A presentation at RTA Summit by Viktor Gamov

Stream, Materialize, Serve Knitting Flawless Pipelines with Kafka, Flink, and Pinot Tim Berglund VP DevRel, Confluent Viktor Gamov Principal Developer Advocate @gamussa | developer.confluent.io | @tlberglund
What is Apache Pinot ? ™ @gamussa | developer.confluent.io | @tlberglund
“Apache Pinot is a real-time distributed OLAP database, designed to serve OLAP workloads on streaming data with extreme low latency and high concurrency.” @gamussa | developer.confluent.io | @tlberglund
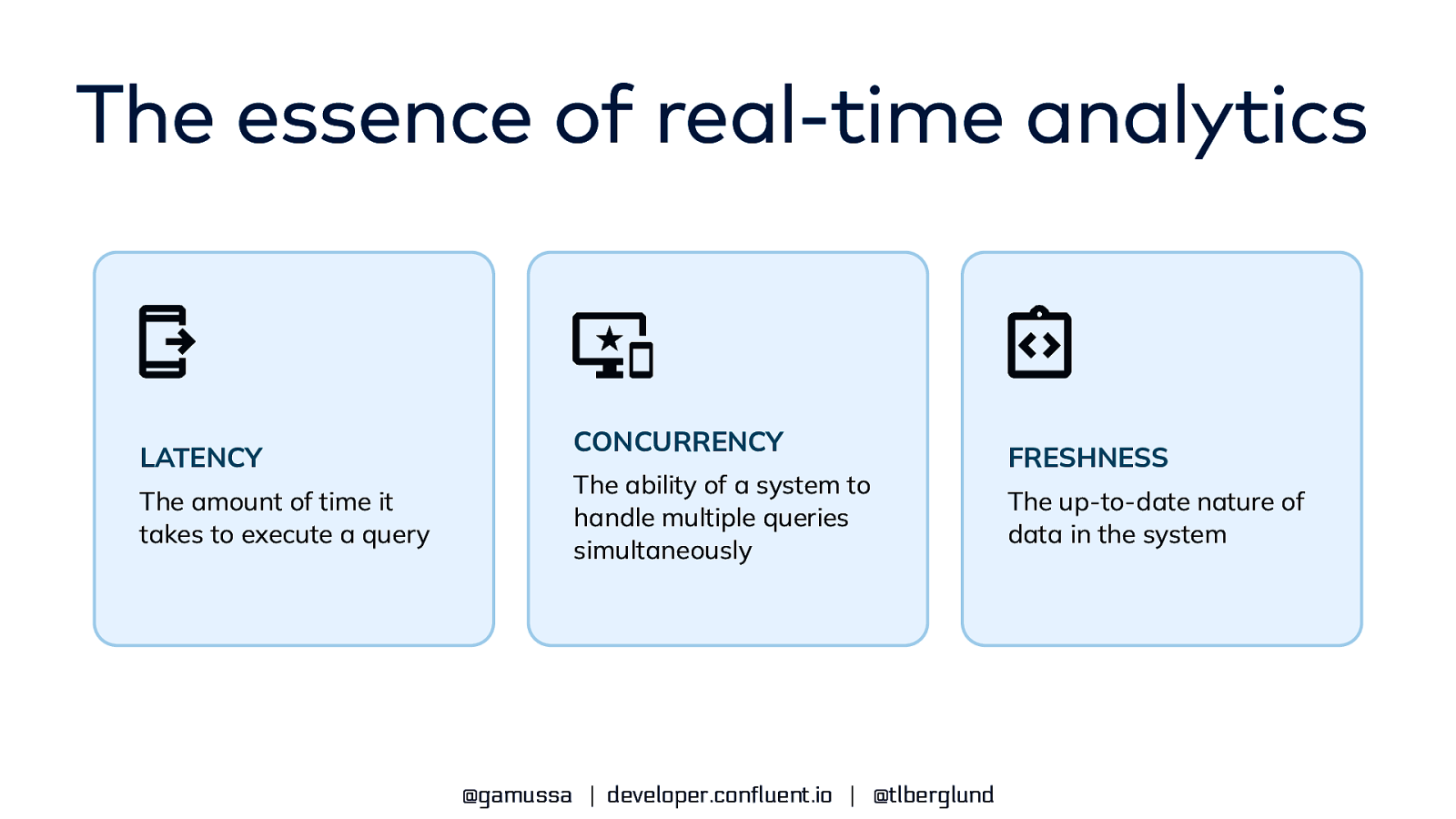
The essence of real-time analytics LATENCY The amount of time it takes to execute a query CONCURRENCY The ability of a system to handle multiple queries simultaneously @gamussa | developer.confluent.io | @tlberglund FRESHNESS The up-to-date nature of data in the system
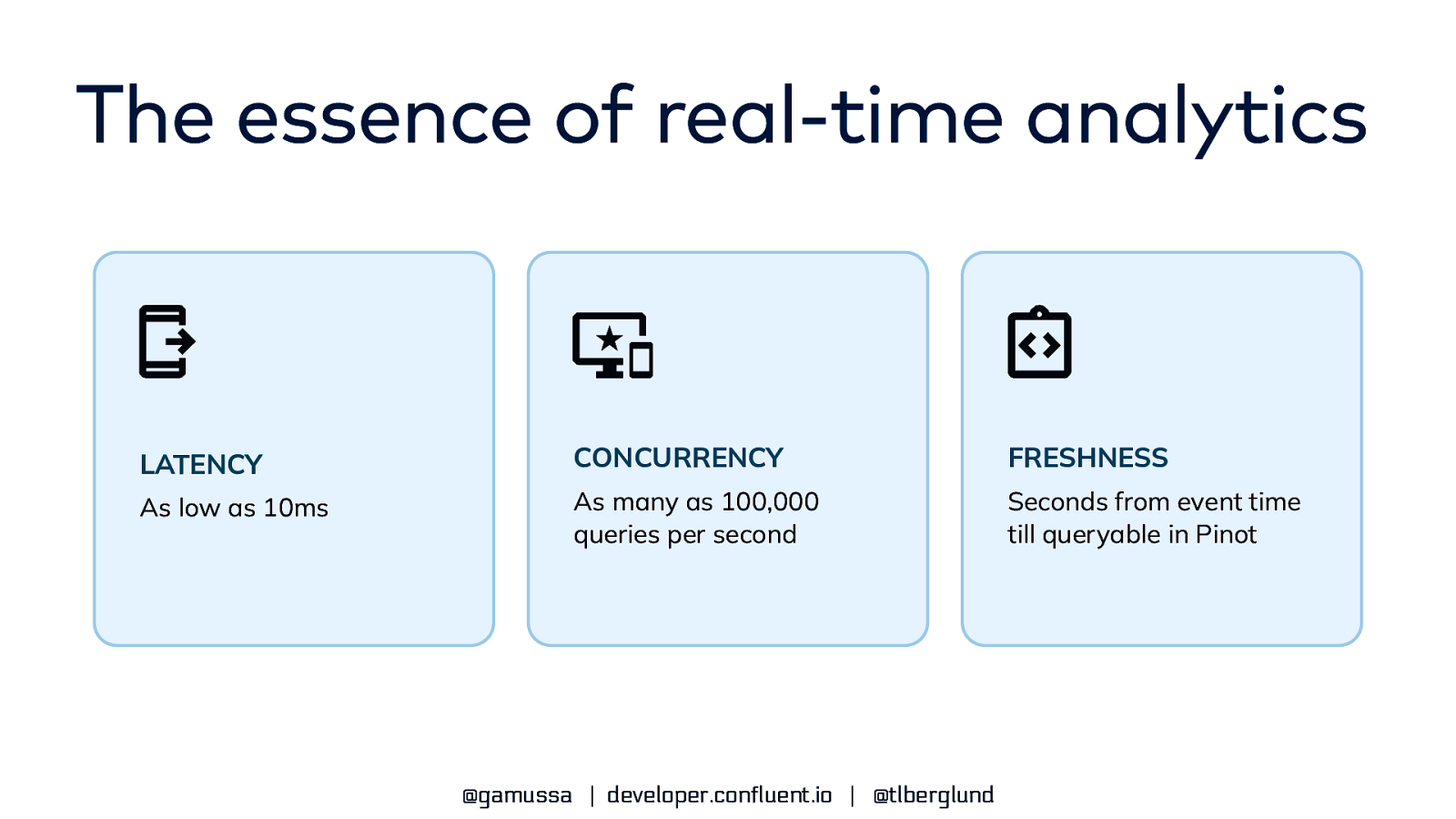
The essence of real-time analytics LATENCY CONCURRENCY FRESHNESS As low as 10ms As many as 100,000 queries per second Seconds from event time till queryable in Pinot @gamussa | developer.confluent.io | @tlberglund
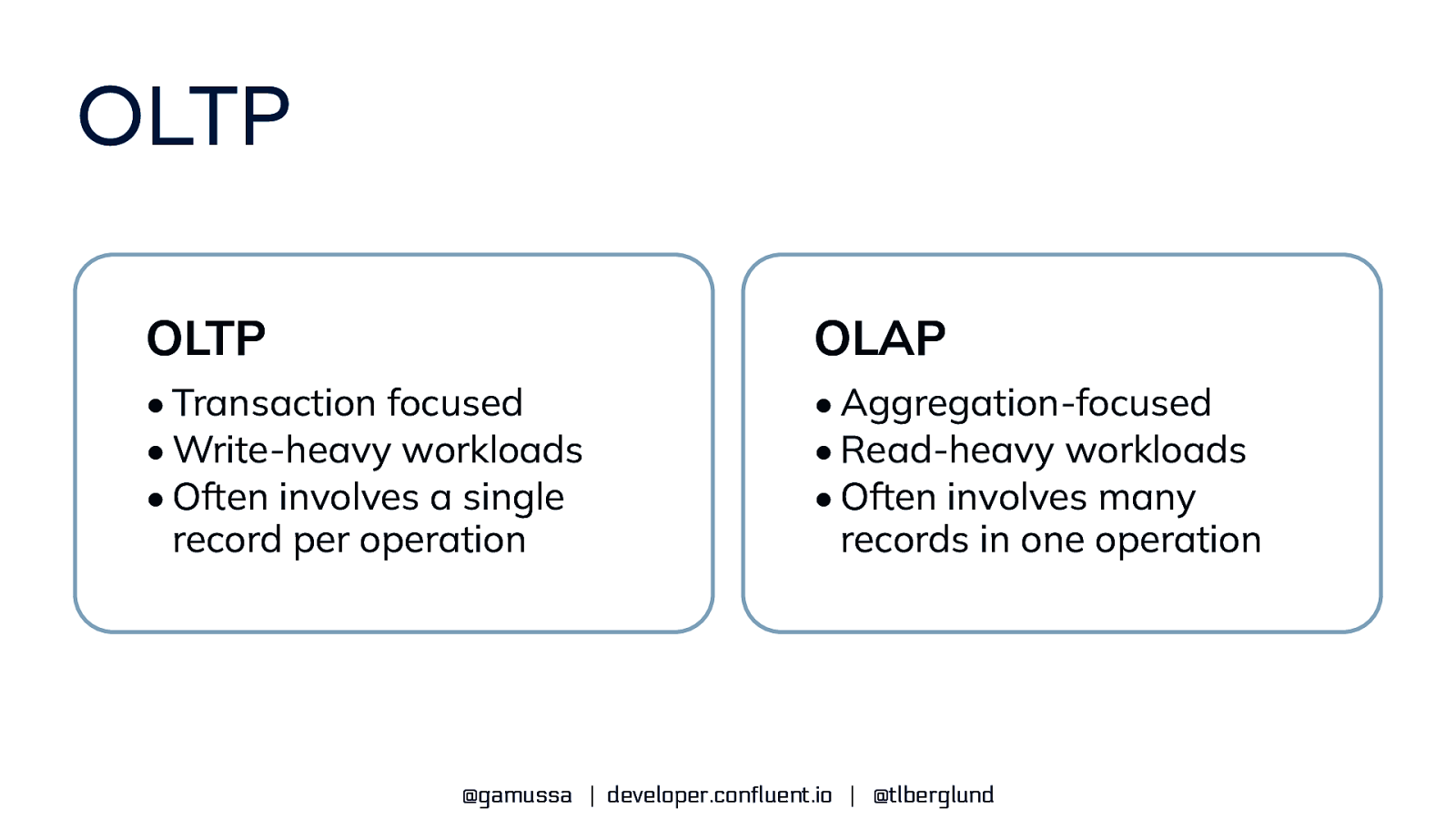
OLTP OLTP OLAP • Transaction focused • Write-heavy workloads • Often involves a single record per operation • Aggregation-focused • Read-heavy workloads • Often involves many records in one operation @gamussa | developer.confluent.io | @tlberglund
Data Model ● Pinot uses the completely familiar tabular data model ● Table creation and schema definition expressed in JSON ● Queries expressed in SQL
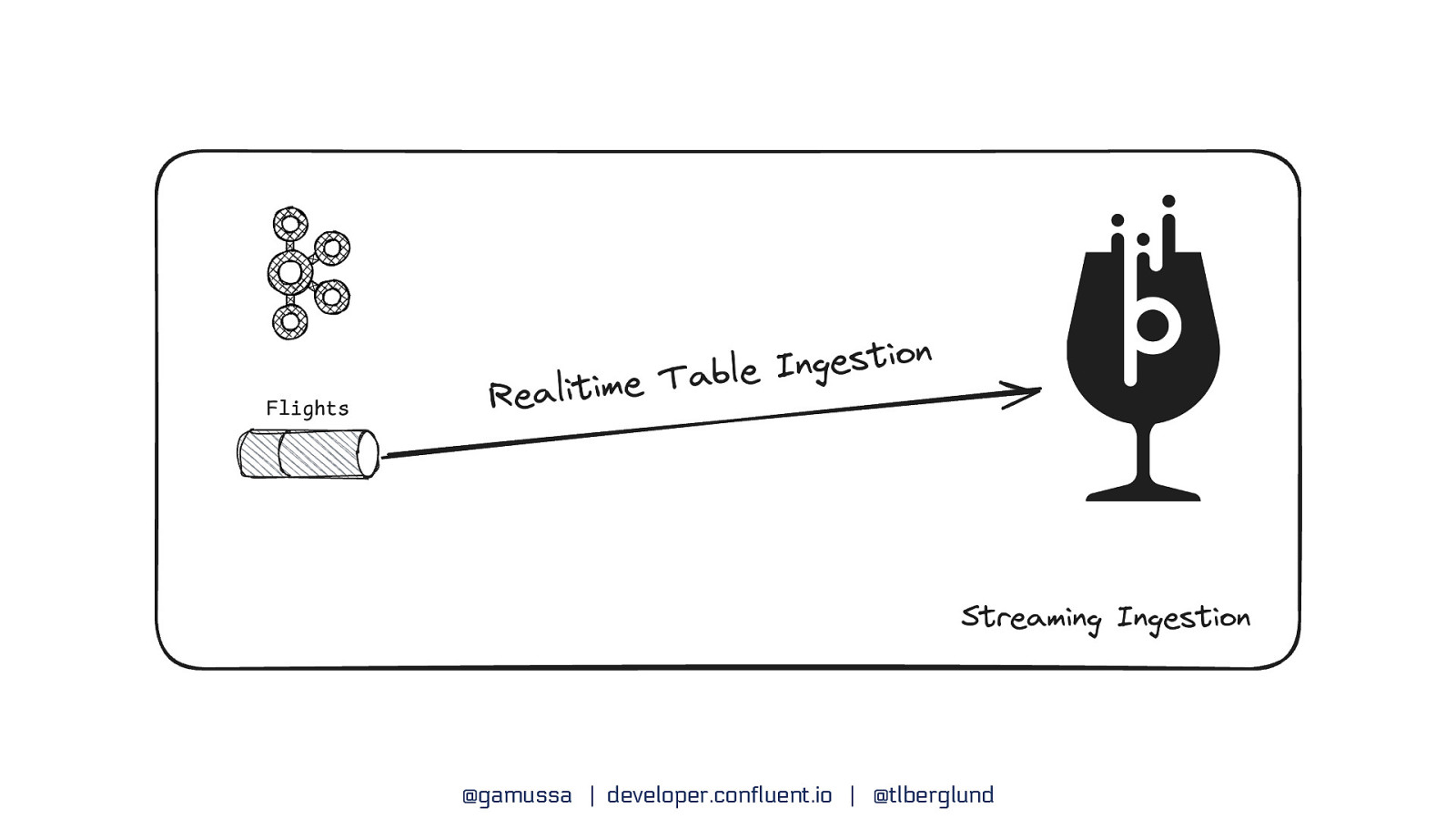
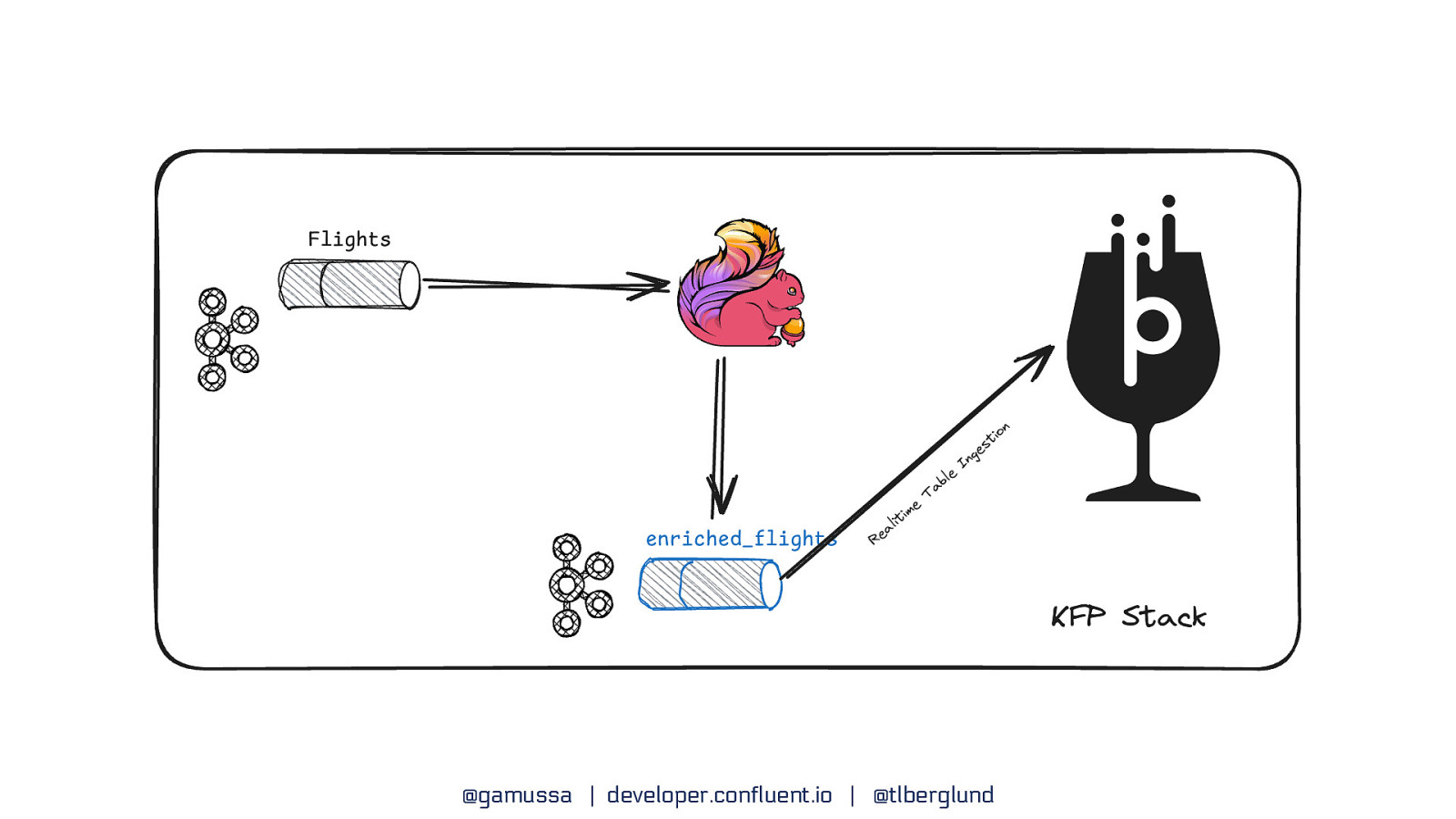
Kafka + Pinot Streaming Ingestion @gamussa | developer.confluent.io | @tlberglund
@gamussa | developer.confluent.io | @tlberglund
Kafka + Flink + Pinot Knitting Flawless Pipelines @gamussa | developer.confluent.io | @tlberglund
Flink 101 @gamussa | developer.confluent.io | @tlberglund
«Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.» @gamussa | developer.confluent.io | @tlberglund
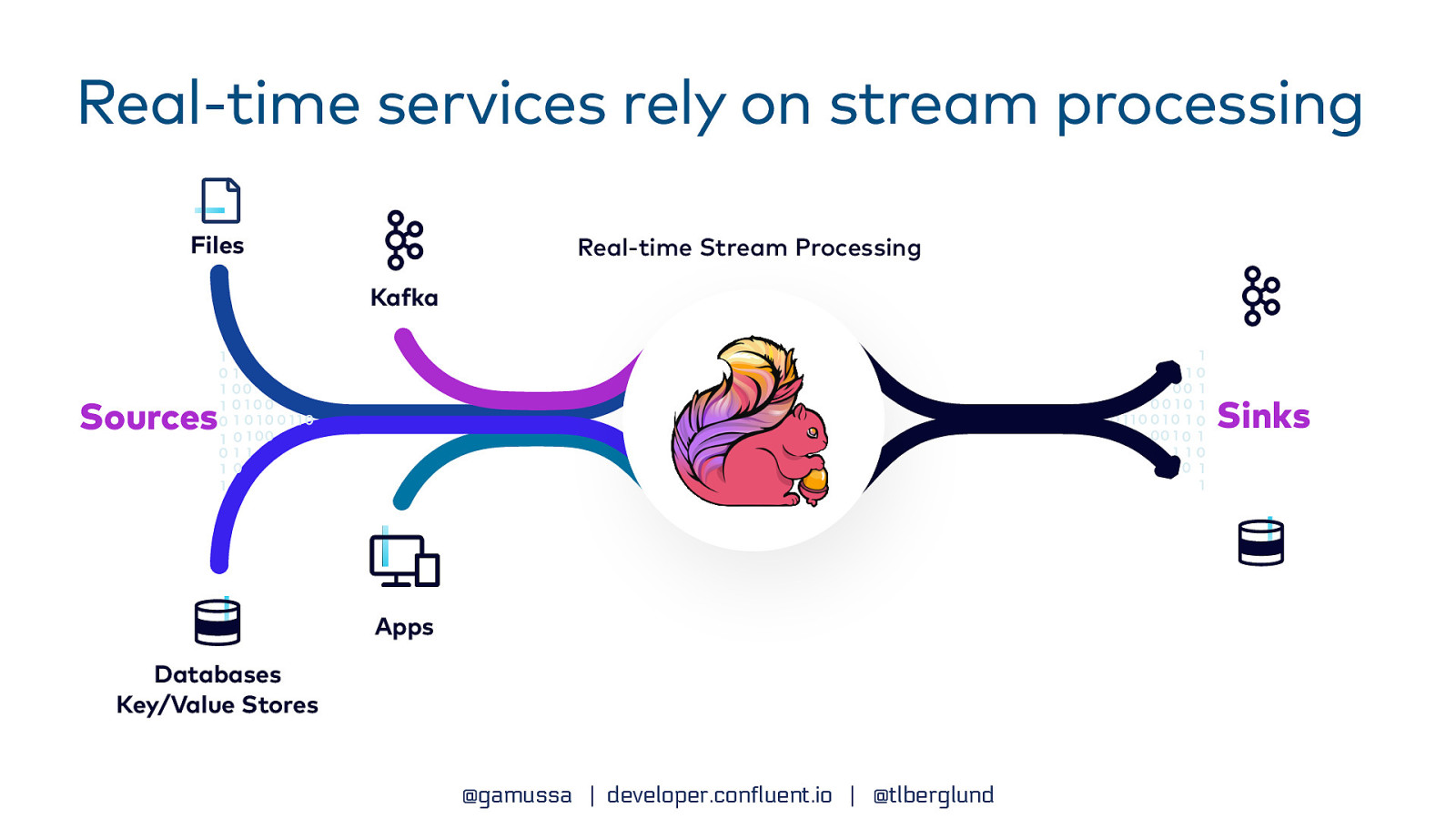
Real-time services rely on stream processing Files Real-time Stream Processing Ka ka Sinks Sources Apps Databases Key/Value Stores f @gamussa | developer.confluent.io | @tlberglund
What is Flink SQL @gamussa | developer.confluent.io | @tlberglund
A standards-compliant SQL engine for processing both batch and streaming data with the scalability, performance, and consistency of Apache Flink @gamussa | developer.confluent.io | @tlberglund
How does Flink work with Kafka? @gamussa | developer.confluent.io | @tlberglund
@gamussa | developer.confluent.io | @tlberglund
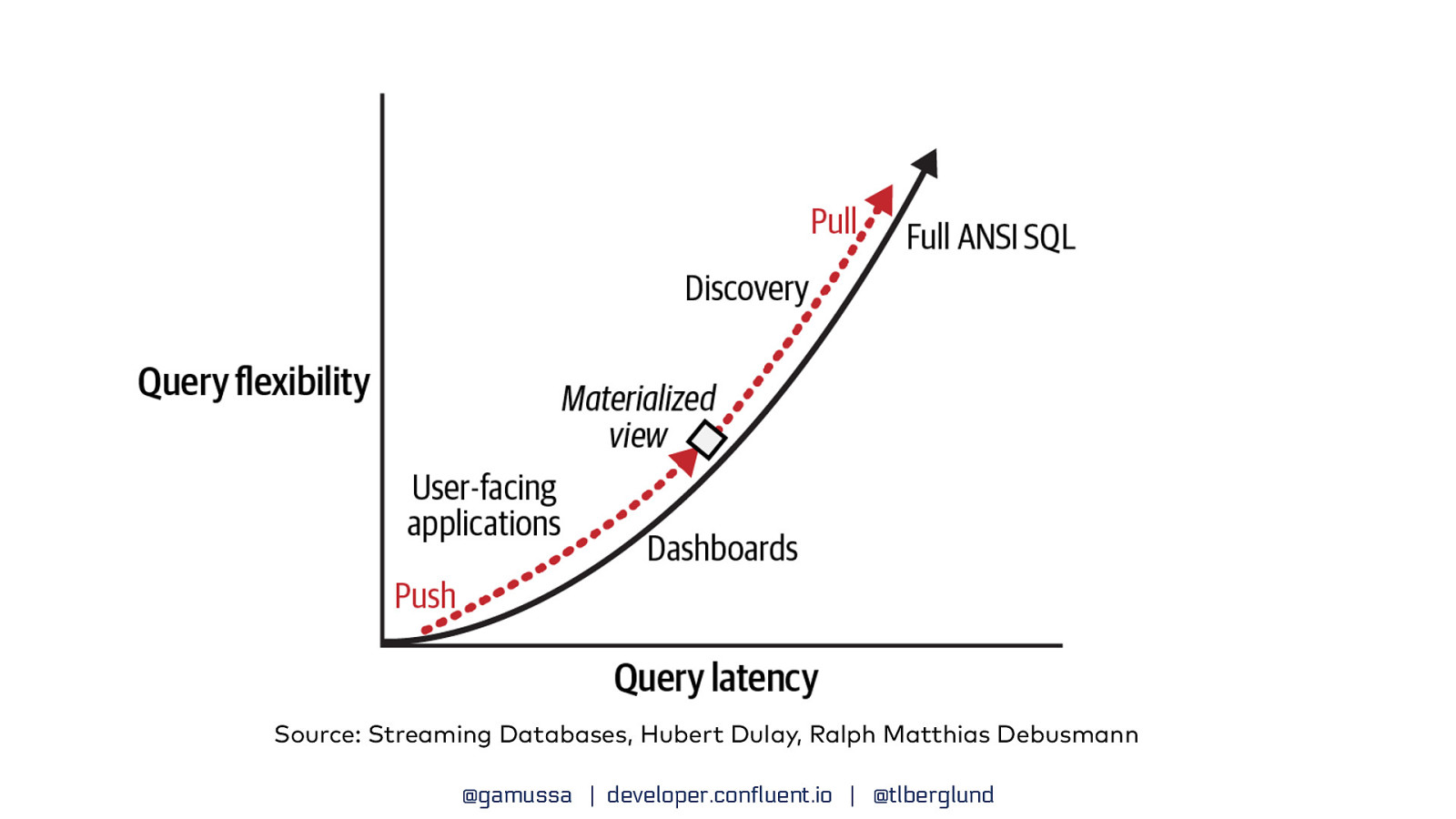
Source: Streaming Databases, Hubert Dulay, Ralph Matthias Debusmann @gamussa | developer.confluent.io | @tlberglund
Check out developer.confluent.io @tlberglund | @gamussa

The success of modern real-time analytics lies in skillfully weaving data technologies together. Much like a master craftsperson selecting the perfect tools for each task, building high-performance analytics requires understanding how Apache Kafka, Apache Flink, and Apache Pinot complement each other to create a seamless data fabric.
In this technical session, we’ll explore the art of knitting these technologies into a cohesive analytics pipeline. We begin with Apache Kafka, which establishes the foundation of our data flow with robust streaming capabilities. We then demonstrate how Apache Flink is our primary processing framework, using its native Table API to create materialized views. This pattern dramatically reduces query latency by pre-computing complex joins. Finally, we’ll show how Apache Pinot completes our pipeline by serving these pre-computed views alongside real-time data, delivering deep sub-second query performance at scale.
Through live demonstrations & hands-on examples, you’ll master the techniques needed to create flawless pipelines. We’ll examine practical implementation patterns for materialized views, strategies for handling late-arriving data, & approaches to maintaining consistency across your streaming architecture. Whether you’re building user-facing analytics dashboards or embedding real-time insights into your applications, you’ll leave equipped with the knowledge to craft high-performance analytics solutions that stand the test of time & scale.