A presentation at jPrime 2024 in in Sofia, Bulgaria by Viktor Gamov

How To Query A Stream? Viktor Gamov, StarTree @gamussa Geecon, Kraków, 2024 @gamussa | @startreedata | @apachepinot
@gamussa | @startreedata | @apachepinot
@gamussa | @startreedata | @apachepinot
Viktor GAMOV Head of Developer Advocacy | StarTree f THE CLOUD CONNECTIVITY COMPANY Twitter X: @gamussa Kong Con idential
Simpler times Monolith
Simpler analytics ETL and CDC
DHW->Hadoop Mobile Era
Data Pipelines Streaming data pipelines and Microservices
LOG
OLTP stream vs OLAP vs. OLTP in Streams OLAP streams
Our Options f • • • • • • Connect/Relational DB Ka ka Streams Streaming SQL Cloud Data Warehouse Data Lake Real-Time OLAP Database
f Ka ka Connect
Connect/RDBMS Broker Broker Broker Cluster Data Source Kafka Connect Kafka Connect Data Sink
` Connect/RDBMS • Suitable for smaller data • Transactional • Familiar to users
f Ka ka Streams
Ka ka Streams (transactional) f • Ingests directly from a topic • KTable • Forms an in-memory key/value store suitable for querying by topic key • Scalable across members of a consumer group • Readable through Interactive Queries
Ka ka Streams (transactional) final KStream<String, String> stream = builder.stream(inputTopic, Consumed.with(stringSerde, stringSerde)); f final KTable<String, String> convertedTable = stream.toTable(Materialized.as(“streamconverted-to-table”));
Ka ka Streams (analytical) • • • • • Full-featured Java stream processing API Arbitrary streaming computation Can emit new streams (not this talk) KTables queryable by key f Every read pattern requires its own topology • Interactive Queries again
Ka ka Streams (analytical) KTable<String, Long> wordCounts = textLines .flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split(“\W+”))) .groupBy((key, word) -> word) .count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as(“counts-store”)); f wordCounts.toStream().to(“WordsWithCountsTopic”, Produced.with(Serdes.String(), Serdes.Long()));
Streaming SQLs
Streaming SQL • • • • Materialize DeltaStream RisingWave ksqlDB
I love you, little squirrel. Why not Flink?
But this talk is not about you. Why not Flink?
Materialize f • Replacement data warehouse • Integrates with Ka ka, Postgres, dbt • The Materialized View is the central abstraction • Views are persistent and queryable • Postgres wire-compatible • Positioned as an analytics solution
Delta Stream Cloud-native streaming SQL Serverless, BYOC Ka ka, Kinesis integration Materialized views and streaming pipelines • streaming database and streaming analytics f • • • •
Rising Wave f • Distributed SQL Streaming database • Cloud and OSS versions • Implementation of Flink in Rust • Ka ka, Pulsar, Kinesis integrations • Flink+persistent views • Postgres wire-compatible
ksqlDB f • «Streaming Database» • Provides persistent TABLE abstraction • Pull and Push queries • Like Ka kaStreams, but in SQL
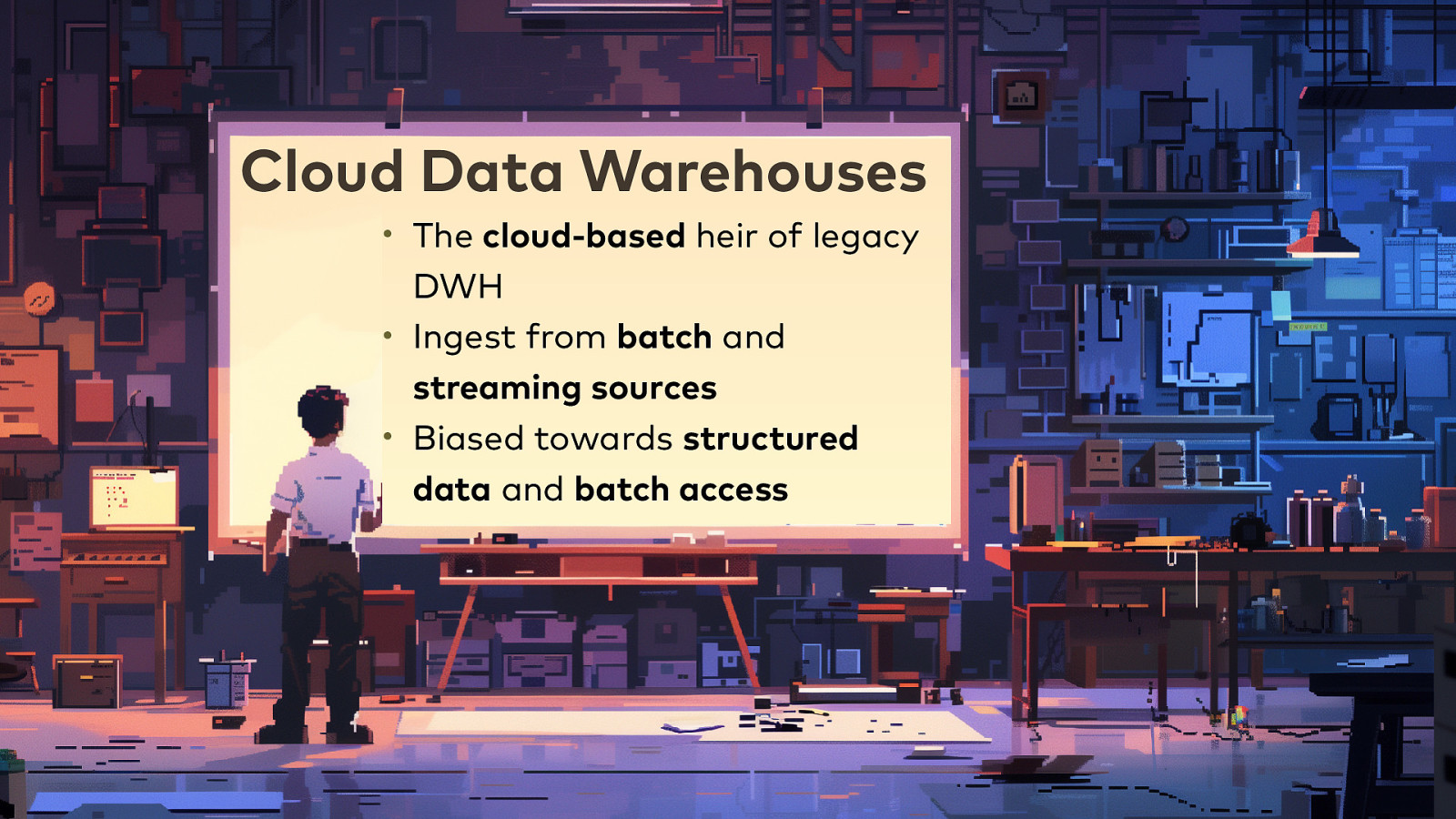
Cloud Data Warehouses
Cloud Data Warehouses
Cloud Data Warehouses • The cloud-based heir of legacy DWH • Ingest from batch and streaming sources • Biased towards structured data and batch access
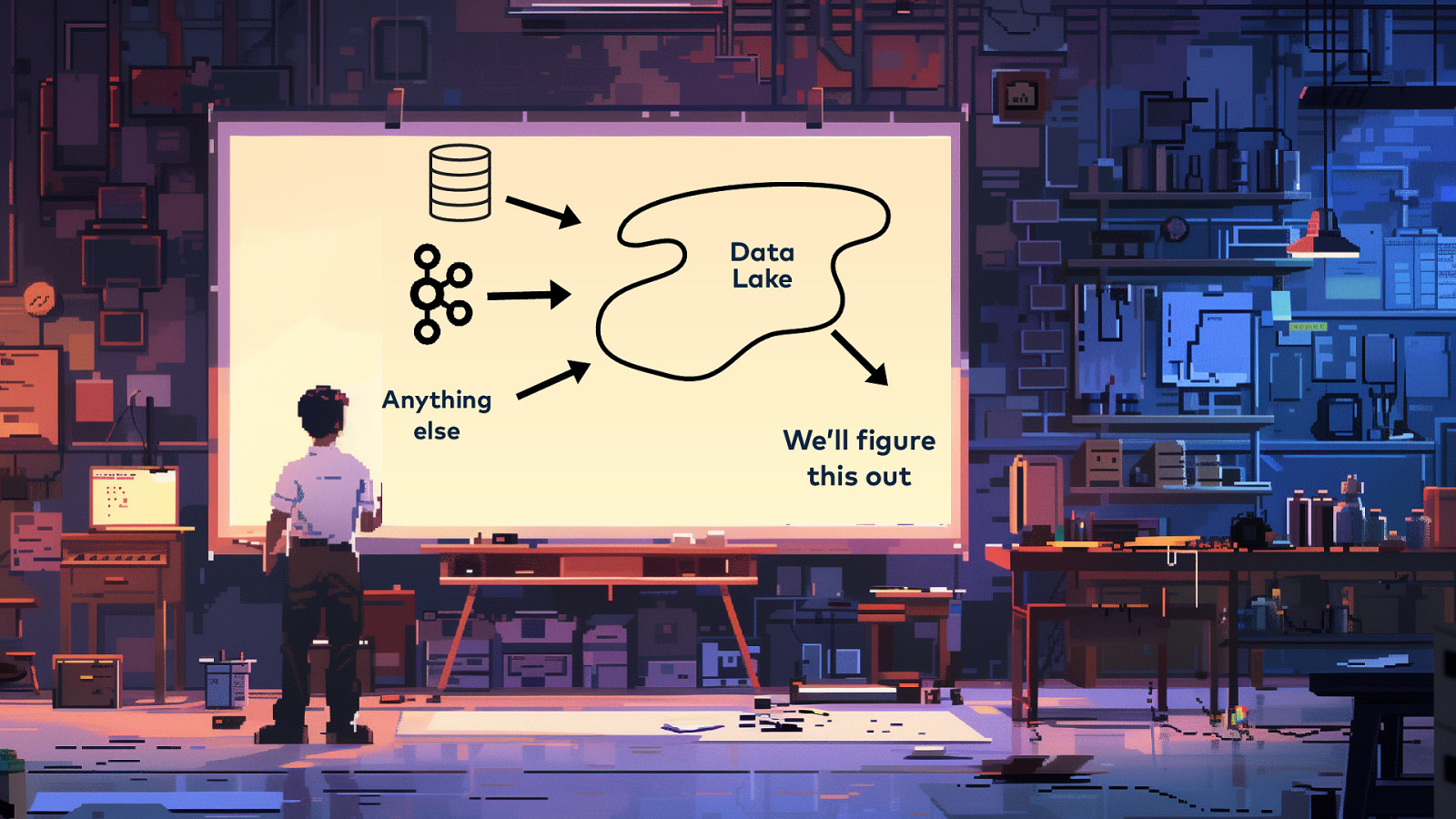
Data Lake
Data Lake f Anything else We’ll igure this out
Data Lakes • • • • • Started as the HDFS cluster Became S3 That didn’t help… ELT vs. ETL Iceberg/Hudi/DeltaLake
Data Lakes f • Storage and compute are radically decoupled • Structure is relatively less important • Reads are slow • Streaming is historically dif icult
Data Lakes f • Storage and compute are radically decoupled • Structure is relatively less important • Reads are slow • Streaming is historically dif icult
Real-Time Analytics Database
Real-Time OLAP f • Designed for high concurrency, low latency queries • Ingests from streaming and batch sources • Intimate integration with Ka ka • Conventional tables and SQL
Real-Time OLAP • Analytics shaped like realtime data • Analytics when users are decision makers
No Solutions Technology Selection only Trade Offs
Sometimes you go with what you know
This is not bad!
Performance Performance
Community/Adoption Community
Differentiated Application Code Area of Exploration Kafka
Need your feedback @gamussa | @startreedata | @apachepinot
Need your feedback It’s Anonymous @gamussa | @startreedata | @apachepinot
For more resources on Apache Pinot: dev.startree.ai Viktor Gamov, StarTree @gamussa

Suppose you have embraced Apache Kafka as the core of your data infrastructure. In that case, you have probably integrated event-driven services to communicate with each other through topics, combined with legacy systems through an ecosystem of connectors, and responded more or less in real-time to things happening in the world outside your software. Immutable logs of events form a more robust backbone than the one-database-to-rule-them-all of your profound monolith past. Your stack is more evolvable, responsive, and easier to work with. However, you might face a challenge now that everything is a stream - how do you query things? Although you may name at least one or two ways off the top of your head, it’s time you think through how to make the choice. In this talk, we’ll explore the solutions currently in use for asking questions about the contents of a topic, including Kafka Streams, the various streaming SQL implementations, your favorite relational database, your favorite data lake, and real-time analytics databases like Apache Pinot. There is no single correct answer to the question, so as responsible builders of systems, we must understand our options and the trade-offs they present to us. You’ll leave this talk even more satisfied that you’ve embraced Kafka as the heart of your system and are ready to deploy the right choice for querying the logs that hold your data.
The following code examples from the presentation can be tried out live.