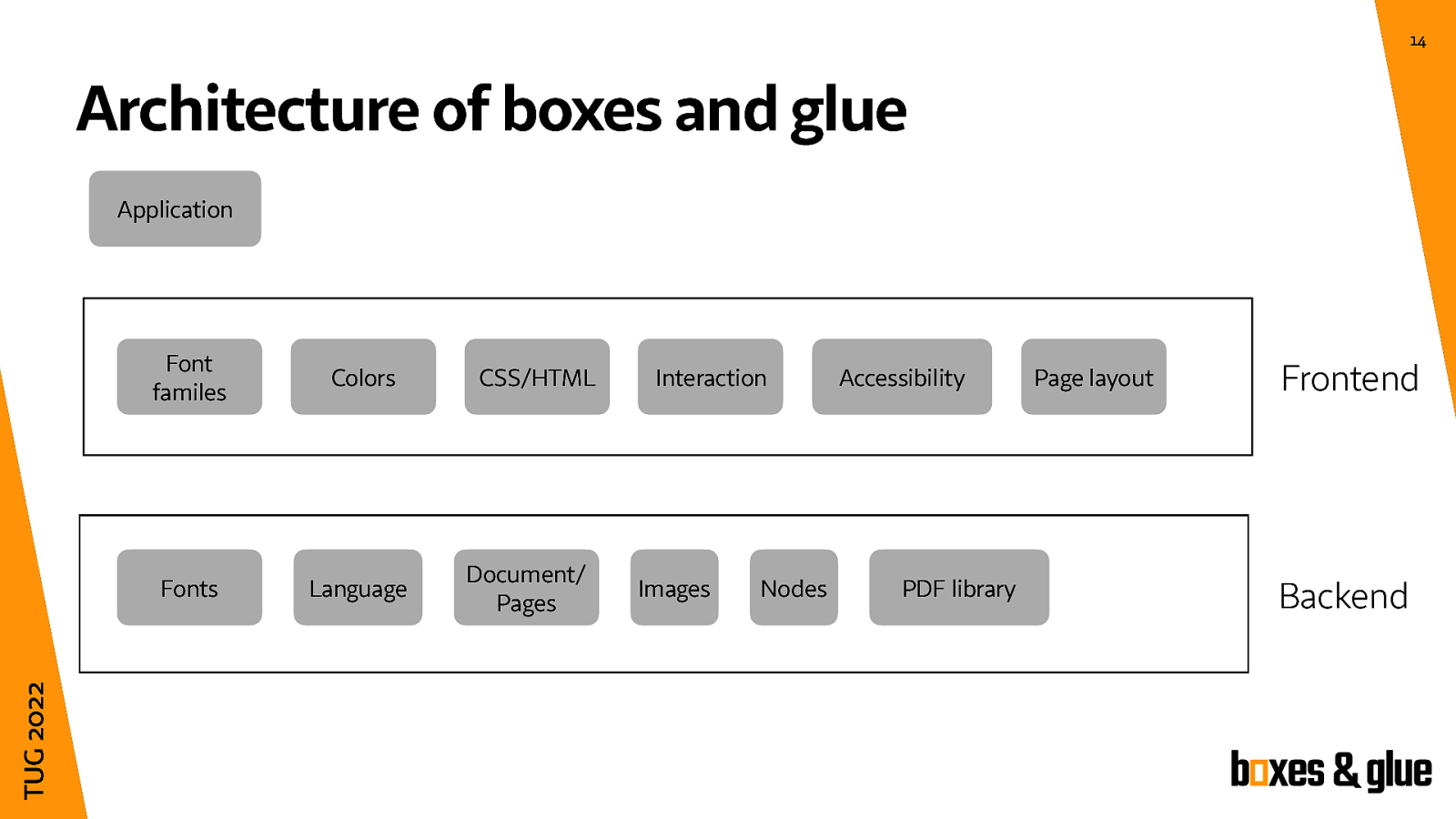
So how is the library organised? Actually it is split into two parts, a backend with some core functionality which is absolutely necessary to create PDF documents using TeX algorithms and a nice to have frontend with optional stuff like CSS and HTML parsing, and other nice-to-have code.
And of course, since this is a library, one needs an application to use boxes and glue. I currently experiment a lot like HTML typesetting, because I need this quite often, but my real test case is a new version of the speedata Publisher which runs on boxes and glue, since this is the goal of the whole project.
As an example I tried to break a paragraph into lines with LuaTeX and with boxes and glue. I’ve disabled micro type because this is not implemented yet on my side and the comparison would not be fair.
The paragraphs look similar, (… next slide)
… except for the bottom part. Now I have to find out what causes the difference between the two. But then again I might just say “I don’t care, because I don’t need perfect compatibility with TeX, just a very close visual similarity”.
There is still a lot of things to do.
I think boxes and glue needs proper input language or an application besides my catalog software, but this is for somebody else to do.
A good output routine is needed for easy to use page layout (such as headers, footers and footnotes)
Math typesetting is not on my agenda, but probably very important, too
Fill in the gaps in the manual. It is started and there is sample code, but it is far away from being good and complete
I could go on of course.
There are a lot of things that I have already implemented such as
Fonts and alike and I have include the aforementioned harfbuzz library into boxes and glue. Someone has ported this to Go
PDF output
TeX algorithms (except for math and the input language)
Image inclusion (for PDF, JPEG and PNG)
So I am quite happy about the state of boxes and glue
The next step could be to experiment with the algorithms. For example the hyphenation algorithm that I have shown has no priority of break points, so that would be something to play with. Would the calculated maximum number during the algorithm be a good hint for hyphenation priority?
I have made boxes and glue to be as modular as possible to allow such experiments.
The page break algorithm could be optimised in such a way to take a look across a range of pages and find optimum breaks.
Or the line braking algorithm can be made to render text with different parameters in parallel and take the best result, whatever that is.
Speaking of parallel execution. Modern CPUs have lots of cores which are bored when running TeX, so to speed things up we should use them. Paragraphs can be broken into lines in advance when the parameters are known. A lot of application have very predictive settings for rendering, so there should be a huge potential speed gain.
I would like to close with my conclusion:
TeX is dead, long live TeX.
Of course LaTeX will be still around in the next twenty years, but for my catalog software it becomes more and more realistic to replace LuaTeX with boxes and glue. So in the long run I will still use TeXs algorithm but without TeX.

“Boxes and glue” is a typesetting library written in the Go programming language. The name is based on the model of TeX with the stretchable spaces between the rectangular units.
This presentation is held at the TUG 2022 conference.
The following resources were mentioned during the presentation or are useful additional information.
The main web page of boxes and glue
Boxes and glue’s twitter account






















 for free. You
can too.
for free. You
can too.